 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaSynth: Multi-Agent Metadata Generation from Implicit Feedback in Black-Box Systems
Oct 01, 2025Meta titles and descriptions strongly shape engagement in search and recommendation platforms, yet optimizing them remains challenging. Search engine ranking models are black box environments, explicit labels are unavailable, and feedback such as click-through rate (CTR) arrives only post-deployment. Existing template, LLM, and retrieval-augmented approaches either lack diversity, hallucinate attributes, or ignore whether candidate phrasing has historically succeeded in ranking. This leaves a gap in directly leveraging implicit signals from observable outcomes. We introduce MetaSynth, a multi-agent retrieval-augmented generation framework that learns from implicit search feedback. MetaSynth builds an exemplar library from top-ranked results, generates candidate snippets conditioned on both product content and exemplars, and iteratively refines outputs via evaluator-generator loops that enforce relevance, promotional strength, and compliance. On both proprietary e-commerce data and the Amazon Reviews corpus, MetaSynth outperforms strong baselines across NDCG, MRR, and rank metrics. Large-scale A/B tests further demonstrate 10.26% CTR and 7.51% clicks. Beyond metadata, this work contributes a general paradigm for optimizing content in black-box systems using implicit signals.
Spatial Reasoning in Foundation Models: Benchmarking Object-Centric Spatial Understanding
Sep 26, 2025
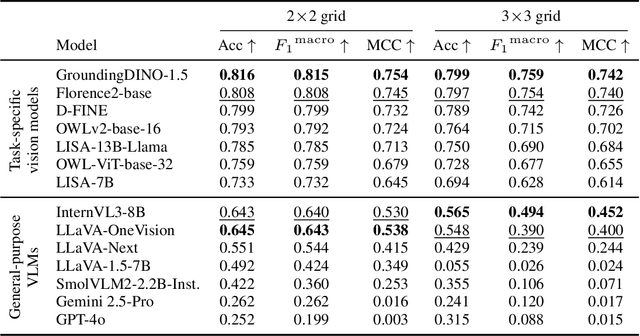

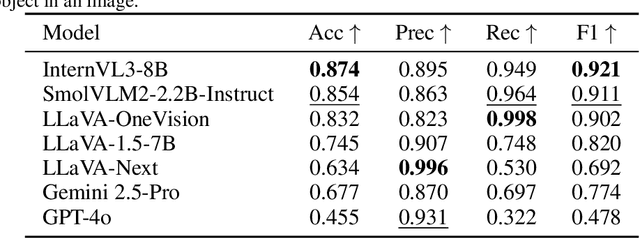
Spatial understanding is a critical capability for vision foundation models. While recent advances in large vision models or vision-language models (VLMs) have expanded recognition capabilities, most benchmarks emphasize localization accuracy rather than whether models capture how objects are arranged and related within a scene. This gap is consequential; effective scene understanding requires not only identifying objects, but reasoning about their relative positions, groupings, and depth. In this paper, we present a systematic benchmark for object-centric spatial reasoning in foundation models. Using a controlled synthetic dataset, we evaluate state-of-the-art vision models (e.g., GroundingDINO, Florence-2, OWLv2) and large VLMs (e.g., InternVL, LLaVA, GPT-4o) across three tasks: spatial localization, spatial reasoning, and downstream retrieval tasks. We find a stable trade-off: detectors such as GroundingDINO and OWLv2 deliver precise boxes with limited relational reasoning, while VLMs like SmolVLM and GPT-4o provide coarse layout cues and fluent captions but struggle with fine-grained spatial context. Our study highlights the gap between localization and true spatial understanding, and pointing toward the need for spatially-aware foundation models in the community.
VL-CLIP: Enhancing Multimodal Recommendations via Visual Grounding and LLM-Augmented CLIP Embeddings
Jul 22, 2025Multimodal learning plays a critical role in e-commerce recommendation platforms today, enabling accurate recommendations and product understanding. However, existing vision-language models, such as CLIP, face key challenges in e-commerce recommendation systems: 1) Weak object-level alignment, where global image embeddings fail to capture fine-grained product attributes, leading to suboptimal retrieval performance; 2) Ambiguous textual representations, where product descriptions often lack contextual clarity, affecting cross-modal matching; and 3) Domain mismatch, as generic vision-language models may not generalize well to e-commerce-specific data. To address these limitations, we propose a framework, VL-CLIP, that enhances CLIP embeddings by integrating Visual Grounding for fine-grained visual understanding and an LLM-based agent for generating enriched text embeddings. Visual Grounding refines image representations by localizing key products, while the LLM agent enhances textual features by disambiguating product descriptions. Our approach significantly improves retrieval accuracy, multimodal retrieval effectiveness, and recommendation quality across tens of millions of items on one of the largest e-commerce platforms in the U.S., increasing CTR by 18.6%, ATC by 15.5%, and GMV by 4.0%. Additional experimental results show that our framework outperforms vision-language models, including CLIP, FashionCLIP, and GCL, in both precision and semantic alignment, demonstrating the potential of combining object-aware visual grounding and LLM-enhanced text representation for robust multimodal recommendations.
Decoding Style: Efficient Fine-Tuning of LLMs for Image-Guided Outfit Recommendation with Preference
Sep 18, 2024



Personalized outfit recommendation remains a complex challenge, demanding both fashion compatibility understanding and trend awareness. This paper presents a novel framework that harnesses the expressive power of large language models (LLMs) for this task, mitigating their "black box" and static nature through fine-tuning and direct feedback integration. We bridge the item visual-textual gap in items descriptions by employing image captioning with a Multimodal Large Language Model (MLLM). This enables the LLM to extract style and color characteristics from human-curated fashion images, forming the basis for personalized recommendations. The LLM is efficiently fine-tuned on the open-source Polyvore dataset of curated fashion images, optimizing its ability to recommend stylish outfits. A direct preference mechanism using negative examples is employed to enhance the LLM's decision-making process. This creates a self-enhancing AI feedback loop that continuously refines recommendations in line with seasonal fashion trends. Our framework is evaluated on the Polyvore dataset, demonstrating its effectiveness in two key tasks: fill-in-the-blank, and complementary item retrieval. These evaluations underline the framework's ability to generate stylish, trend-aligned outfit suggestions, continuously improving through direct feedback. The evaluation results demonstrated that our proposed framework significantly outperforms the base LLM, creating more cohesive outfits. The improved performance in these tasks underscores the proposed framework's potential to enhance the shopping experience with accurate suggestions, proving its effectiveness over the vanilla LLM based outfit generation.
Dynamic Decision Making in Engineering System Design: A Deep Q-Learning Approach
Dec 28, 2023Engineering system design, viewed as a decision-making process, faces challenges due to complexity and uncertainty. In this paper, we present a framework proposing the use of the Deep Q-learning algorithm to optimize the design of engineering systems. We outline a step-by-step framework for optimizing engineering system designs. The goal is to find policies that maximize the output of a simulation model given multiple sources of uncertainties. The proposed algorithm handles linear and non-linear multi-stage stochastic problems, where decision variables are discrete, and the objective function and constraints are assessed via a Monte Carlo simulation. We demonstrate the effectiveness of our proposed framework by solving two engineering system design problems in the presence of multiple uncertainties, such as price and demand.
GNN-GMVO: Graph Neural Networks for Optimizing Gross Merchandise Value in Similar Item Recommendation
Oct 26, 2023



Similar item recommendation is a critical task in the e-Commerce industry, which helps customers explore similar and relevant alternatives based on their interested products. Despite the traditional machine learning models, Graph Neural Networks (GNNs), by design, can understand complex relations like similarity between products. However, in contrast to their wide usage in retrieval tasks and their focus on optimizing the relevance, the current GNN architectures are not tailored toward maximizing revenue-related objectives such as Gross Merchandise Value (GMV), which is one of the major business metrics for e-Commerce companies. In addition, defining accurate edge relations in GNNs is non-trivial in large-scale e-Commerce systems, due to the heterogeneity nature of the item-item relationships. This work aims to address these issues by designing a new GNN architecture called GNN-GMVO (Graph Neural Network - Gross Merchandise Value Optimizer). This model directly optimizes GMV while considering the complex relations between items. In addition, we propose a customized edge construction method to tailor the model toward similar item recommendation task and alleviate the noisy and complex item-item relations. In our comprehensive experiments on three real-world datasets, we show higher prediction performance and expected GMV for top ranked items recommended by our model when compared with selected state-of-the-art benchmark models.