 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Demographic Factors Improve Text Classification? Revisiting Demographic Adaptation in the Age of Transformers
Oct 13, 2022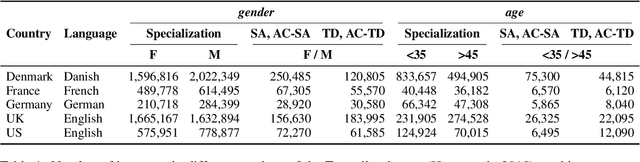

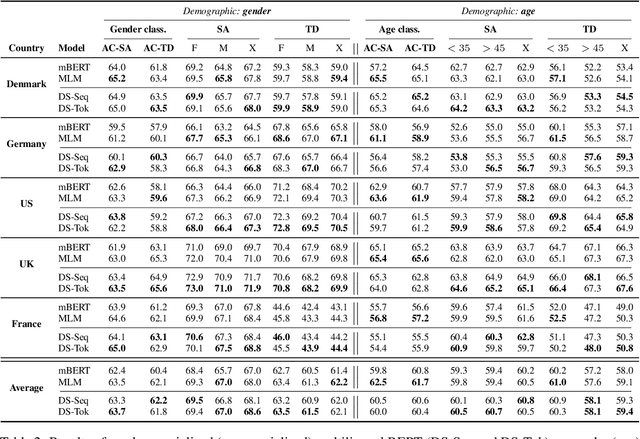
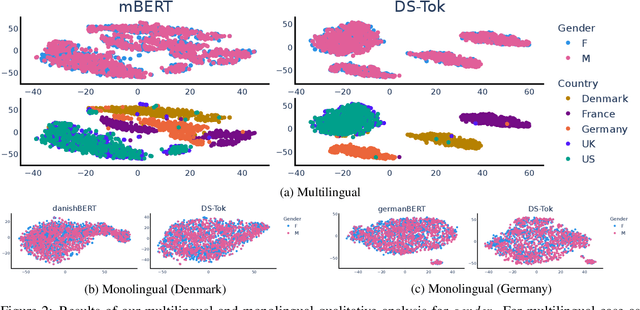
Demographic factors (e.g., gender or age) shape our language. Previous work showed that incorporating demographic factors can consistently improve performance for various NLP tasks with traditional NLP models. In this work, we investigate whether these previous findings still hold with state-of-the-art pretrained Transformer-based language models (PLMs). We use three common specialization methods proven effective for incorporating external knowledge into pretrained Transformers (e.g., domain-specific or geographic knowledge). We adapt the language representations for the demographic dimensions of gender and age, using continuous language modeling and dynamic multi-task learning for adaptation, where we couple language modeling objectives with the prediction of demographic classes. Our results when employing a multilingual PLM show substantial performance gains across four languages (English, German, French, and Danish), which is consistent with the results of previous work. However, controlling for confounding factors -- primarily domain and language proficiency of Transformer-based PLMs -- shows that downstream performance gains from our demographic adaptation do not actually stem from demographic knowledge. Our results indicate that demographic specialization of PLMs, while holding promise for positive societal impact, still represents an unsolved problem for (modern) NLP.
Overview of the SV-Ident 2022 Shared Task on Survey Variable Identification in Social Science Publications
Sep 19, 2022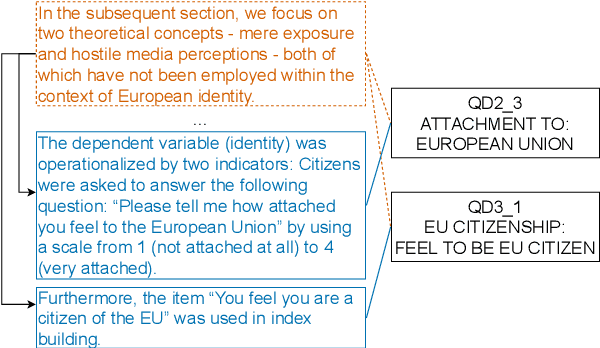
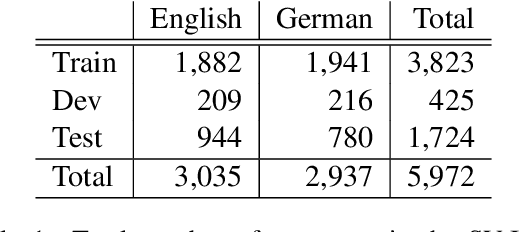

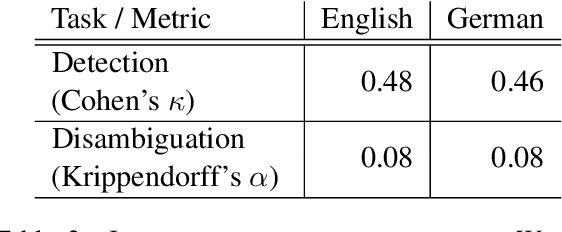
In this paper, we provide an overview of the SV-Ident shared task as part of the 3rd Workshop on Scholarly Document Processing (SDP) at COLING 2022. In the shared task, participants were provided with a sentence and a vocabulary of variables, and asked to identify which variables, if any, are mentioned in individual sentences from scholarly documents in full text. Two teams made a total of 9 submissions to the shared task leaderboard. While none of the teams improve on the baseline systems, we still draw insights from their submissions. Furthermore, we provide a detailed evaluation. Data and baselines for our shared task are freely available at https://github.com/vadis-project/sv-ident
Towards Automated Survey Variable Search and Summarization in Social Science Publications
Sep 14, 2022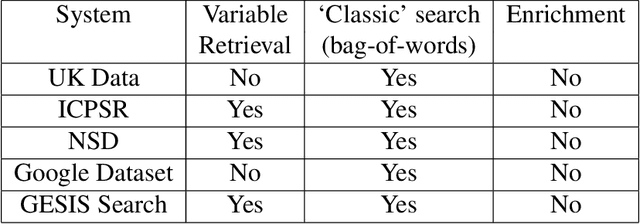
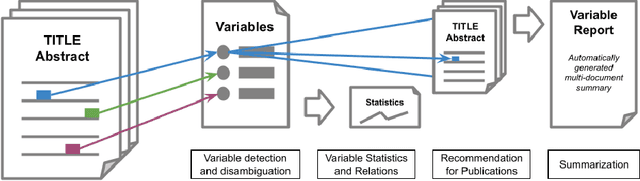
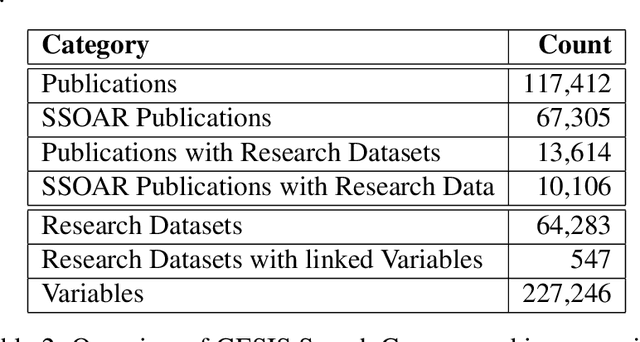
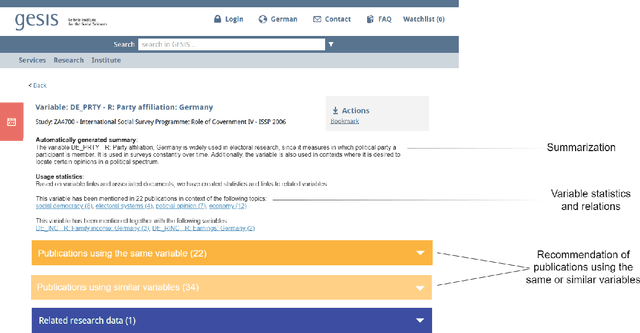
Nowadays there is a growing trend in many scientific disciplines to support researchers by providing enhanced information access through linking of publications and underlying datasets, so as to support research with infrastructure to enhance reproducibility and reusability of research results. In this research note, we present an overview of an ongoing research project, named VADIS (VAriable Detection, Interlinking and Summarization), that aims at developing technology and infrastructure for enhanced information access in the Social Sciences via search and summarization of publications on the basis of automatic identification and indexing of survey variables in text. We provide an overview of the overarching vision underlying our project, its main components, and related challenges, as well as a thorough discussion of how these are meant to address the limitations of current information access systems for publications in the Social Sciences. We show how this goal can be concretely implemented in an end-user system by presenting a search prototype, which is based on user requirements collected from qualitative interviews with empirical Social Science researchers.
On the Limitations of Sociodemographic Adaptation with Transformers
Aug 01, 2022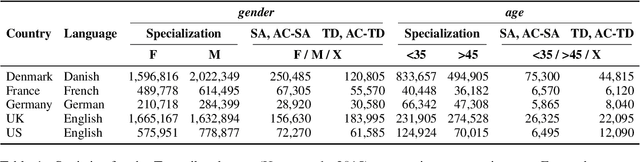
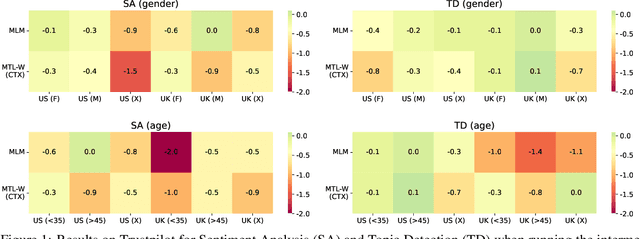
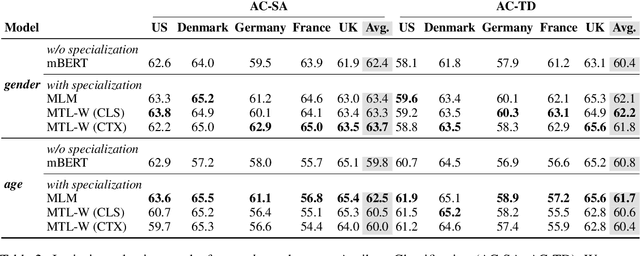
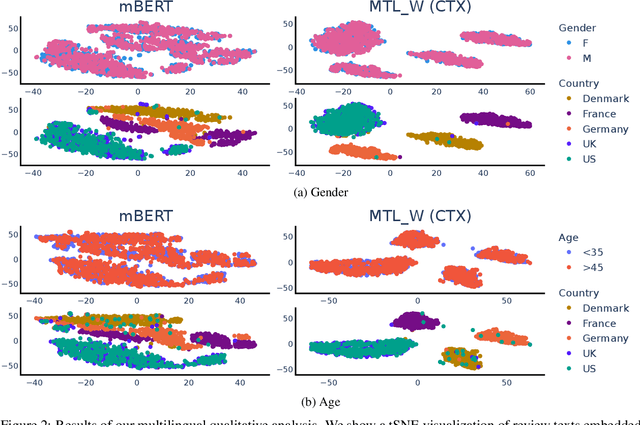
Sociodemographic factors (e.g., gender or age) shape our language. Previous work showed that incorporating specific sociodemographic factors can consistently improve performance for various NLP tasks in traditional NLP models. We investigate whether these previous findings still hold with state-of-the-art pretrained Transformers. We use three common specialization methods proven effective for incorporating external knowledge into pretrained Transformers (e.g., domain-specific or geographic knowledge). We adapt the language representations for the sociodemographic dimensions of gender and age, using continuous language modeling and dynamic multi-task learning for adaptation, where we couple language modeling with the prediction of a sociodemographic class. Our results when employing a multilingual model show substantial performance gains across four languages (English, German, French, and Danish). These findings are in line with the results of previous work and hold promise for successful sociodemographic specialization. However, controlling for confounding factors like domain and language shows that, while sociodemographic adaptation does improve downstream performance, the gains do not always solely stem from sociodemographic knowledge. Our results indicate that sociodemographic specialization, while very important, is still an unresolved problem in NLP.
BabelBERT: Massively Multilingual Transformers Meet a Massively Multilingual Lexical Resource
Aug 01, 2022
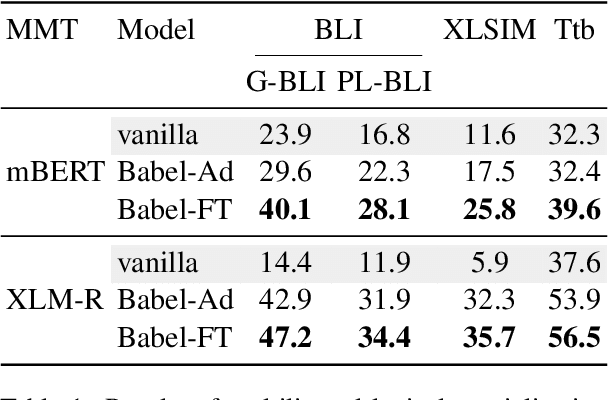
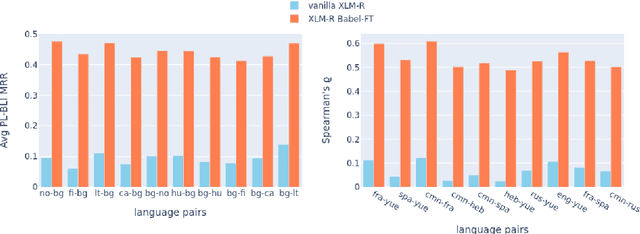
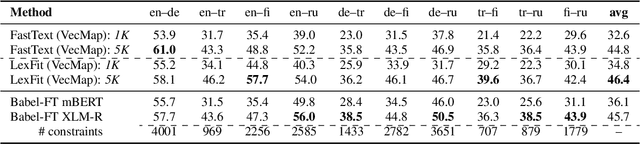
While pretrained language models (PLMs) primarily serve as general purpose text encoders that can be fine-tuned for a wide variety of downstream tasks, recent work has shown that they can also be rewired to produce high-quality word representations (i.e., static word embeddings) and yield good performance in type-level lexical tasks. While existing work primarily focused on lexical specialization of PLMs in monolingual and bilingual settings, in this work we expose massively multilingual transformers (MMTs, e.g., mBERT or XLM-R) to multilingual lexical knowledge at scale, leveraging BabelNet as the readily available rich source of multilingual and cross-lingual type-level lexical knowledge. Concretely, we leverage BabelNet's multilingual synsets to create synonym pairs across $50$ languages and then subject the MMTs (mBERT and XLM-R) to a lexical specialization procedure guided by a contrastive objective. We show that such massively multilingual lexical specialization brings massive gains in two standard cross-lingual lexical tasks, bilingual lexicon induction and cross-lingual word similarity, as well as in cross-lingual sentence retrieval. Crucially, we observe gains for languages unseen in specialization, indicating that the multilingual lexical specialization enables generalization to languages with no lexical constraints. In a series of subsequent controlled experiments, we demonstrate that the pretraining quality of word representations in the MMT for languages involved in specialization has a much larger effect on performance than the linguistic diversity of the set of constraints. Encouragingly, this suggests that lexical tasks involving low-resource languages benefit the most from lexical knowledge of resource-rich languages, generally much more available.
X-SCITLDR: Cross-Lingual Extreme Summarization of Scholarly Documents
May 30, 2022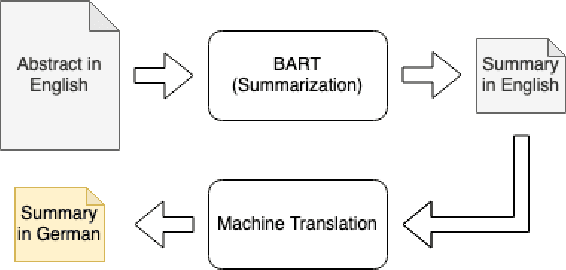

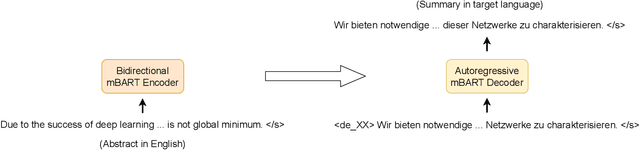

The number of scientific publications nowadays is rapidly increasing, causing information overload for researchers and making it hard for scholars to keep up to date with current trends and lines of work. Consequently, recent work on applying text mining technologies for scholarly publications has investigated the application of automatic text summarization technologies, including extreme summarization, for this domain. However, previous work has concentrated only on monolingual settings, primarily in English. In this paper, we fill this research gap and present an abstractive cross-lingual summarization dataset for four different languages in the scholarly domain, which enables us to train and evaluate models that process English papers and generate summaries in German, Italian, Chinese and Japanese. We present our new X-SCITLDR dataset for multilingual summarization and thoroughly benchmark different models based on a state-of-the-art multilingual pre-trained model, including a two-stage `summarize and translate' approach and a direct cross-lingual model. We additionally explore the benefits of intermediate-stage training using English monolingual summarization and machine translation as intermediate tasks and analyze performance in zero- and few-shot scenarios.
ZusammenQA: Data Augmentation with Specialized Models for Cross-lingual Open-retrieval Question Answering System
May 30, 2022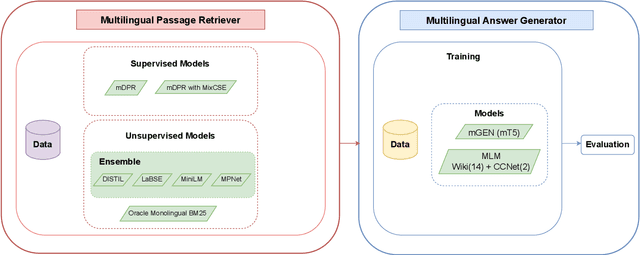



This paper introduces our proposed system for the MIA Shared Task on Cross-lingual Open-retrieval Question Answering (COQA). In this challenging scenario, given an input question the system has to gather evidence documents from a multilingual pool and generate from them an answer in the language of the question. We devised several approaches combining different model variants for three main components: Data Augmentation, Passage Retrieval, and Answer Generation. For passage retrieval, we evaluated the monolingual BM25 ranker against the ensemble of re-rankers based on multilingual pretrained language models (PLMs) and also variants of the shared task baseline, re-training it from scratch using a recently introduced contrastive loss that maintains a strong gradient signal throughout training by means of mixed negative samples. For answer generation, we focused on language- and domain-specialization by means of continued language model (LM) pretraining of existing multilingual encoders. Additionally, for both passage retrieval and answer generation, we augmented the training data provided by the task organizers with automatically generated question-answer pairs created from Wikipedia passages to mitigate the issue of data scarcity, particularly for the low-resource languages for which no training data were provided. Our results show that language- and domain-specialization as well as data augmentation help, especially for low-resource languages.
Multi2WOZ: A Robust Multilingual Dataset and Conversational Pretraining for Task-Oriented Dialog
May 20, 2022
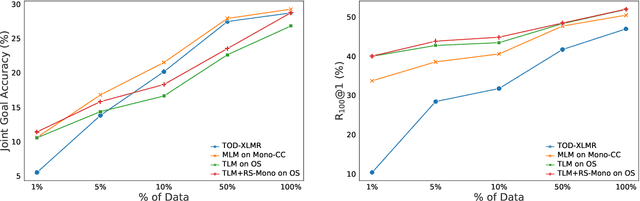

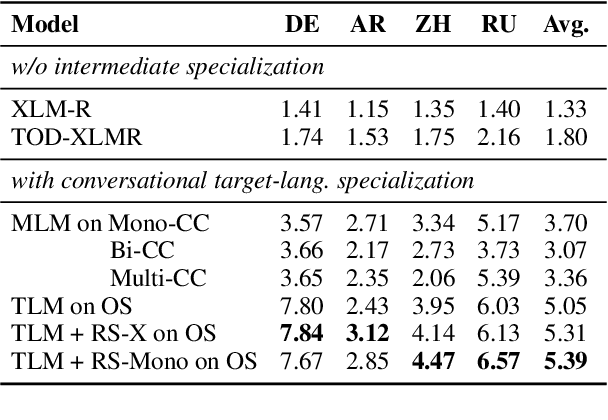
Research on (multi-domain) task-oriented dialog (TOD) has predominantly focused on the English language, primarily due to the shortage of robust TOD datasets in other languages, preventing the systematic investigation of cross-lingual transfer for this crucial NLP application area. In this work, we introduce Multi2WOZ, a new multilingual multi-domain TOD dataset, derived from the well-established English dataset MultiWOZ, that spans four typologically diverse languages: Chinese, German, Arabic, and Russian. In contrast to concurrent efforts, Multi2WOZ contains gold-standard dialogs in target languages that are directly comparable with development and test portions of the English dataset, enabling reliable and comparative estimates of cross-lingual transfer performance for TOD. We then introduce a new framework for multilingual conversational specialization of pretrained language models (PrLMs) that aims to facilitate cross-lingual transfer for arbitrary downstream TOD tasks. Using such conversational PrLMs specialized for concrete target languages, we systematically benchmark a number of zero-shot and few-shot cross-lingual transfer approaches on two standard TOD tasks: Dialog State Tracking and Response Retrieval. Our experiments show that, in most setups, the best performance entails the combination of (I) conversational specialization in the target language and (ii) few-shot transfer for the concrete TOD task. Most importantly, we show that our conversational specialization in the target language allows for an exceptionally sample-efficient few-shot transfer for downstream TOD tasks.
Fair and Argumentative Language Modeling for Computational Argumentation
Apr 08, 2022
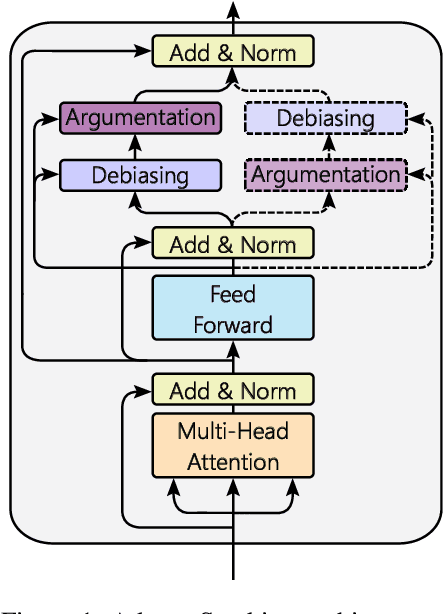
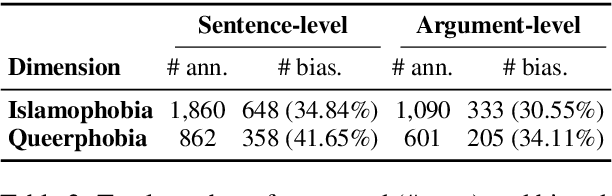
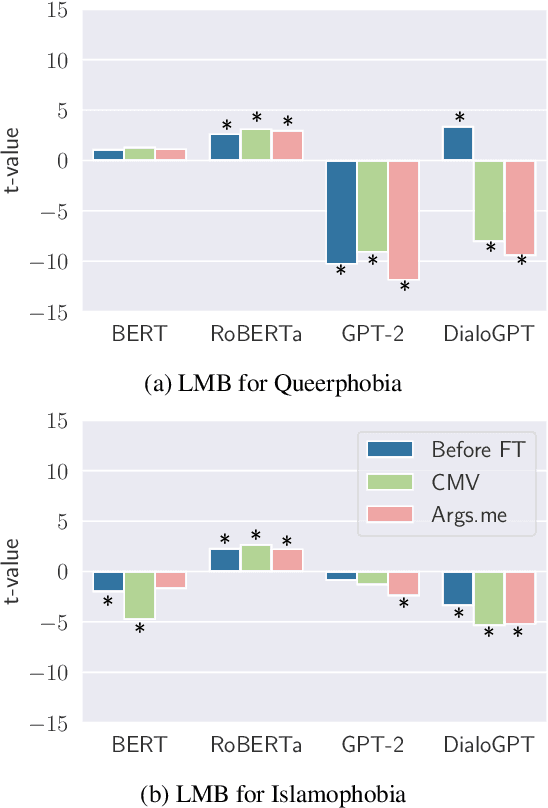
Although much work in NLP has focused on measuring and mitigating stereotypical bias in semantic spaces, research addressing bias in computational argumentation is still in its infancy. In this paper, we address this research gap and conduct a thorough investigation of bias in argumentative language models. To this end, we introduce ABBA, a novel resource for bias measurement specifically tailored to argumentation. We employ our resource to assess the effect of argumentative fine-tuning and debiasing on the intrinsic bias found in transformer-based language models using a lightweight adapter-based approach that is more sustainable and parameter-efficient than full fine-tuning. Finally, we analyze the potential impact of language model debiasing on the performance in argument quality prediction, a downstream task of computational argumentation. Our results show that we are able to successfully and sustainably remove bias in general and argumentative language models while preserving (and sometimes improving) model performance in downstream tasks. We make all experimental code and data available at https://github.com/umanlp/FairArgumentativeLM.
PET: A new Dataset for Process Extraction from Natural Language Text
Mar 09, 2022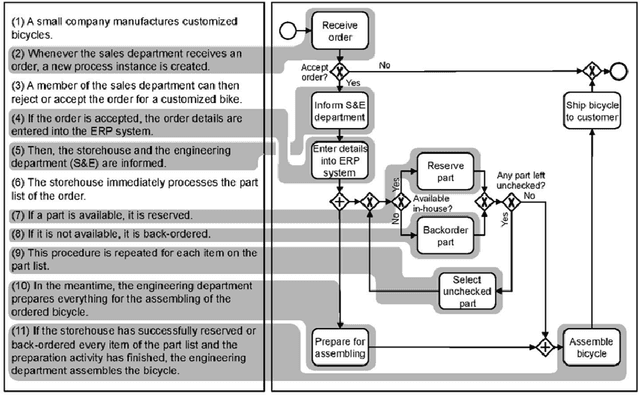
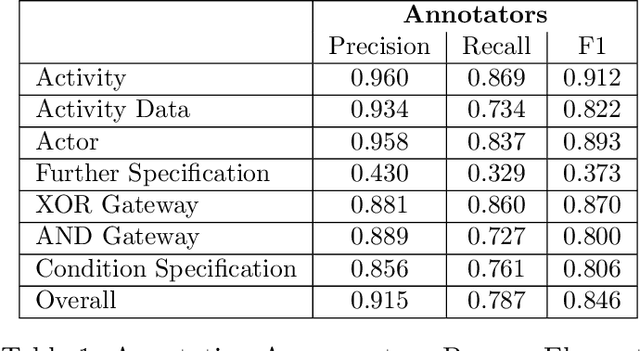
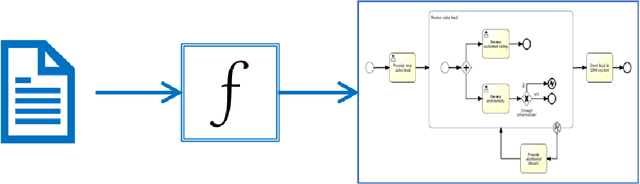
Although there is a long tradition of work in NLP on extracting entities and relations from text, to date there exists little work on the acquisition of business processes from unstructured data such as textual corpora of process descriptions. With this work we aim at filling this gap and establishing the first steps towards bridging data-driven information extraction methodologies from Natural Language Processing and the model-based formalization that is aimed from Business Process Management. For this, we develop the first corpus of business process descriptions annotated with activities, gateways, actors and flow information. We present our new resource, including a detailed overview of the annotation schema and guidelines, as well as a variety of baselines to benchmark the difficulty and challenges of business process extraction from text.