 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Fair Labels Can Yield Unfair Predictions: Graphical Conditions for Introduced Unfairness
Feb 23, 2022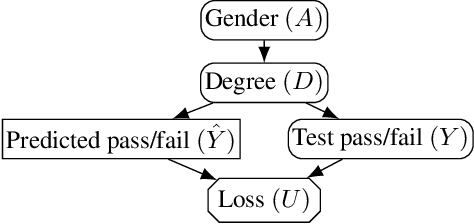
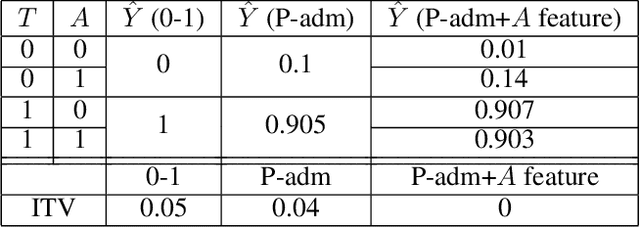
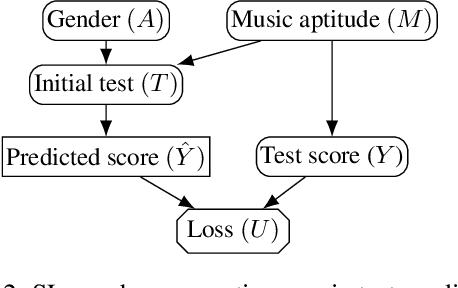
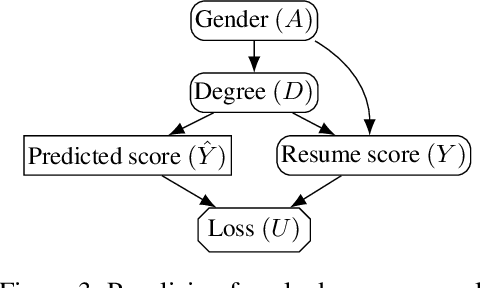
In addition to reproducing discriminatory relationships in the training data, machine learning systems can also introduce or amplify discriminatory effects. We refer to this as introduced unfairness, and investigate the conditions under which it may arise. To this end, we propose introduced total variation as a measure of introduced unfairness, and establish graphical conditions under which it may be incentivised to occur. These criteria imply that adding the sensitive attribute as a feature removes the incentive for introduced variation under well-behaved loss functions. Additionally, taking a causal perspective, introduced path-specific effects shed light on the issue of when specific paths should be considered fair.
Maintaining fairness across distribution shift: do we have viable solutions for real-world applications?
Feb 02, 2022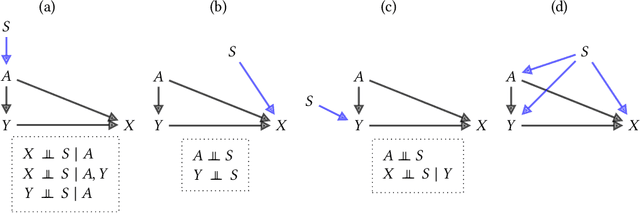
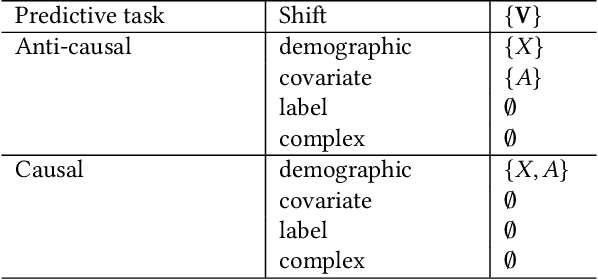
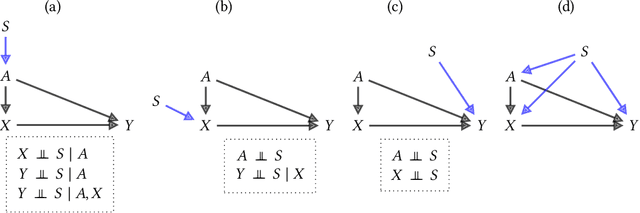
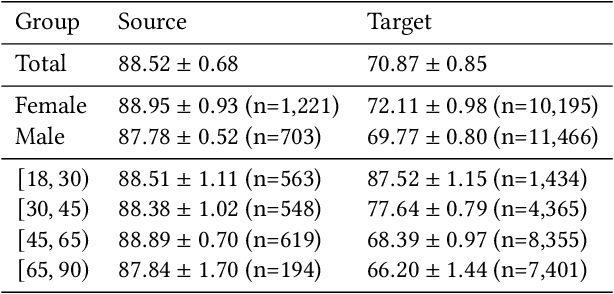
Fairness and robustness are often considered as orthogonal dimensions when evaluating machine learning models. However, recent work has revealed interactions between fairness and robustness, showing that fairness properties are not necessarily maintained under distribution shift. In healthcare settings, this can result in e.g. a model that performs fairly according to a selected metric in "hospital A" showing unfairness when deployed in "hospital B". While a nascent field has emerged to develop provable fair and robust models, it typically relies on strong assumptions about the shift, limiting its impact for real-world applications. In this work, we explore the settings in which recently proposed mitigation strategies are applicable by referring to a causal framing. Using examples of predictive models in dermatology and electronic health records, we show that real-world applications are complex and often invalidate the assumptions of such methods. Our work hence highlights technical, practical, and engineering gaps that prevent the development of robustly fair machine learning models for real-world applications. Finally, we discuss potential remedies at each step of the machine learning pipeline.
Statistical discrimination in learning agents
Oct 21, 2021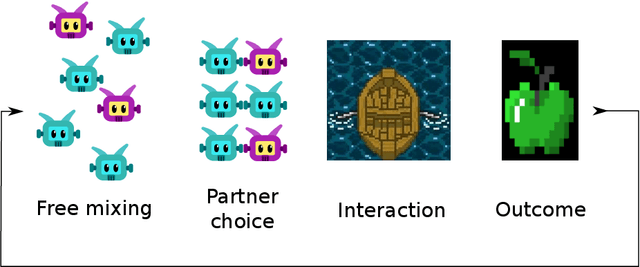
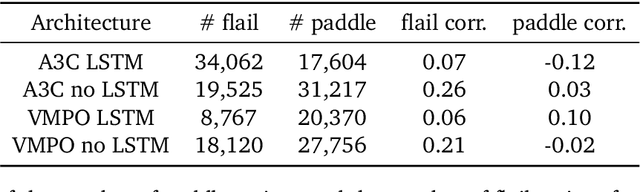
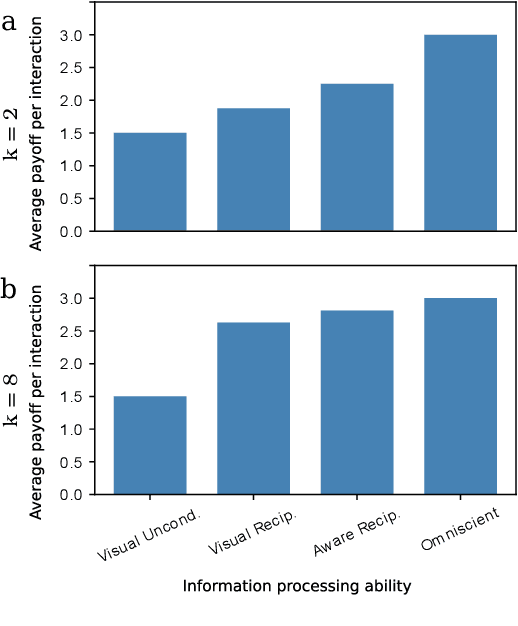
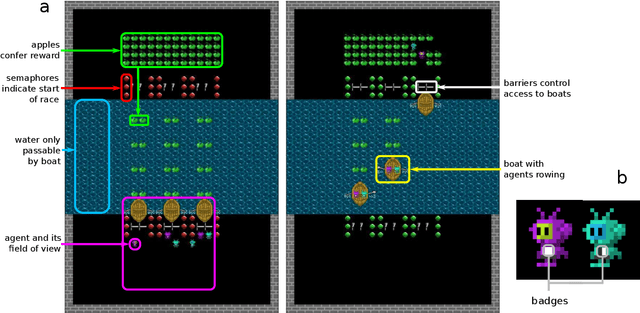
Undesired bias afflicts both human and algorithmic decision making, and may be especially prevalent when information processing trade-offs incentivize the use of heuristics. One primary example is \textit{statistical discrimination} -- selecting social partners based not on their underlying attributes, but on readily perceptible characteristics that covary with their suitability for the task at hand. We present a theoretical model to examine how information processing influences statistical discrimination and test its predictions using multi-agent reinforcement learning with various agent architectures in a partner choice-based social dilemma. As predicted, statistical discrimination emerges in agent policies as a function of both the bias in the training population and of agent architecture. All agents showed substantial statistical discrimination, defaulting to using the readily available correlates instead of the outcome relevant features. We show that less discrimination emerges with agents that use recurrent neural networks, and when their training environment has less bias. However, all agent algorithms we tried still exhibited substantial bias after learning in biased training populations.
Prequential MDL for Causal Structure Learning with Neural Networks
Jul 02, 2021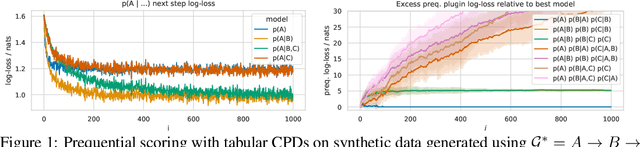
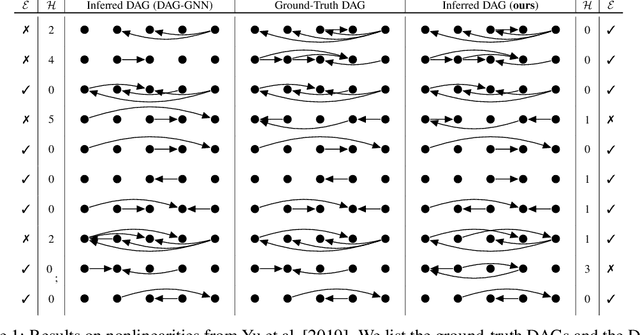
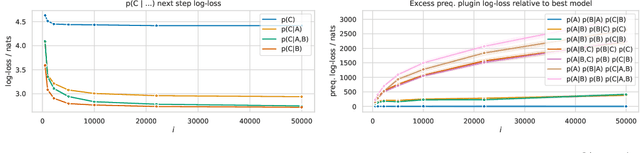
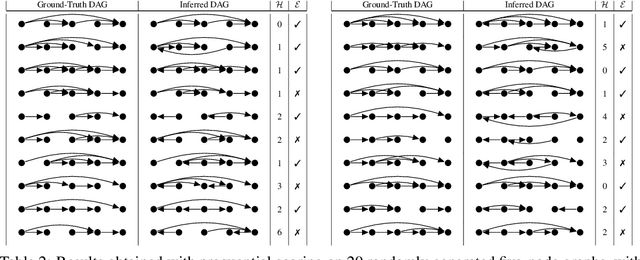
Learning the structure of Bayesian networks and causal relationships from observations is a common goal in several areas of science and technology. We show that the prequential minimum description length principle (MDL) can be used to derive a practical scoring function for Bayesian networks when flexible and overparametrized neural networks are used to model the conditional probability distributions between observed variables. MDL represents an embodiment of Occam's Razor and we obtain plausible and parsimonious graph structures without relying on sparsity inducing priors or other regularizers which must be tuned. Empirically we demonstrate competitive results on synthetic and real-world data. The score often recovers the correct structure even in the presence of strongly nonlinear relationships between variables; a scenario were prior approaches struggle and usually fail. Furthermore we discuss how the the prequential score relates to recent work that infers causal structure from the speed of adaptation when the observations come from a source undergoing distributional shift.
Fairness with Continuous Optimal Transport
Jan 06, 2021

Whilst optimal transport (OT) is increasingly being recognized as a powerful and flexible approach for dealing with fairness issues, current OT fairness methods are confined to the use of discrete OT. In this paper, we leverage recent advances from the OT literature to introduce a stochastic-gradient fairness method based on a dual formulation of continuous OT. We show that this method gives superior performance to discrete OT methods when little data is available to solve the OT problem, and similar performance otherwise. We also show that both continuous and discrete OT methods are able to continually adjust the model parameters to adapt to different levels of unfairness that might occur in real-world applications of ML systems.
Fairness in Machine Learning
Dec 31, 2020
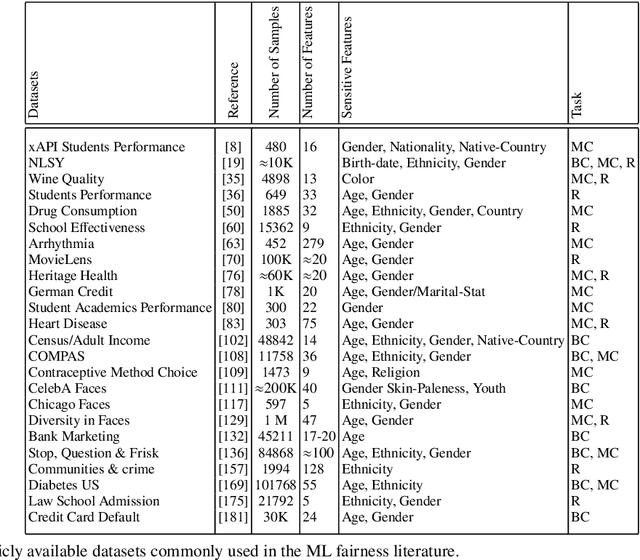
Machine learning based systems are reaching society at large and in many aspects of everyday life. This phenomenon has been accompanied by concerns about the ethical issues that may arise from the adoption of these technologies. ML fairness is a recently established area of machine learning that studies how to ensure that biases in the data and model inaccuracies do not lead to models that treat individuals unfavorably on the basis of characteristics such as e.g. race, gender, disabilities, and sexual or political orientation. In this manuscript, we discuss some of the limitations present in the current reasoning about fairness and in methods that deal with it, and describe some work done by the authors to address them. More specifically, we show how causal Bayesian networks can play an important role to reason about and deal with fairness, especially in complex unfairness scenarios. We describe how optimal transport theory can be used to develop methods that impose constraints on the full shapes of distributions corresponding to different sensitive attributes, overcoming the limitation of most approaches that approximate fairness desiderata by imposing constraints on the lower order moments or other functions of those distributions. We present a unified framework that encompasses methods that can deal with different settings and fairness criteria, and that enjoys strong theoretical guarantees. We introduce an approach to learn fair representations that can generalize to unseen tasks. Finally, we describe a technique that accounts for legal restrictions about the use of sensitive attributes.
Explicit-Duration Markov Switching Models
Sep 12, 2019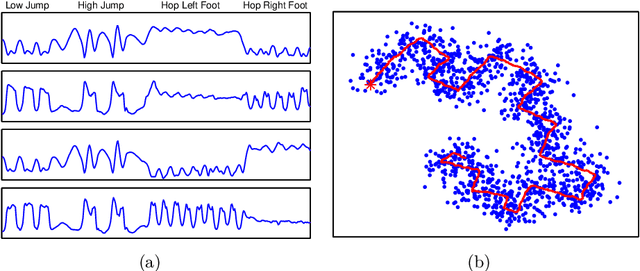
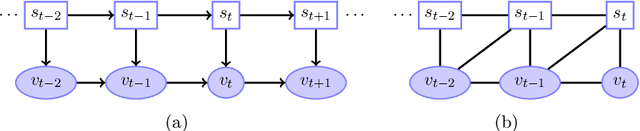
Markov switching models (MSMs) are probabilistic models that employ multiple sets of parameters to describe different dynamic regimes that a time series may exhibit at different periods of time. The switching mechanism between regimes is controlled by unobserved random variables that form a first-order Markov chain. Explicit-duration MSMs contain additional variables that explicitly model the distribution of time spent in each regime. This allows to define duration distributions of any form, but also to impose complex dependence between the observations and to reset the dynamics to initial conditions. Models that focus on the first two properties are most commonly known as hidden semi-Markov models or segment models, whilst models that focus on the third property are most commonly known as changepoint models or reset models. In this monograph, we provide a description of explicit-duration modelling by categorizing the different approaches into three groups, which differ in encoding in the explicit-duration variables different information about regime change/reset boundaries. The approaches are described using the formalism of graphical models, which allows to graphically represent and assess statistical dependence and therefore to easily describe the structure of complex models and derive inference routines. The presentation is intended to be pedagogical, focusing on providing a characterization of the three groups in terms of model structure constraints and inference properties. The monograph is supplemented with a software package that contains most of the models and examples described. The material presented should be useful to both researchers wishing to learn about these models and researchers wishing to develop them further.
Wasserstein Fair Classification
Jul 28, 2019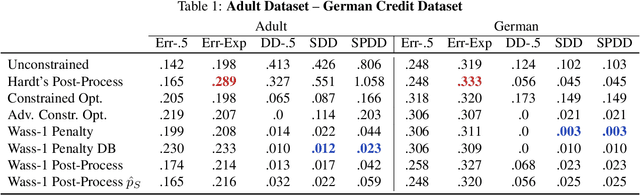
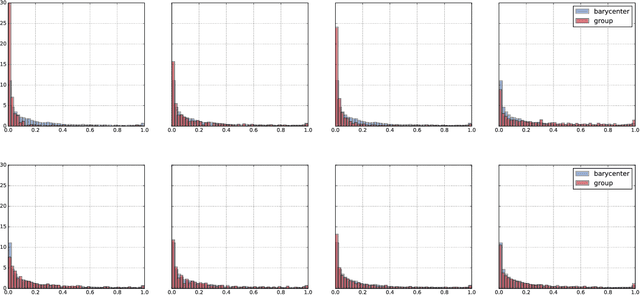
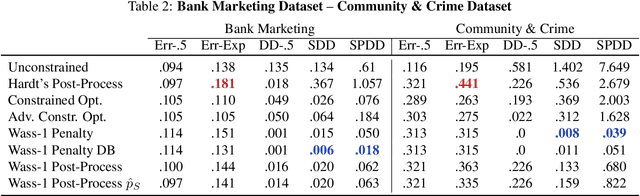
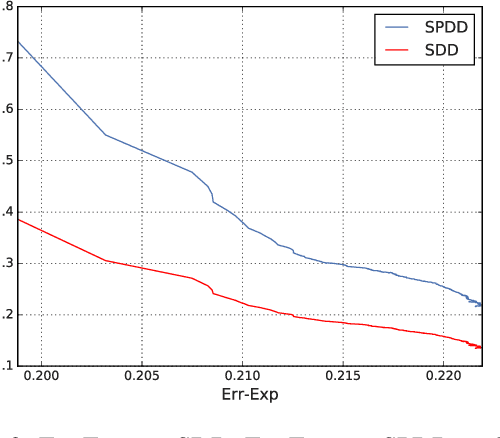
We propose an approach to fair classification that enforces independence between the classifier outputs and sensitive information by minimizing Wasserstein-1 distances. The approach has desirable theoretical properties and is robust to specific choices of the threshold used to obtain class predictions from model outputs. We introduce different methods that enable hiding sensitive information at test time or have a simple and fast implementation. We show empirical performance against different fairness baselines on several benchmark fairness datasets.
Unsupervised Separation of Dynamics from Pixels
Jul 20, 2019
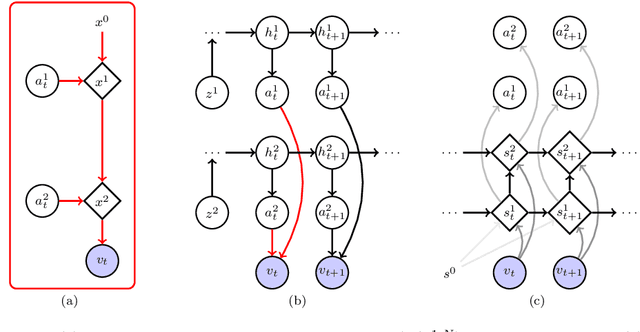
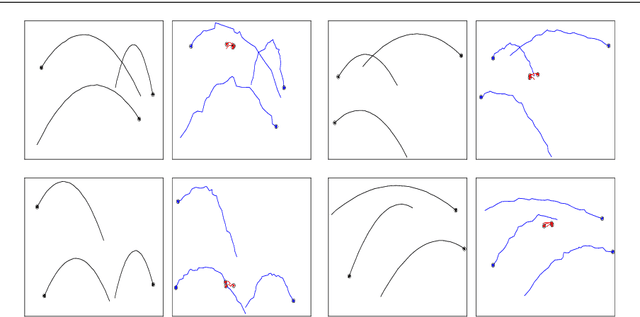
We present an approach to learn the dynamics of multiple objects from image sequences in an unsupervised way. We introduce a probabilistic model that first generate noisy positions for each object through a separate linear state-space model, and then renders the positions of all objects in the same image through a highly non-linear process. Such a linear representation of the dynamics enables us to propose an inference method that uses exact and efficient inference tools and that can be deployed to query the model in different ways without retraining.
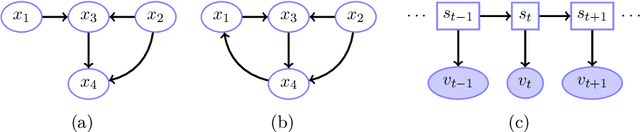
A Causal Bayesian Networks Viewpoint on Fairness
Jul 15, 2019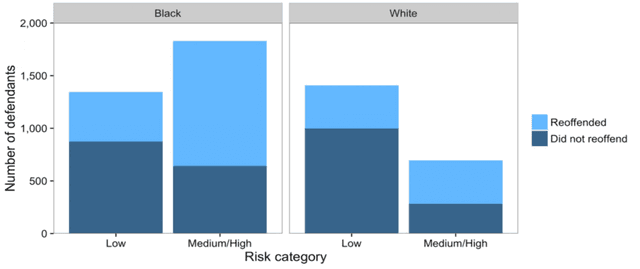
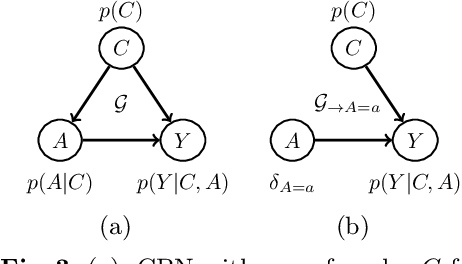
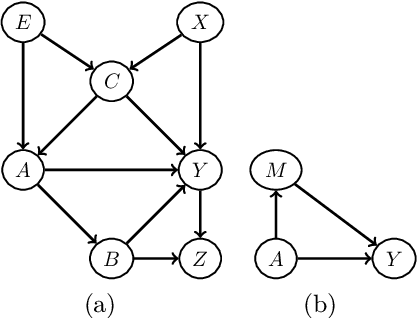
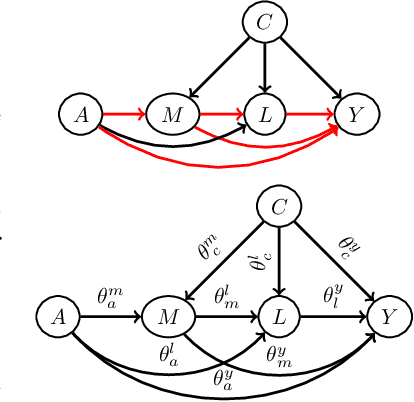
We offer a graphical interpretation of unfairness in a dataset as the presence of an unfair causal path in the causal Bayesian network representing the data-generation mechanism. We use this viewpoint to revisit the recent debate surrounding the COMPAS pretrial risk assessment tool and, more generally, to point out that fairness evaluation on a model requires careful considerations on the patterns of unfairness underlying the training data. We show that causal Bayesian networks provide us with a powerful tool to measure unfairness in a dataset and to design fair models in complex unfairness scenarios.