 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexical Tone is Hard to Quantize: Probing Discrete Speech Units in Mandarin and Yorùbá
Apr 08, 2026Discrete speech units (DSUs) are derived by quantising representations from models trained using self-supervised learning (SSL). They are a popular representation for a wide variety of spoken language tasks, including those where prosody matters. DSUs are especially convenient for tasks where text and speech are jointly modelled, such as text-to-speech and multimodal dialogue systems. But we have found that DSUs encode suprasegmental information less reliably than segmental structure, which we demonstrate in this work using lexical tone, though this limitation likely extends to other suprasegmental features such as prosody. Our investigations using the tone languages Mandarin and Yorùbá show that the SSL latent representations themselves do encode tone, yet DSUs obtained using quantisation tend to prioritise phonetic structure, which makes lexical tone less reliably encoded. This remains true for a variety of quantisation methods, not only the most common, K-means. We conclude that current DSU quantisation strategies have limitations for suprasegmental features, which suggests a need for new, tone-aware (or prosody-aware) techniques in speech representation learning. We point towards a potential form of the solution by performing K-means clustering once to encode phonetic information, then again on the residual representation, which better encodes lexical tone.
Do Discrete Self-Supervised Representations of Speech Capture Tone Distinctions?
Oct 25, 2024



Discrete representations of speech, obtained from Self-Supervised Learning (SSL) foundation models, are widely used, especially where there are limited data for the downstream task, such as for a low-resource language. Typically, discretization of speech into a sequence of symbols is achieved by unsupervised clustering of the latents from an SSL model. Our study evaluates whether discrete symbols - found using k-means - adequately capture tone in two example languages, Mandarin and Yoruba. We compare latent vectors with discrete symbols, obtained from HuBERT base, MandarinHuBERT, or XLS-R, for vowel and tone classification. We find that using discrete symbols leads to a substantial loss of tone information, even for language-specialised SSL models. We suggest that discretization needs to be task-aware, particularly for tone-dependent downstream tasks.
Sign-to-Speech Model for Sign Language Understanding: A Case Study of Nigerian Sign Language
Nov 02, 2021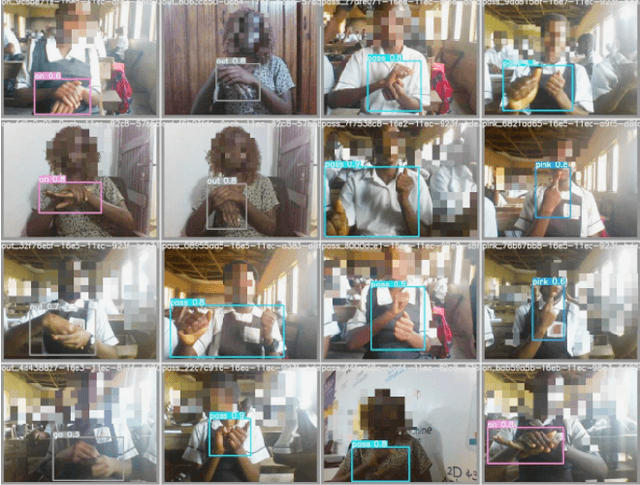
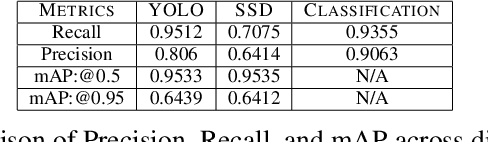
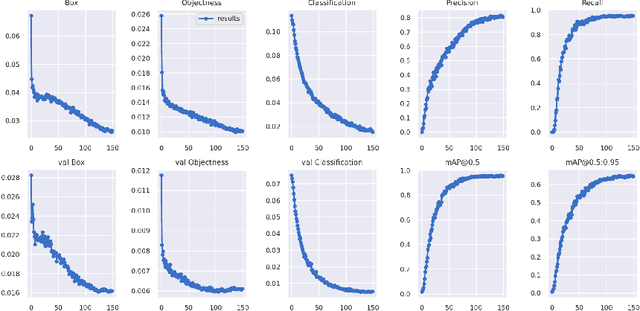
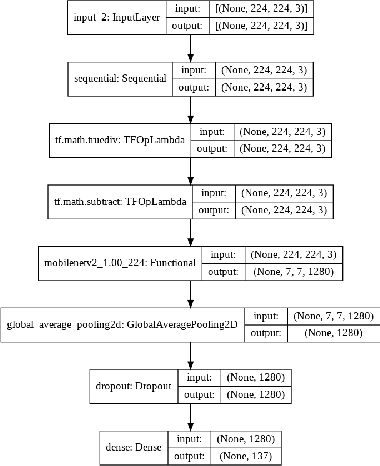
Through this paper, we seek to reduce the communication barrier between the hearing-impaired community and the larger society who are usually not familiar with sign language in the sub-Saharan region of Africa with the largest occurrences of hearing disability cases, while using Nigeria as a case study. The dataset is a pioneer dataset for the Nigerian Sign Language and was created in collaboration with relevant stakeholders. We pre-processed the data in readiness for two different object detection models and a classification model and employed diverse evaluation metrics to gauge model performance on sign-language to text conversion tasks. Finally, we convert the predicted sign texts to speech and deploy the best performing model in a lightweight application that works in real-time and achieves impressive results converting sign words/phrases to text and subsequently, into speech.