 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Leakage of Personally Identifiable Information in Language Models
Feb 01, 2023



Language Models (LMs) have been shown to leak information about training data through sentence-level membership inference and reconstruction attacks. Understanding the risk of LMs leaking Personally Identifiable Information (PII) has received less attention, which can be attributed to the false assumption that dataset curation techniques such as scrubbing are sufficient to prevent PII leakage. Scrubbing techniques reduce but do not prevent the risk of PII leakage: in practice scrubbing is imperfect and must balance the trade-off between minimizing disclosure and preserving the utility of the dataset. On the other hand, it is unclear to which extent algorithmic defenses such as differential privacy, designed to guarantee sentence- or user-level privacy, prevent PII disclosure. In this work, we propose (i) a taxonomy of PII leakage in LMs, (ii) metrics to quantify PII leakage, and (iii) attacks showing that PII leakage is a threat in practice. Our taxonomy provides rigorous game-based definitions for PII leakage via black-box extraction, inference, and reconstruction attacks with only API access to an LM. We empirically evaluate attacks against GPT-2 models fine-tuned on three domains: case law, health care, and e-mails. Our main contributions are (i) novel attacks that can extract up to 10 times more PII sequences as existing attacks, (ii) showing that sentence-level differential privacy reduces the risk of PII disclosure but still leaks about 3% of PII sequences, and (iii) a subtle connection between record-level membership inference and PII reconstruction.
SoK: Let The Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning
Dec 21, 2022


Deploying machine learning models in production may allow adversaries to infer sensitive information about training data. There is a vast literature analyzing different types of inference risks, ranging from membership inference to reconstruction attacks. Inspired by the success of games (i.e., probabilistic experiments) to study security properties in cryptography, some authors describe privacy inference risks in machine learning using a similar game-based style. However, adversary capabilities and goals are often stated in subtly different ways from one presentation to the other, which makes it hard to relate and compose results. In this paper, we present a game-based framework to systematize the body of knowledge on privacy inference risks in machine learning.
Invariant Aggregator for Defending Federated Backdoor Attacks
Oct 04, 2022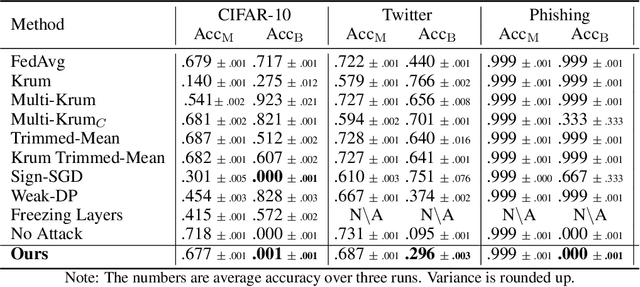

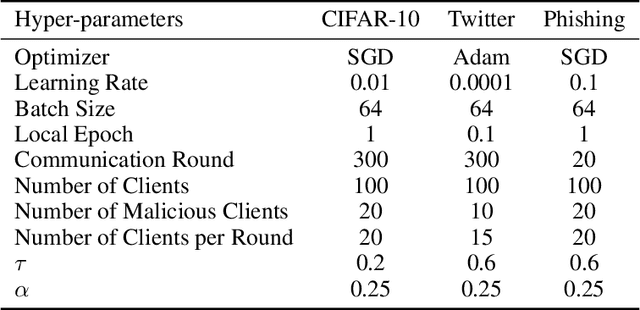
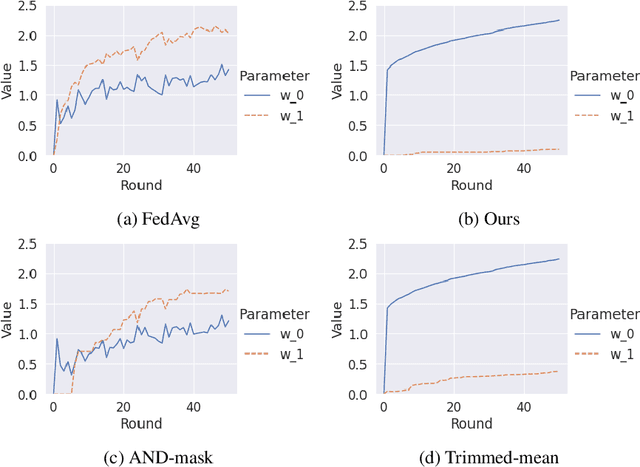
Federated learning is gaining popularity as it enables training of high-utility models across several clients without directly sharing their private data. As a downside, the federated setting makes the model vulnerable to various adversarial attacks in the presence of malicious clients. Specifically, an adversary can perform backdoor attacks to control model predictions via poisoning the training dataset with a trigger. In this work, we propose a mitigation for backdoor attacks in a federated learning setup. Our solution forces the model optimization trajectory to focus on the invariant directions that are generally useful for utility and avoid selecting directions that favor few and possibly malicious clients. Concretely, we consider the sign consistency of the pseudo-gradient (the client update) as an estimation of the invariance. Following this, our approach performs dimension-wise filtering to remove pseudo-gradient elements with low sign consistency. Then, a robust mean estimator eliminates outliers among the remaining dimensions. Our theoretical analysis further shows the necessity of the defense combination and illustrates how our proposed solution defends the federated learning model. Empirical results on three datasets with different modalities and varying number of clients show that our approach mitigates backdoor attacks with a negligible cost on the model utility.
Membership Inference Attacks and Generalization: A Causal Perspective
Sep 18, 2022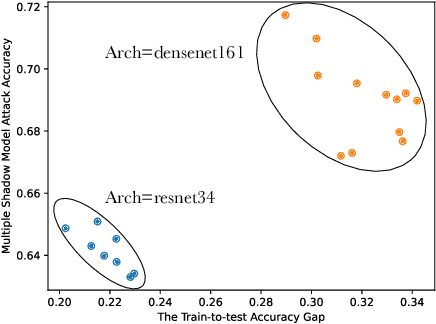
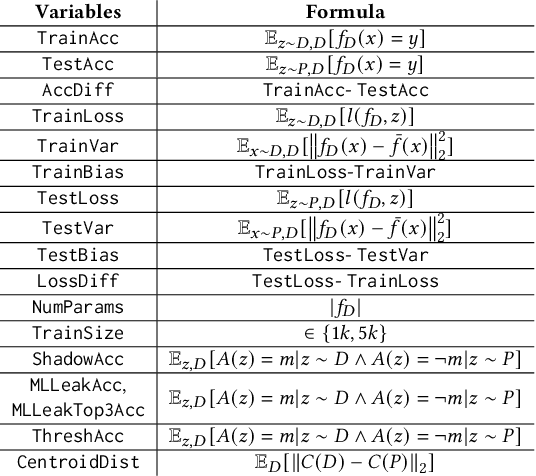
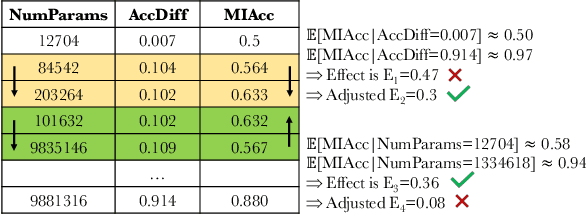
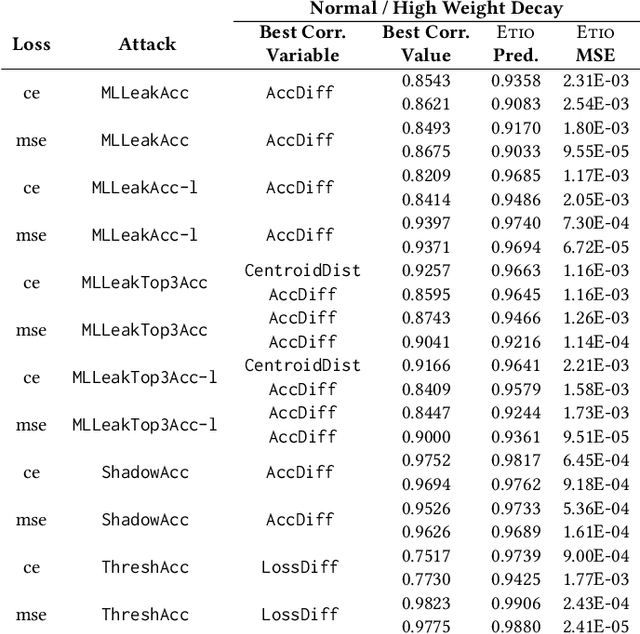
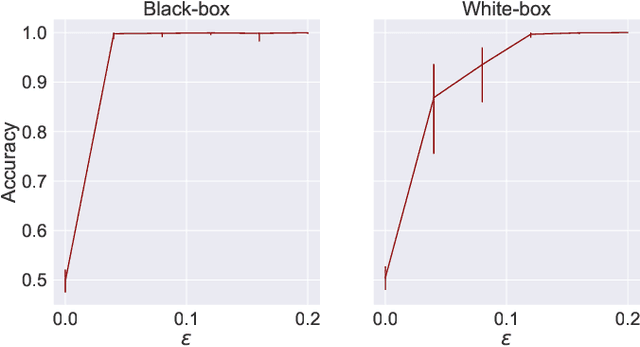
Membership inference (MI) attacks highlight a privacy weakness in present stochastic training methods for neural networks. It is not well understood, however, why they arise. Are they a natural consequence of imperfect generalization only? Which underlying causes should we address during training to mitigate these attacks? Towards answering such questions, we propose the first approach to explain MI attacks and their connection to generalization based on principled causal reasoning. We offer causal graphs that quantitatively explain the observed MI attack performance achieved for $6$ attack variants. We refute several prior non-quantitative hypotheses that over-simplify or over-estimate the influence of underlying causes, thereby failing to capture the complex interplay between several factors. Our causal models also show a new connection between generalization and MI attacks via their shared causal factors. Our causal models have high predictive power ($0.90$), i.e., their analytical predictions match with observations in unseen experiments often, which makes analysis via them a pragmatic alternative.
Distribution inference risks: Identifying and mitigating sources of leakage
Sep 18, 2022

A large body of work shows that machine learning (ML) models can leak sensitive or confidential information about their training data. Recently, leakage due to distribution inference (or property inference) attacks is gaining attention. In this attack, the goal of an adversary is to infer distributional information about the training data. So far, research on distribution inference has focused on demonstrating successful attacks, with little attention given to identifying the potential causes of the leakage and to proposing mitigations. To bridge this gap, as our main contribution, we theoretically and empirically analyze the sources of information leakage that allows an adversary to perpetrate distribution inference attacks. We identify three sources of leakage: (1) memorizing specific information about the $\mathbb{E}[Y|X]$ (expected label given the feature values) of interest to the adversary, (2) wrong inductive bias of the model, and (3) finiteness of the training data. Next, based on our analysis, we propose principled mitigation techniques against distribution inference attacks. Specifically, we demonstrate that causal learning techniques are more resilient to a particular type of distribution inference risk termed distributional membership inference than associative learning methods. And lastly, we present a formalization of distribution inference that allows for reasoning about more general adversaries than was previously possible.
Bayesian Estimation of Differential Privacy
Jun 15, 2022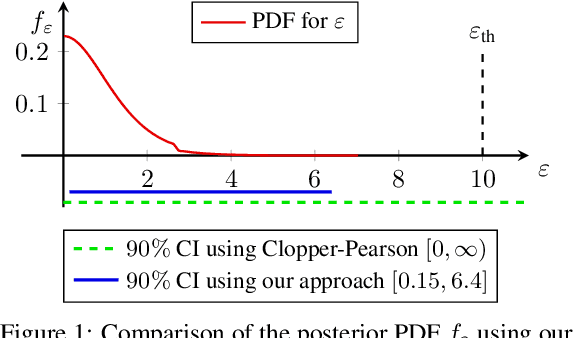

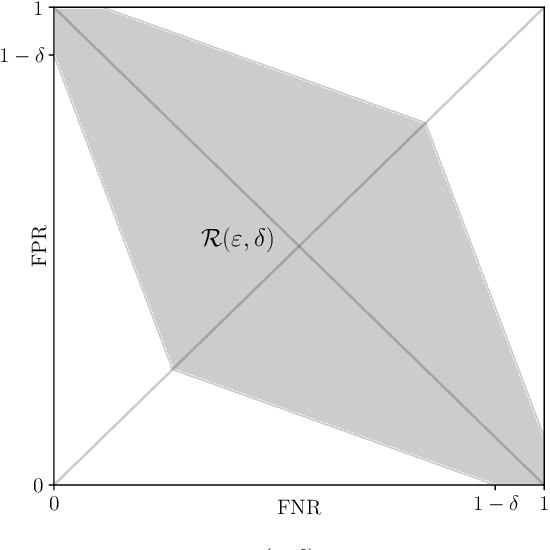
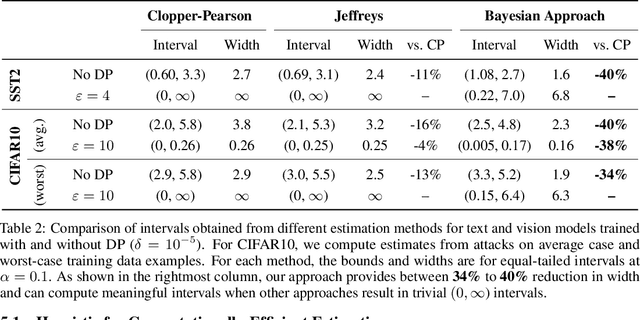
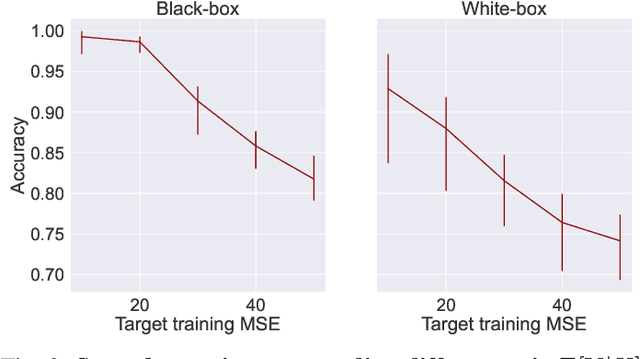
Algorithms such as Differentially Private SGD enable training machine learning models with formal privacy guarantees. However, there is a discrepancy between the protection that such algorithms guarantee in theory and the protection they afford in practice. An emerging strand of work empirically estimates the protection afforded by differentially private training as a confidence interval for the privacy budget $\varepsilon$ spent on training a model. Existing approaches derive confidence intervals for $\varepsilon$ from confidence intervals for the false positive and false negative rates of membership inference attacks. Unfortunately, obtaining narrow high-confidence intervals for $\epsilon$ using this method requires an impractically large sample size and training as many models as samples. We propose a novel Bayesian method that greatly reduces sample size, and adapt and validate a heuristic to draw more than one sample per trained model. Our Bayesian method exploits the hypothesis testing interpretation of differential privacy to obtain a posterior for $\varepsilon$ (not just a confidence interval) from the joint posterior of the false positive and false negative rates of membership inference attacks. For the same sample size and confidence, we derive confidence intervals for $\varepsilon$ around 40% narrower than prior work. The heuristic, which we adapt from label-only DP, can be used to further reduce the number of trained models needed to get enough samples by up to 2 orders of magnitude.
The Connection between Out-of-Distribution Generalization and Privacy of ML Models
Oct 07, 2021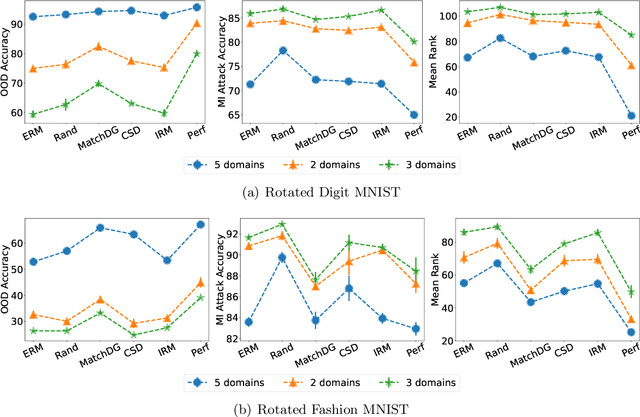

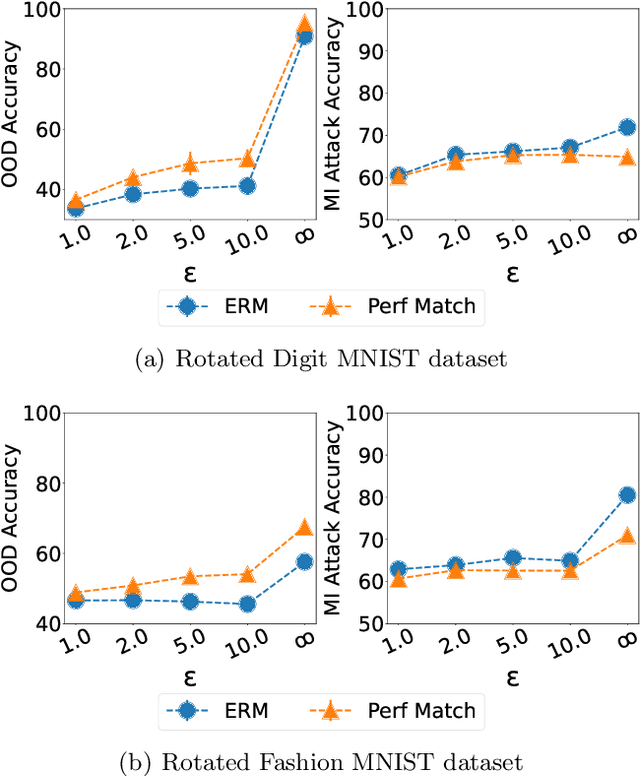
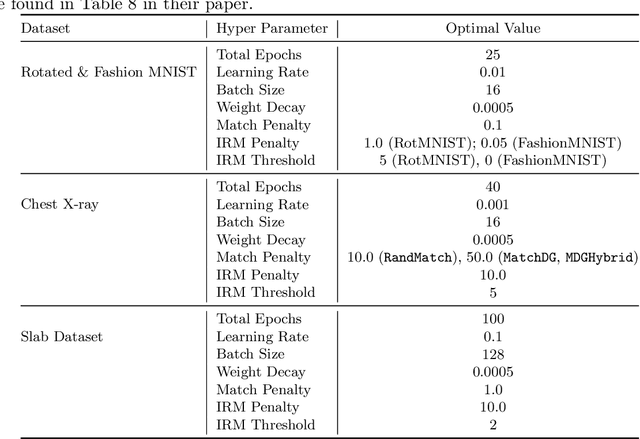
With the goal of generalizing to out-of-distribution (OOD) data, recent domain generalization methods aim to learn "stable" feature representations whose effect on the output remains invariant across domains. Given the theoretical connection between generalization and privacy, we ask whether better OOD generalization leads to better privacy for machine learning models, where privacy is measured through robustness to membership inference (MI) attacks. In general, we find that the relationship does not hold. Through extensive evaluation on a synthetic dataset and image datasets like MNIST, Fashion-MNIST, and Chest X-rays, we show that a lower OOD generalization gap does not imply better robustness to MI attacks. Instead, privacy benefits are based on the extent to which a model captures the stable features. A model that captures stable features is more robust to MI attacks than models that exhibit better OOD generalization but do not learn stable features. Further, for the same provable differential privacy guarantees, a model that learns stable features provides higher utility as compared to others. Our results offer the first extensive empirical study connecting stable features and privacy, and also have a takeaway for the domain generalization community; MI attack can be used as a complementary metric to measure model quality.
Causally Constrained Data Synthesis for Private Data Release
May 27, 2021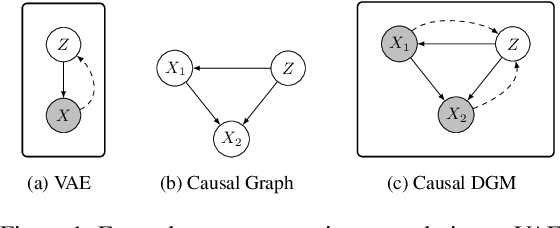
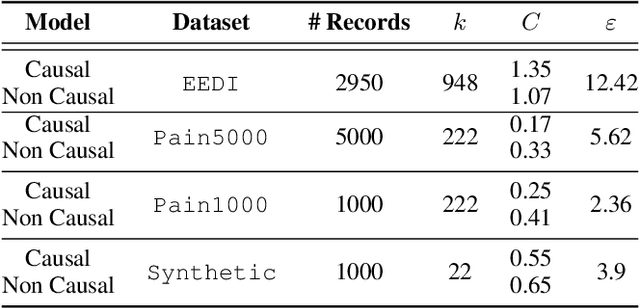
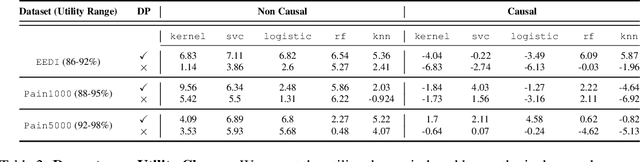
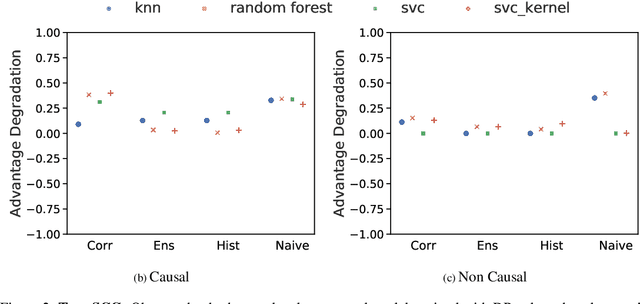
Making evidence based decisions requires data. However for real-world applications, the privacy of data is critical. Using synthetic data which reflects certain statistical properties of the original data preserves the privacy of the original data. To this end, prior works utilize differentially private data release mechanisms to provide formal privacy guarantees. However, such mechanisms have unacceptable privacy vs. utility trade-offs. We propose incorporating causal information into the training process to favorably modify the aforementioned trade-off. We theoretically prove that generative models trained with additional causal knowledge provide stronger differential privacy guarantees. Empirically, we evaluate our solution comparing different models based on variational auto-encoders (VAEs), and show that causal information improves resilience to membership inference, with improvements in downstream utility.
SOTERIA: In Search of Efficient Neural Networks for Private Inference
Jul 25, 2020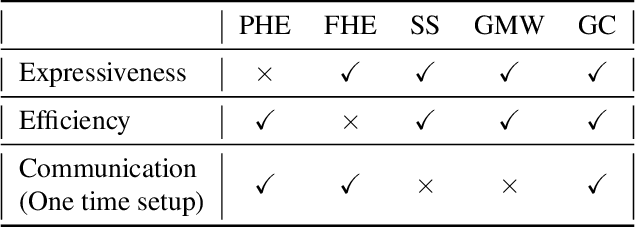
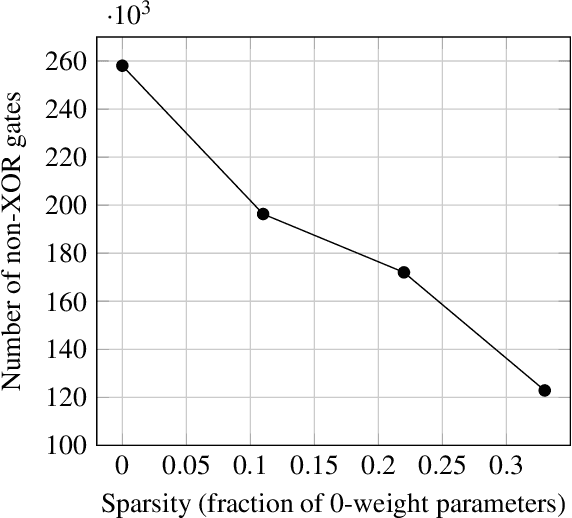
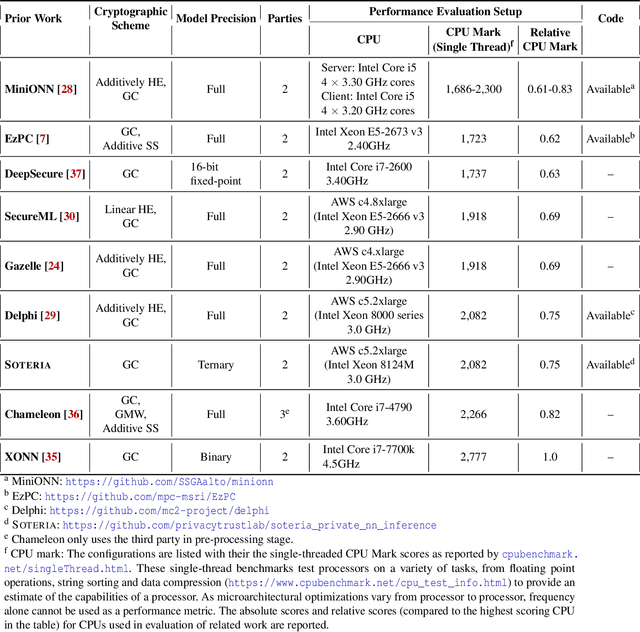
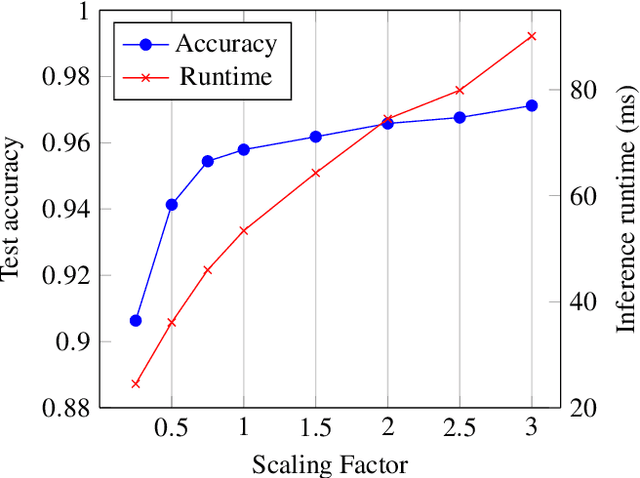
ML-as-a-service is gaining popularity where a cloud server hosts a trained model and offers prediction (inference) service to users. In this setting, our objective is to protect the confidentiality of both the users' input queries as well as the model parameters at the server, with modest computation and communication overhead. Prior solutions primarily propose fine-tuning cryptographic methods to make them efficient for known fixed model architectures. The drawback with this line of approach is that the model itself is never designed to operate with existing efficient cryptographic computations. We observe that the network architecture, internal functions, and parameters of a model, which are all chosen during training, significantly influence the computation and communication overhead of a cryptographic method, during inference. Based on this observation, we propose SOTERIA -- a training method to construct model architectures that are by-design efficient for private inference. We use neural architecture search algorithms with the dual objective of optimizing the accuracy of the model and the overhead of using cryptographic primitives for secure inference. Given the flexibility of modifying a model during training, we find accurate models that are also efficient for private computation. We select garbled circuits as our underlying cryptographic primitive, due to their expressiveness and efficiency, but this approach can be extended to hybrid multi-party computation settings. We empirically evaluate SOTERIA on MNIST and CIFAR10 datasets, to compare with the prior work. Our results confirm that SOTERIA is indeed effective in balancing performance and accuracy.
Replication-Robust Payoff-Allocation with Applications in Machine Learning Marketplaces
Jun 25, 2020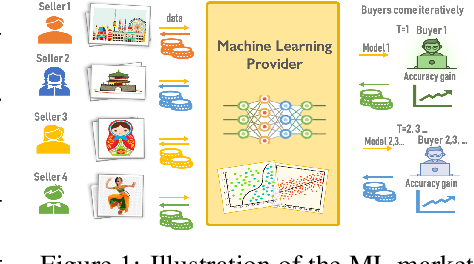
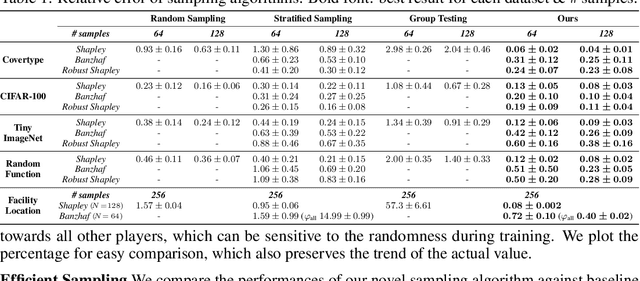
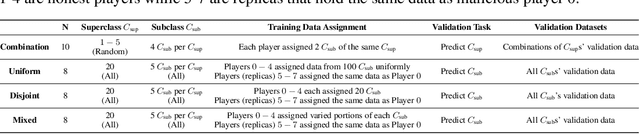
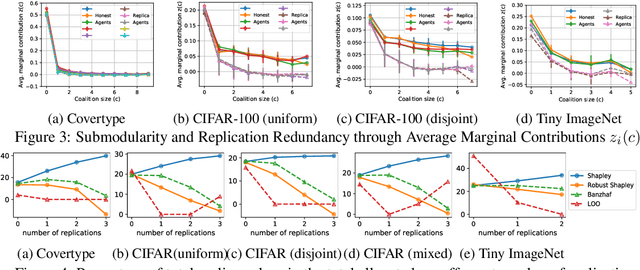
The ever-increasing take-up of machine learning techniques requires ever-more application-specific training data. Manually collecting such training data is a tedious and time-consuming process. Data marketplaces represent a compelling alternative, providing an easy way for acquiring data from potential data providers. A key component of such marketplaces is the compensation mechanism for data providers. Classic payoff-allocation methods such as the Shapley value can be vulnerable to data-replication attacks, and are infeasible to compute in the absence of efficient approximation algorithms. To address these challenges, we present an extensive theoretical study on the vulnerabilities of game theoretic payoff-allocation schemes to replication attacks. Our insights apply to a wide range of payoff-allocation schemes, and enable the design of customised replication-robust payoff-allocations. Furthermore, we present a novel efficient sampling algorithm for approximating payoff-allocation schemes based on marginal contributions. In our experiments, we validate the replication-robustness of classic payoff-allocation schemes and new payoff-allocation schemes derived from our theoretical insights. We also demonstrate the efficiency of our proposed sampling algorithm on a wide range of machine learning tasks.