 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport Cards: Qualitative Evaluation of Language Models Using Natural Language Summaries
Sep 01, 2024



The rapid development and dynamic nature of large language models (LLMs) make it difficult for conventional quantitative benchmarks to accurately assess their capabilities. We propose report cards, which are human-interpretable, natural language summaries of model behavior for specific skills or topics. We develop a framework to evaluate report cards based on three criteria: specificity (ability to distinguish between models), faithfulness (accurate representation of model capabilities), and interpretability (clarity and relevance to humans). We also propose an iterative algorithm for generating report cards without human supervision and explore its efficacy by ablating various design choices. Through experimentation with popular LLMs, we demonstrate that report cards provide insights beyond traditional benchmarks and can help address the need for a more interpretable and holistic evaluation of LLMs.
Improving Context-Aware Preference Modeling for Language Models
Jul 20, 2024



While finetuning language models from pairwise preferences has proven remarkably effective, the underspecified nature of natural language presents critical challenges. Direct preference feedback is uninterpretable, difficult to provide where multidimensional criteria may apply, and often inconsistent, either because it is based on incomplete instructions or provided by diverse principals. To address these challenges, we consider the two-step preference modeling procedure that first resolves the under-specification by selecting a context, and then evaluates preference with respect to the chosen context. We decompose reward modeling error according to these two steps, which suggests that supervising context in addition to context-specific preference may be a viable approach to aligning models with diverse human preferences. For this to work, the ability of models to evaluate context-specific preference is critical. To this end, we contribute context-conditioned preference datasets and accompanying experiments that investigate the ability of language models to evaluate context-specific preference. We use our datasets to (1) show that existing preference models benefit from, but fail to fully consider, added context, (2) finetune a context-aware reward model with context-specific performance exceeding that of GPT-4 and Llama 3 70B on tested datasets, and (3) investigate the value of context-aware preference modeling.
Consistent Aggregation of Objectives with Diverse Time Preferences Requires Non-Markovian Rewards
Sep 30, 2023As the capabilities of artificial agents improve, they are being increasingly deployed to service multiple diverse objectives and stakeholders. However, the composition of these objectives is often performed ad hoc, with no clear justification. This paper takes a normative approach to multi-objective agency: from a set of intuitively appealing axioms, it is shown that Markovian aggregation of Markovian reward functions is not possible when the time preference (discount factor) for each objective may vary. It follows that optimal multi-objective agents must admit rewards that are non-Markovian with respect to the individual objectives. To this end, a practical non-Markovian aggregation scheme is proposed, which overcomes the impossibility with only one additional parameter for each objective. This work offers new insights into sequential, multi-objective agency and intertemporal choice, and has practical implications for the design of AI systems deployed to serve multiple generations of principals with varying time preference.
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Sep 25, 2023



Recent advances in Language Model (LM) agents and tool use, exemplified by applications like ChatGPT Plugins, enable a rich set of capabilities but also amplify potential risks - such as leaking private data or causing financial losses. Identifying these risks is labor-intensive, necessitating implementing the tools, manually setting up the environment for each test scenario, and finding risky cases. As tools and agents become more complex, the high cost of testing these agents will make it increasingly difficult to find high-stakes, long-tailed risks. To address these challenges, we introduce ToolEmu: a framework that uses an LM to emulate tool execution and enables the testing of LM agents against a diverse range of tools and scenarios, without manual instantiation. Alongside the emulator, we develop an LM-based automatic safety evaluator that examines agent failures and quantifies associated risks. We test both the tool emulator and evaluator through human evaluation and find that 68.8% of failures identified with ToolEmu would be valid real-world agent failures. Using our curated initial benchmark consisting of 36 high-stakes tools and 144 test cases, we provide a quantitative risk analysis of current LM agents and identify numerous failures with potentially severe outcomes. Notably, even the safest LM agent exhibits such failures 23.9% of the time according to our evaluator, underscoring the need to develop safer LM agents for real-world deployment.
Boosted Prompt Ensembles for Large Language Models
Apr 12, 2023Methods such as chain-of-thought prompting and self-consistency have pushed the frontier of language model reasoning performance with no additional training. To further improve performance, we propose a prompt ensembling method for large language models, which uses a small dataset to construct a set of few shot prompts that together comprise a ``boosted prompt ensemble''. The few shot examples for each prompt are chosen in a stepwise fashion to be ``hard'' examples on which the previous step's ensemble is uncertain. We show that this outperforms single-prompt output-space ensembles and bagged prompt-space ensembles on the GSM8k and AQuA datasets, among others. We propose both train-time and test-time versions of boosted prompting that use different levels of available annotation and conduct a detailed empirical study of our algorithm.
Large Language Models Are Human-Level Prompt Engineers
Nov 03, 2022



By conditioning on natural language instructions, large language models (LLMs) have displayed impressive capabilities as general-purpose computers. However, task performance depends significantly on the quality of the prompt used to steer the model, and most effective prompts have been handcrafted by humans. Inspired by classical program synthesis and the human approach to prompt engineering, we propose Automatic Prompt Engineer (APE) for automatic instruction generation and selection. In our method, we treat the instruction as the "program," optimized by searching over a pool of instruction candidates proposed by an LLM in order to maximize a chosen score function. To evaluate the quality of the selected instruction, we evaluate the zero-shot performance of another LLM following the selected instruction. Experiments on 24 NLP tasks show that our automatically generated instructions outperform the prior LLM baseline by a large margin and achieve better or comparable performance to the instructions generated by human annotators on 19/24 tasks. We conduct extensive qualitative and quantitative analyses to explore the performance of APE. We show that APE-engineered prompts can be applied to steer models toward truthfulness and/or informativeness, as well as to improve few-shot learning performance by simply prepending them to standard in-context learning prompts. Please check out our webpage at https://sites.google.com/view/automatic-prompt-engineer.
MoCoDA: Model-based Counterfactual Data Augmentation
Oct 20, 2022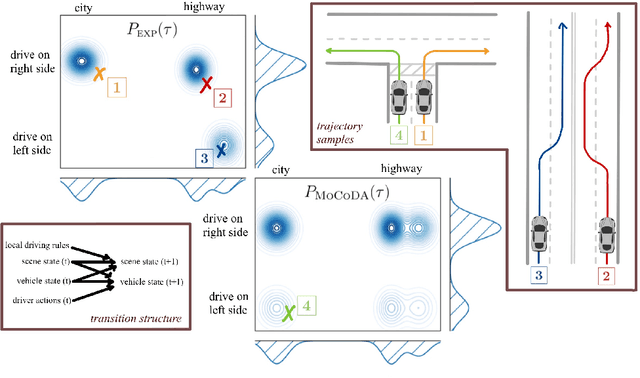
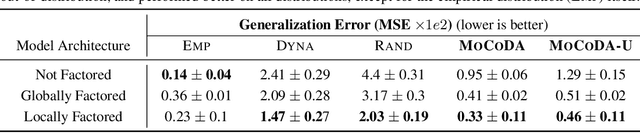
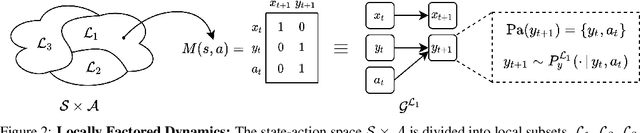
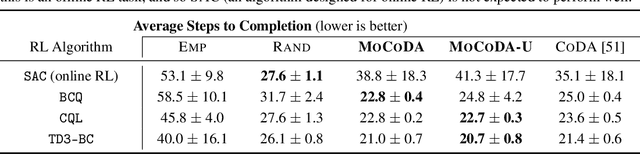
The number of states in a dynamic process is exponential in the number of objects, making reinforcement learning (RL) difficult in complex, multi-object domains. For agents to scale to the real world, they will need to react to and reason about unseen combinations of objects. We argue that the ability to recognize and use local factorization in transition dynamics is a key element in unlocking the power of multi-object reasoning. To this end, we show that (1) known local structure in the environment transitions is sufficient for an exponential reduction in the sample complexity of training a dynamics model, and (2) a locally factored dynamics model provably generalizes out-of-distribution to unseen states and actions. Knowing the local structure also allows us to predict which unseen states and actions this dynamics model will generalize to. We propose to leverage these observations in a novel Model-based Counterfactual Data Augmentation (MoCoDA) framework. MoCoDA applies a learned locally factored dynamics model to an augmented distribution of states and actions to generate counterfactual transitions for RL. MoCoDA works with a broader set of local structures than prior work and allows for direct control over the augmented training distribution. We show that MoCoDA enables RL agents to learn policies that generalize to unseen states and actions. We use MoCoDA to train an offline RL agent to solve an out-of-distribution robotics manipulation task on which standard offline RL algorithms fail.
Counterfactual Data Augmentation using Locally Factored Dynamics
Jul 06, 2020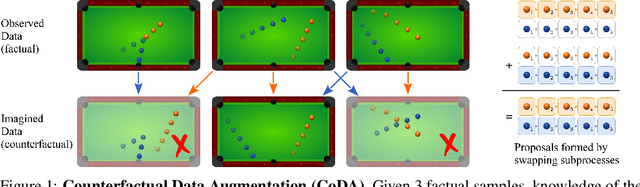
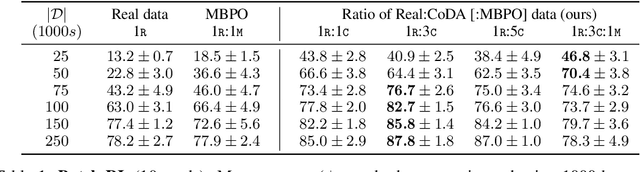

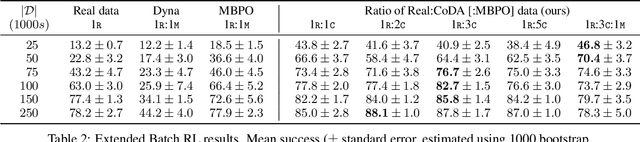
Many dynamic processes, including common scenarios in robotic control and reinforcement learning (RL), involve a set of interacting subprocesses. Though the subprocesses are not independent, their interactions are often sparse, and the dynamics at any given time step can often be decomposed into locally independent causal mechanisms. Such local causal structures can be leveraged to improve the sample efficiency of sequence prediction and off-policy reinforcement learning. We formalize this by introducing local causal models (LCMs), which are induced from a global causal model by conditioning on a subset of the state space. We propose an approach to inferring these structures given an object-oriented state representation, as well as a novel algorithm for model-free Counterfactual Data Augmentation (CoDA). CoDA uses local structures and an experience replay to generate counterfactual experiences that are causally valid in the global model. We find that CoDA significantly improves the performance of RL agents in locally factored tasks, including the batch-constrained and goal-conditioned settings.
Maximum Entropy Gain Exploration for Long Horizon Multi-goal Reinforcement Learning
Jul 06, 2020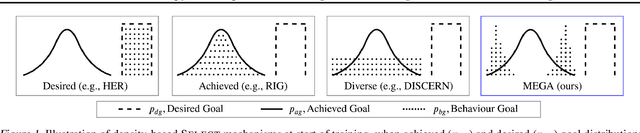
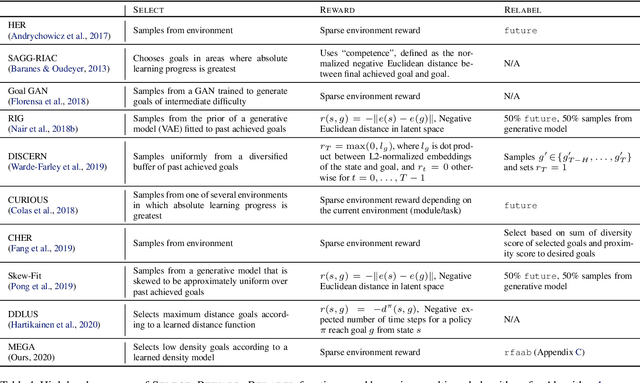
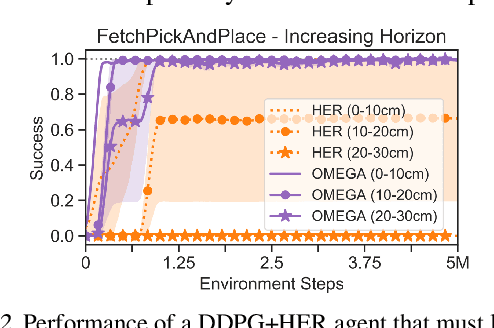

What goals should a multi-goal reinforcement learning agent pursue during training in long-horizon tasks? When the desired (test time) goal distribution is too distant to offer a useful learning signal, we argue that the agent should not pursue unobtainable goals. Instead, it should set its own intrinsic goals that maximize the entropy of the historical achieved goal distribution. We propose to optimize this objective by having the agent pursue past achieved goals in sparsely explored areas of the goal space, which focuses exploration on the frontier of the achievable goal set. We show that our strategy achieves an order of magnitude better sample efficiency than the prior state of the art on long-horizon multi-goal tasks including maze navigation and block stacking.
An Inductive Bias for Distances: Neural Nets that Respect the Triangle Inequality
Feb 14, 2020
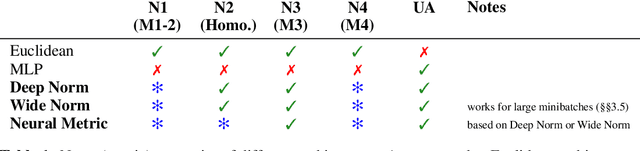
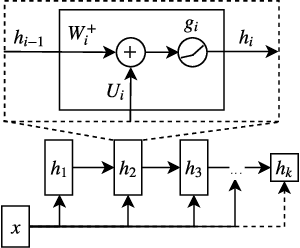

Distances are pervasive in machine learning. They serve as similarity measures, loss functions, and learning targets; it is said that a good distance measure solves a task. When defining distances, the triangle inequality has proven to be a useful constraint, both theoretically--to prove convergence and optimality guarantees--and empirically--as an inductive bias. Deep metric learning architectures that respect the triangle inequality rely, almost exclusively, on Euclidean distance in the latent space. Though effective, this fails to model two broad classes of subadditive distances, common in graphs and reinforcement learning: asymmetric metrics, and metrics that cannot be embedded into Euclidean space. To address these problems, we introduce novel architectures that are guaranteed to satisfy the triangle inequality. We prove our architectures universally approximate norm-induced metrics on $\mathbb{R}^n$, and present a similar result for modified Input Convex Neural Networks. We show that our architectures outperform existing metric approaches when modeling graph distances and have a better inductive bias than non-metric approaches when training data is limited in the multi-goal reinforcement learning setting.