 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogics-Parsing-Omni Technical Report
Mar 12, 2026Addressing the challenges of fragmented task definitions and the heterogeneity of unstructured data in multimodal parsing, this paper proposes the Omni Parsing framework. This framework establishes a Unified Taxonomy covering documents, images, and audio-visual streams, introducing a progressive parsing paradigm that bridges perception and cognition. Specifically, the framework integrates three hierarchical levels: 1) Holistic Detection, which achieves precise spatial-temporal grounding of objects or events to establish a geometric baseline for perception; 2) Fine-grained Recognition, which performs symbolization (e.g., OCR/ASR) and attribute extraction on localized objects to complete structured entity parsing; and 3) Multi-level Interpreting, which constructs a reasoning chain from local semantics to global logic. A pivotal advantage of this framework is its evidence anchoring mechanism, which enforces a strict alignment between high-level semantic descriptions and low-level facts. This enables ``evidence-based'' logical induction, transforming unstructured signals into standardized knowledge that is locatable, enumerable, and traceable. Building on this foundation, we constructed a standardized dataset and released the Logics-Parsing-Omni model, which successfully converts complex audio-visual signals into machine-readable structured knowledge. Experiments demonstrate that fine-grained perception and high-level cognition are synergistic, effectively enhancing model reliability. Furthermore, to quantitatively evaluate these capabilities, we introduce OmniParsingBench. Code, models and the benchmark are released at https://github.com/alibaba/Logics-Parsing/tree/master/Logics-Parsing-Omni.
Transductive Few-Shot Classification on the Oblique Manifold
Aug 09, 2021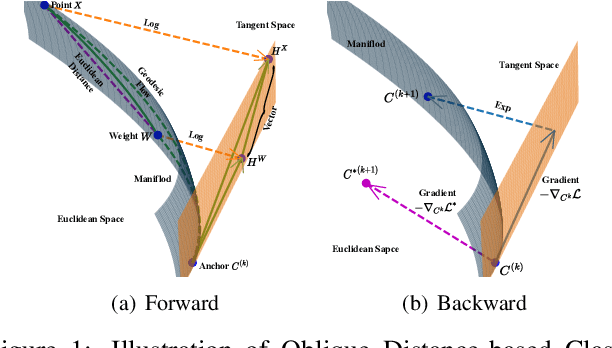
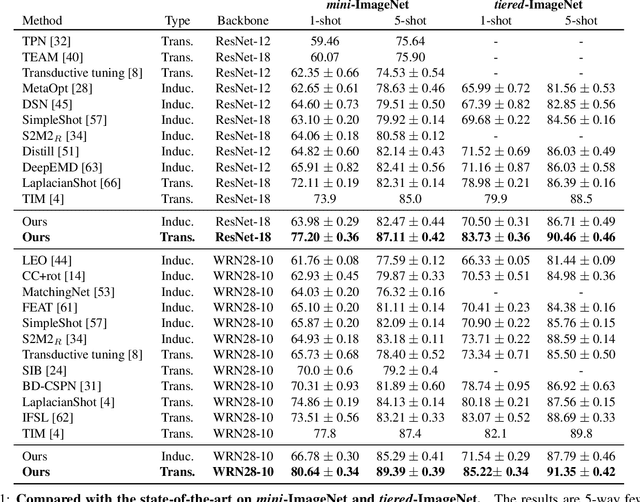
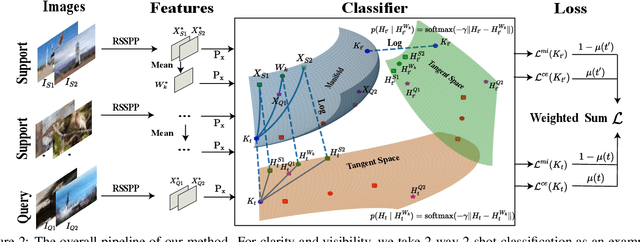
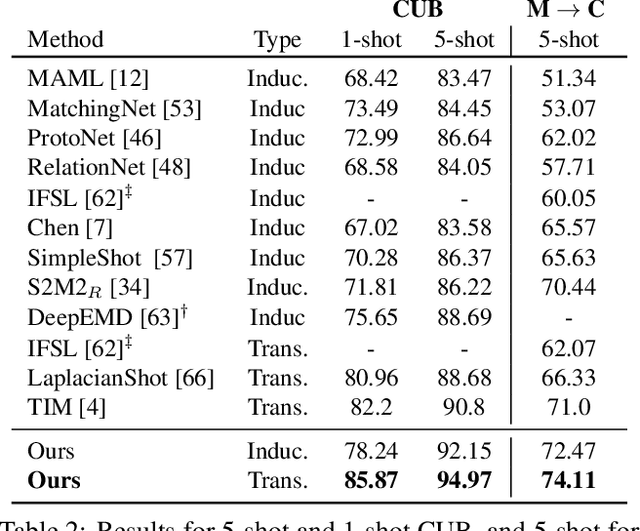
Few-shot learning (FSL) attempts to learn with limited data. In this work, we perform the feature extraction in the Euclidean space and the geodesic distance metric on the Oblique Manifold (OM). Specially, for better feature extraction, we propose a non-parametric Region Self-attention with Spatial Pyramid Pooling (RSSPP), which realizes a trade-off between the generalization and the discriminative ability of the single image feature. Then, we embed the feature to OM as a point. Furthermore, we design an Oblique Distance-based Classifier (ODC) that achieves classification in the tangent spaces which better approximate OM locally by learnable tangency points. Finally, we introduce a new method for parameters initialization and a novel loss function in the transductive settings. Extensive experiments demonstrate the effectiveness of our algorithm and it outperforms state-of-the-art methods on the popular benchmarks: mini-ImageNet, tiered-ImageNet, and Caltech-UCSD Birds-200-2011 (CUB).
Attributes-aided Part Detection and Refinement for Person Re-identification
Feb 27, 2019



Person attributes are often exploited as mid-level human semantic information to help promote the performance of person re-identification task. In this paper, unlike most existing methods simply taking attribute learning as a classification problem, we perform it in a different way with the motivation that attributes are related to specific local regions, which refers to the perceptual ability of attributes. We utilize the process of attribute detection to generate corresponding attribute-part detectors, whose invariance to many influences like poses and camera views can be guaranteed. With detected local part regions, our model extracts local features to handle the body part misalignment problem, which is another major challenge for person re-identification. The local descriptors are further refined by fused attribute information to eliminate interferences caused by detection deviation. Extensive experiments on two popular benchmarks with attribute annotations demonstrate the effectiveness of our model and competitive performance compared with state-of-the-art algorithms.