 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Differentiable Modal Synthesis for Learning Nonlinear Dynamics
Jan 15, 2026Modal methods are a long-standing approach to physical modelling synthesis. Extensions to nonlinear problems are possible, including the case of a high-amplitude vibration of a string. A modal decomposition leads to a densely coupled nonlinear system of ordinary differential equations. Recent work in scalar auxiliary variable techniques has enabled construction of explicit and stable numerical solvers for such classes of nonlinear systems. On the other hand, machine learning approaches (in particular neural ordinary differential equations) have been successful in modelling nonlinear systems automatically from data. In this work, we examine how scalar auxiliary variable techniques can be combined with neural ordinary differential equations to yield a stable differentiable model capable of learning nonlinear dynamics. The proposed approach leverages the analytical solution for linear vibration of system's modes so that physical parameters of a system remain easily accessible after the training without the need for a parameter encoder in the model architecture. As a proof of concept, we generate synthetic data for the nonlinear transverse vibration of a string and show that the model can be trained to reproduce the nonlinear dynamics of the system. Sound examples are presented.
Can we reconstruct a dysarthric voice with the large speech model Parler TTS?
Jun 04, 2025Speech disorders can make communication hard or even impossible for those who develop them. Personalised Text-to-Speech is an attractive option as a communication aid. We attempt voice reconstruction using a large speech model, with which we generate an approximation of a dysarthric speaker's voice prior to the onset of their condition. In particular, we investigate whether a state-of-the-art large speech model, Parler TTS, can generate intelligible speech while maintaining speaker identity. We curate a dataset and annotate it with relevant speaker and intelligibility information, and use this to fine-tune the model. Our results show that the model can indeed learn to generate from the distribution of this challenging data, but struggles to control intelligibility and to maintain consistent speaker identity. We propose future directions to improve controllability of this class of model, for the voice reconstruction task.
Segmentation-Variant Codebooks for Preservation of Paralinguistic and Prosodic Information
May 21, 2025Quantization in SSL speech models (e.g., HuBERT) improves compression and performance in tasks like language modeling, resynthesis, and text-to-speech but often discards prosodic and paralinguistic information (e.g., emotion, prominence). While increasing codebook size mitigates some loss, it inefficiently raises bitrates. We propose Segmentation-Variant Codebooks (SVCs), which quantize speech at distinct linguistic units (frame, phone, word, utterance), factorizing it into multiple streams of segment-specific discrete features. Our results show that SVCs are significantly more effective at preserving prosodic and paralinguistic information across probing tasks. Additionally, we find that pooling before rather than after discretization better retains segment-level information. Resynthesis experiments further confirm improved style realization and slightly improved quality while preserving intelligibility.
Learning Nonlinear Dynamics in Physical Modelling Synthesis using Neural Ordinary Differential Equations
May 15, 2025



Modal synthesis methods are a long-standing approach for modelling distributed musical systems. In some cases extensions are possible in order to handle geometric nonlinearities. One such case is the high-amplitude vibration of a string, where geometric nonlinear effects lead to perceptually important effects including pitch glides and a dependence of brightness on striking amplitude. A modal decomposition leads to a coupled nonlinear system of ordinary differential equations. Recent work in applied machine learning approaches (in particular neural ordinary differential equations) has been used to model lumped dynamic systems such as electronic circuits automatically from data. In this work, we examine how modal decomposition can be combined with neural ordinary differential equations for modelling distributed musical systems. The proposed model leverages the analytical solution for linear vibration of system's modes and employs a neural network to account for nonlinear dynamic behaviour. Physical parameters of a system remain easily accessible after the training without the need for a parameter encoder in the network architecture. As an initial proof of concept, we generate synthetic data for a nonlinear transverse string and show that the model can be trained to reproduce the nonlinear dynamics of the system. Sound examples are presented.
Do Discrete Self-Supervised Representations of Speech Capture Tone Distinctions?
Oct 25, 2024



Discrete representations of speech, obtained from Self-Supervised Learning (SSL) foundation models, are widely used, especially where there are limited data for the downstream task, such as for a low-resource language. Typically, discretization of speech into a sequence of symbols is achieved by unsupervised clustering of the latents from an SSL model. Our study evaluates whether discrete symbols - found using k-means - adequately capture tone in two example languages, Mandarin and Yoruba. We compare latent vectors with discrete symbols, obtained from HuBERT base, MandarinHuBERT, or XLS-R, for vowel and tone classification. We find that using discrete symbols leads to a substantial loss of tone information, even for language-specialised SSL models. We suggest that discretization needs to be task-aware, particularly for tone-dependent downstream tasks.
Enabling Beam Search for Language Model-Based Text-to-Speech Synthesis
Aug 29, 2024



Tokenising continuous speech into sequences of discrete tokens and modelling them with language models (LMs) has led to significant success in text-to-speech (TTS) synthesis. Although these models can generate speech with high quality and naturalness, their synthesised samples can still suffer from artefacts, mispronunciation, word repeating, etc. In this paper, we argue these undesirable properties could partly be caused by the randomness of sampling-based strategies during the autoregressive decoding of LMs. Therefore, we look at maximisation-based decoding approaches and propose Temporal Repetition Aware Diverse Beam Search (TRAD-BS) to find the most probable sequences of the generated speech tokens. Experiments with two state-of-the-art LM-based TTS models demonstrate that our proposed maximisation-based decoding strategy generates speech with fewer mispronunciations and improved speaker consistency.
Natural language guidance of high-fidelity text-to-speech with synthetic annotations
Feb 02, 2024Text-to-speech models trained on large-scale datasets have demonstrated impressive in-context learning capabilities and naturalness. However, control of speaker identity and style in these models typically requires conditioning on reference speech recordings, limiting creative applications. Alternatively, natural language prompting of speaker identity and style has demonstrated promising results and provides an intuitive method of control. However, reliance on human-labeled descriptions prevents scaling to large datasets. Our work bridges the gap between these two approaches. We propose a scalable method for labeling various aspects of speaker identity, style, and recording conditions. We then apply this method to a 45k hour dataset, which we use to train a speech language model. Furthermore, we propose simple methods for increasing audio fidelity, significantly outperforming recent work despite relying entirely on found data. Our results demonstrate high-fidelity speech generation in a diverse range of accents, prosodic styles, channel conditions, and acoustic conditions, all accomplished with a single model and intuitive natural language conditioning. Audio samples can be heard at https://text-description-to-speech.com/.
Differentiable Grey-box Modelling of Phaser Effects using Frame-based Spectral Processing
Jun 02, 2023



Machine learning approaches to modelling analog audio effects have seen intensive investigation in recent years, particularly in the context of non-linear time-invariant effects such as guitar amplifiers. For modulation effects such as phasers, however, new challenges emerge due to the presence of the low-frequency oscillator which controls the slowly time-varying nature of the effect. Existing approaches have either required foreknowledge of this control signal, or have been non-causal in implementation. This work presents a differentiable digital signal processing approach to modelling phaser effects in which the underlying control signal and time-varying spectral response of the effect are jointly learned. The proposed model processes audio in short frames to implement a time-varying filter in the frequency domain, with a transfer function based on typical analog phaser circuit topology. We show that the model can be trained to emulate an analog reference device, while retaining interpretable and adjustable parameters. The frame duration is an important hyper-parameter of the proposed model, so an investigation was carried out into its effect on model accuracy. The optimal frame length depends on both the rate and transient decay-time of the target effect, but the frame length can be altered at inference time without a significant change in accuracy.
Using a Large Language Model to Control Speaking Style for Expressive TTS
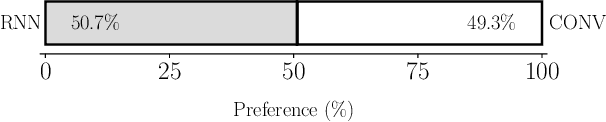
May 17, 2023Appropriate prosody is critical for successful spoken communication. Contextual word embeddings are proven to be helpful in predicting prosody but do not allow for choosing between plausible prosodic renditions. Reference-based TTS models attempt to address this by conditioning speech generation on a reference speech sample. These models can generate expressive speech but this requires finding an appropriate reference. Sufficiently large generative language models have been used to solve various language-related tasks. We explore whether such models can be used to suggest appropriate prosody for expressive TTS. We train a TTS model on a non-expressive corpus and then prompt the language model to suggest changes to pitch, energy and duration. The prompt can be designed for any task and we prompt the model to make suggestions based on target speaking style and dialogue context. The proposed method is rated most appropriate in 49.9\% of cases compared to 31.0\% for a baseline model.
Ensemble prosody prediction for expressive speech synthesis
Apr 03, 2023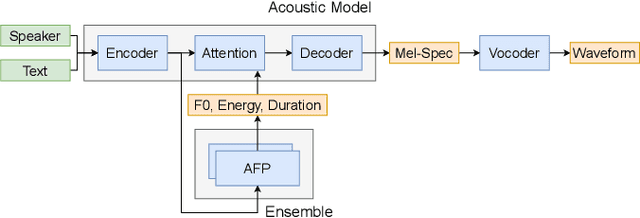


Generating expressive speech with rich and varied prosody continues to be a challenge for Text-to-Speech. Most efforts have focused on sophisticated neural architectures intended to better model the data distribution. Yet, in evaluations it is generally found that no single model is preferred for all input texts. This suggests an approach that has rarely been used before for Text-to-Speech: an ensemble of models. We apply ensemble learning to prosody prediction. We construct simple ensembles of prosody predictors by varying either model architecture or model parameter values. To automatically select amongst the models in the ensemble when performing Text-to-Speech, we propose a novel, and computationally trivial, variance-based criterion. We demonstrate that even a small ensemble of prosody predictors yields useful diversity, which, combined with the proposed selection criterion, outperforms any individual model from the ensemble.