 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Estimation of Change Points of Physiological Arousal in Drivers
Oct 28, 2022Detecting unsafe driving states, such as stress, drowsiness, and fatigue, is an important component of ensuring driving safety and an essential prerequisite for automatic intervention systems in vehicles. These concerning conditions are primarily connected to the driver's low or high arousal levels. In this study, we describe a framework for processing multimodal physiological time-series from wearable sensors during driving and locating points of prominent change in drivers' physiological arousal state. These points of change could potentially indicate events that require just-in-time intervention. We apply time-series segmentation on heart rate and breathing rate measurements and quantify their robustness in capturing change points in electrodermal activity, treated as a reference index for arousal, as well as on self-reported stress ratings, using three public datasets. Our experiments demonstrate that physiological measures are veritable indicators of change points of arousal and perform robustly across an extensive ablation study.
Leveraging Label Correlations in a Multi-label Setting: A Case Study in Emotion
Oct 28, 2022


Detecting emotions expressed in text has become critical to a range of fields. In this work, we investigate ways to exploit label correlations in multi-label emotion recognition models to improve emotion detection. First, we develop two modeling approaches to the problem in order to capture word associations of the emotion words themselves, by either including the emotions in the input, or by leveraging Masked Language Modeling (MLM). Second, we integrate pairwise constraints of emotion representations as regularization terms alongside the classification loss of the models. We split these terms into two categories, local and global. The former dynamically change based on the gold labels, while the latter remain static during training. We demonstrate state-of-the-art performance across Spanish, English, and Arabic in SemEval 2018 Task 1 E-c using monolingual BERT-based models. On top of better performance, we also demonstrate improved robustness. Code is available at https://github.com/gchochla/Demux-MEmo.
Leveraging Open Data and Task Augmentation to Automated Behavioral Coding of Psychotherapy Conversations in Low-Resource Scenarios
Oct 25, 2022In psychotherapy interactions, the quality of a session is assessed by codifying the communicative behaviors of participants during the conversation through manual observation and annotation. Developing computational approaches for automated behavioral coding can reduce the burden on human coders and facilitate the objective evaluation of the intervention. In the real world, however, implementing such algorithms is associated with data sparsity challenges since privacy concerns lead to limited available in-domain data. In this paper, we leverage a publicly available conversation-based dataset and transfer knowledge to the low-resource behavioral coding task by performing an intermediate language model training via meta-learning. We introduce a task augmentation method to produce a large number of "analogy tasks" - tasks similar to the target one - and demonstrate that the proposed framework predicts target behaviors more accurately than all the other baseline models.
Unsupervised active speaker detection in media content using cross-modal information
Sep 24, 2022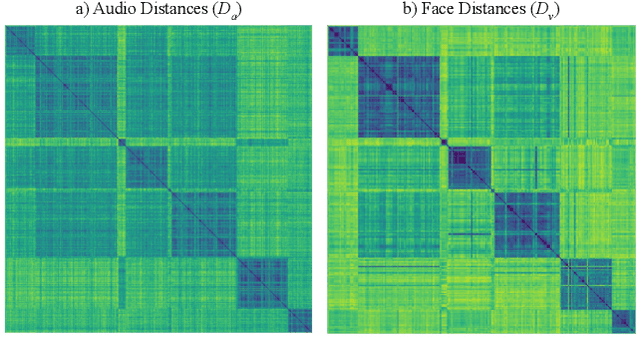
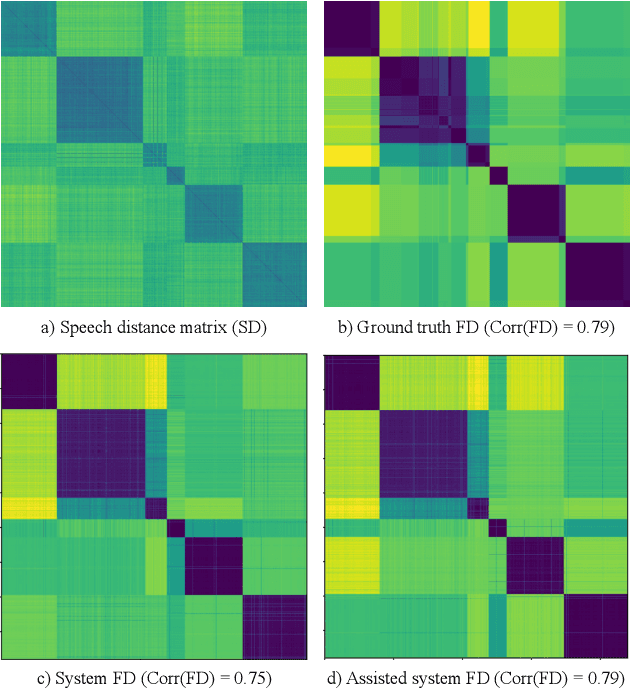

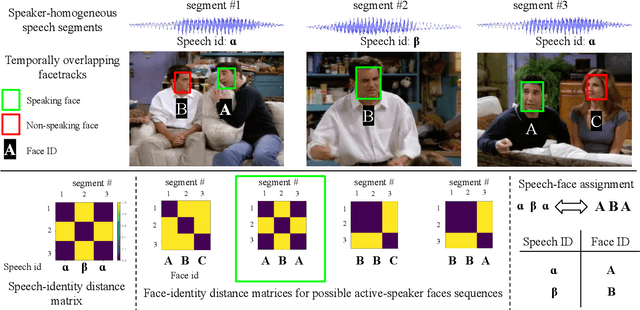
We present a cross-modal unsupervised framework for active speaker detection in media content such as TV shows and movies. Machine learning advances have enabled impressive performance in identifying individuals from speech and facial images. We leverage speaker identity information from speech and faces, and formulate active speaker detection as a speech-face assignment task such that the active speaker's face and the underlying speech identify the same person (character). We express the speech segments in terms of their associated speaker identity distances, from all other speech segments, to capture a relative identity structure for the video. Then we assign an active speaker's face to each speech segment from the concurrently appearing faces such that the obtained set of active speaker faces displays a similar relative identity structure. Furthermore, we propose a simple and effective approach to address speech segments where speakers are present off-screen. We evaluate the proposed system on three benchmark datasets -- Visual Person Clustering dataset, AVA-active speaker dataset, and Columbia dataset -- consisting of videos from entertainment and broadcast media, and show competitive performance to state-of-the-art fully supervised methods.
The 2022 Far-field Speaker Verification Challenge: Exploring domain mismatch and semi-supervised learning under the far-field scenario
Sep 16, 2022
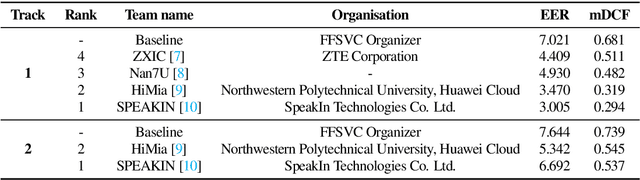
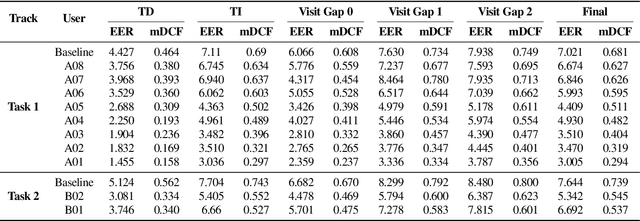
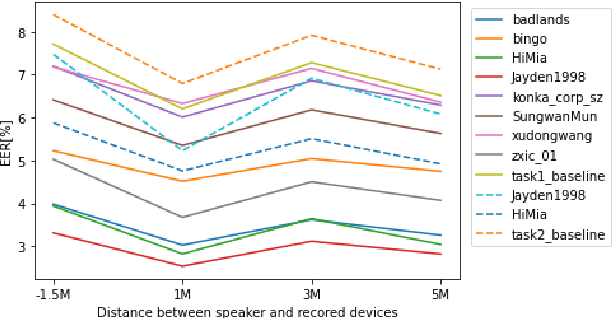
FFSVC2022 is the second challenge of far-field speaker verification. FFSVC2022 provides the fully-supervised far-field speaker verification to further explore the far-field scenario and proposes semi-supervised far-field speaker verification. In contrast to FFSVC2020, FFSVC2022 focus on the single-channel scenario. In addition, a supplementary set for the FFSVC2020 dataset is released this year. The supplementary set consists of more recording devices and has the same data distribution as the FFSVC2022 evaluation set. This paper summarizes the FFSVC 2022, including tasks description, trial designing details, a baseline system and a summary of challenge results. The challenge results indicate substantial progress made in the field but also present that there are still difficulties with the far-field scenario.
VAuLT: Augmenting the Vision-and-Language Transformer with the Propagation of Deep Language Representations
Aug 18, 2022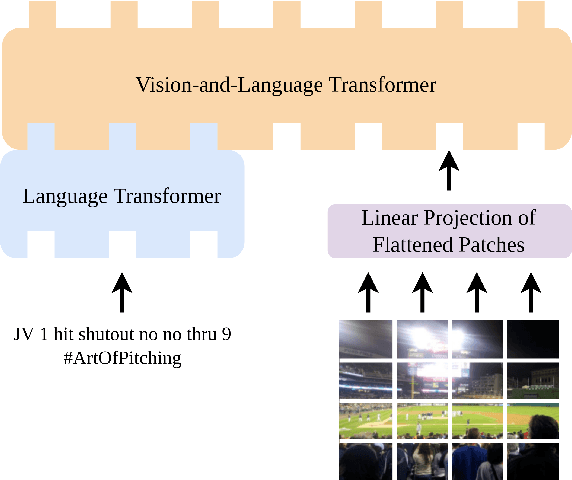

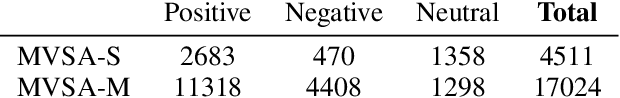

We propose the Vision-and-Augmented-Language Transformer (VAuLT). VAuLT is an extension of the popular Vision-and-Language Transformer (ViLT), and improves performance on vision-and-language tasks that involve more complex text inputs than image captions while having minimal impact on training and inference efficiency. ViLT, importantly, enables efficient training and inference in vision-and-language tasks, achieved by using a shallow image encoder. However, it is pretrained on captioning and similar datasets, where the language input is simple, literal, and descriptive, therefore lacking linguistic diversity. So, when working with multimedia data in the wild, such as multimodal social media data (in our work, Twitter), there is a notable shift from captioning language data, as well as diversity of tasks, and we indeed find evidence that the language capacity of ViLT is lacking instead. The key insight of VAuLT is to propagate the output representations of a large language model like BERT to the language input of ViLT. We show that such a strategy significantly improves over ViLT on vision-and-language tasks involving richer language inputs and affective constructs, such as TWITTER-2015, TWITTER-2017, MVSA-Single and MVSA-Multiple, but lags behind pure reasoning tasks such as the Bloomberg Twitter Text-Image Relationship dataset. We have released the code for all our experiments at https://github.com/gchochla/VAuLT.
Automating Detection of Papilledema in Pediatric Fundus Images with Explainable Machine Learning
Jul 10, 2022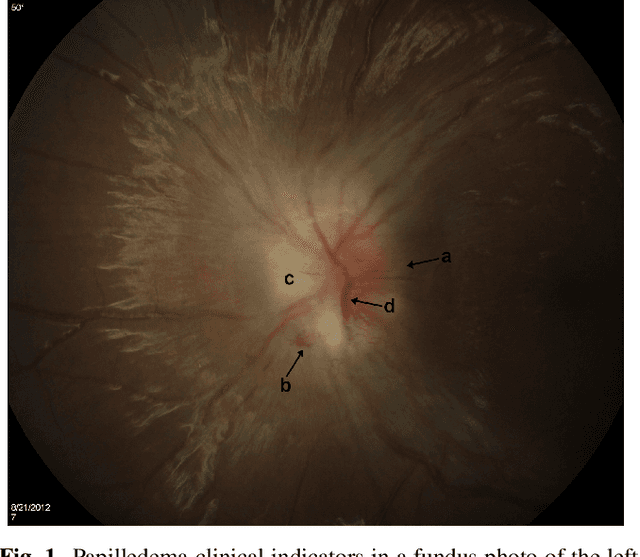
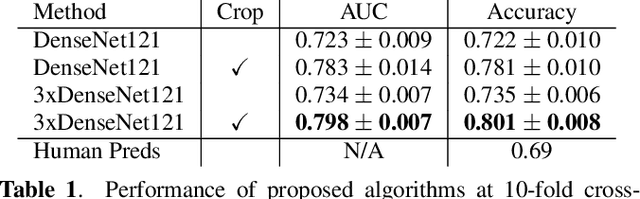
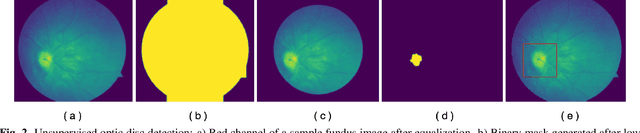
Papilledema is an ophthalmic neurologic disorder in which increased intracranial pressure leads to swelling of the optic nerves. Undiagnosed papilledema in children may lead to blindness and may be a sign of life-threatening conditions, such as brain tumors. Robust and accurate clinical diagnosis of this syndrome can be facilitated by automated analysis of fundus images using deep learning, especially in the presence of challenges posed by pseudopapilledema that has similar fundus appearance but distinct clinical implications. We present a deep learning-based algorithm for the automatic detection of pediatric papilledema. Our approach is based on optic disc localization and detection of explainable papilledema indicators through data augmentation. Experiments on real-world clinical data demonstrate that our proposed method is effective with a diagnostic accuracy comparable to expert ophthalmologists.
User-Level Differential Privacy against Attribute Inference Attack of Speech Emotion Recognition in Federated Learning
Apr 05, 2022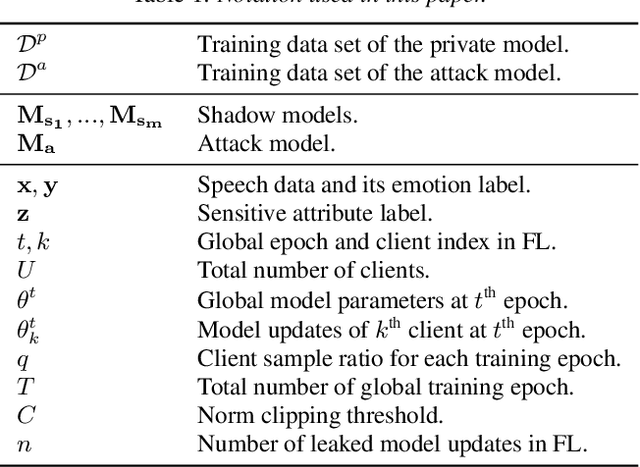
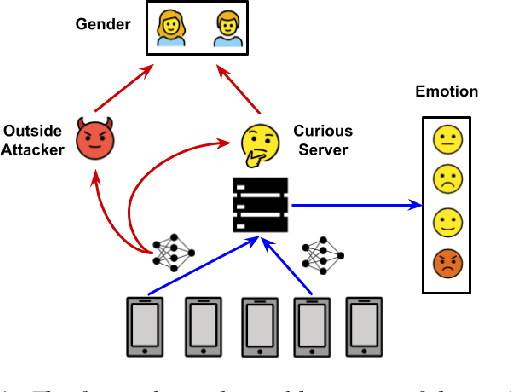
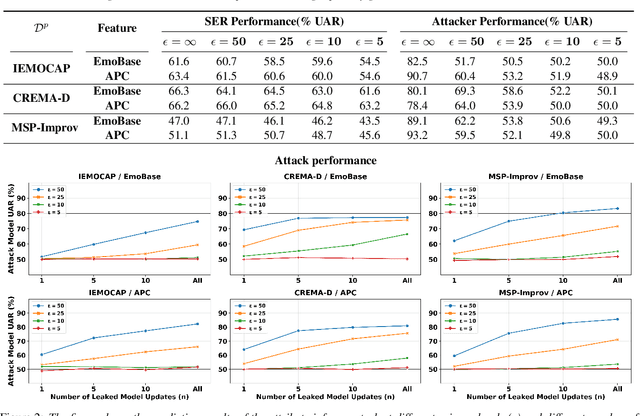
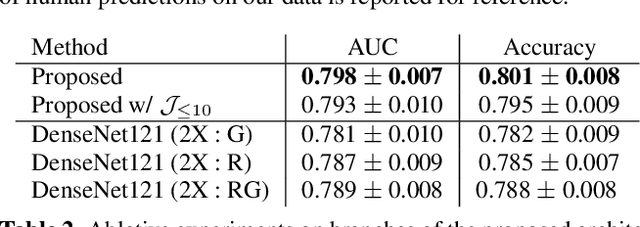
Many existing privacy-enhanced speech emotion recognition (SER) frameworks focus on perturbing the original speech data through adversarial training within a centralized machine learning setup. However, this privacy protection scheme can fail since the adversary can still access the perturbed data. In recent years, distributed learning algorithms, especially federated learning (FL), have gained popularity to protect privacy in machine learning applications. While FL provides good intuition to safeguard privacy by keeping the data on local devices, prior work has shown that privacy attacks, such as attribute inference attacks, are achievable for SER systems trained using FL. In this work, we propose to evaluate the user-level differential privacy (UDP) in mitigating the privacy leaks of the SER system in FL. UDP provides theoretical privacy guarantees with privacy parameters $\epsilon$ and $\delta$. Our results show that the UDP can effectively decrease attribute information leakage while keeping the utility of the SER system with the adversary accessing one model update. However, the efficacy of the UDP suffers when the FL system leaks more model updates to the adversary. We make the code publicly available to reproduce the results in https://github.com/usc-sail/fed-ser-leakage.
Multimodal Clustering with Role Induced Constraints for Speaker Diarization
Apr 01, 2022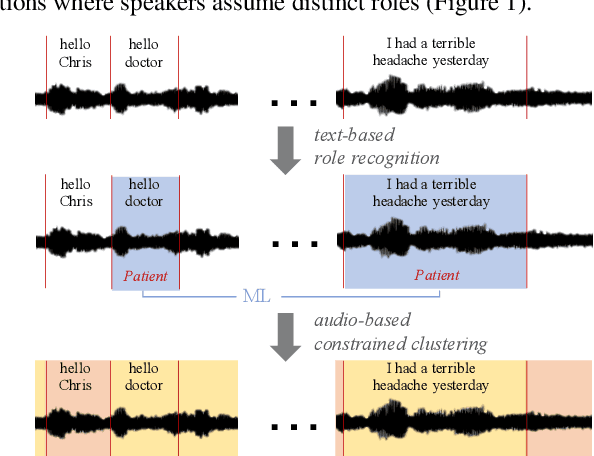
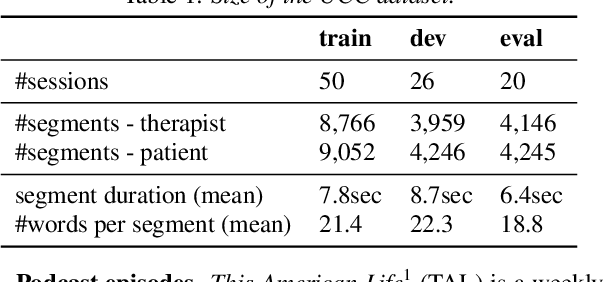
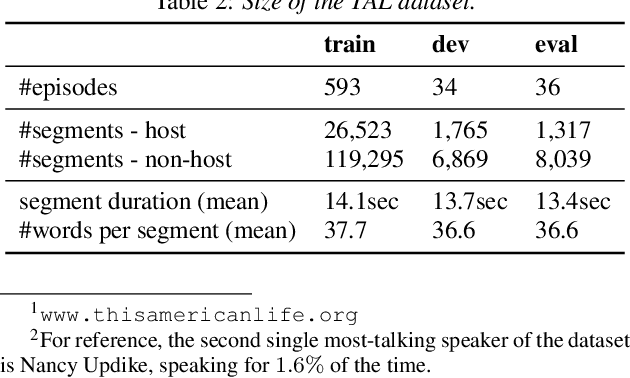
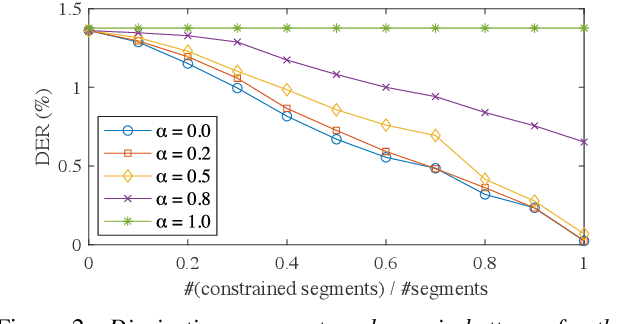
Speaker clustering is an essential step in conventional speaker diarization systems and is typically addressed as an audio-only speech processing task. The language used by the participants in a conversation, however, carries additional information that can help improve the clustering performance. This is especially true in conversational interactions, such as business meetings, interviews, and lectures, where specific roles assumed by interlocutors (manager, client, teacher, etc.) are often associated with distinguishable linguistic patterns. In this paper we propose to employ a supervised text-based model to extract speaker roles and then use this information to guide an audio-based spectral clustering step by imposing must-link and cannot-link constraints between segments. The proposed method is applied on two different domains, namely on medical interactions and on podcast episodes, and is shown to yield improved results when compared to the audio-only approach.
Using Active Speaker Faces for Diarization in TV shows
Mar 30, 2022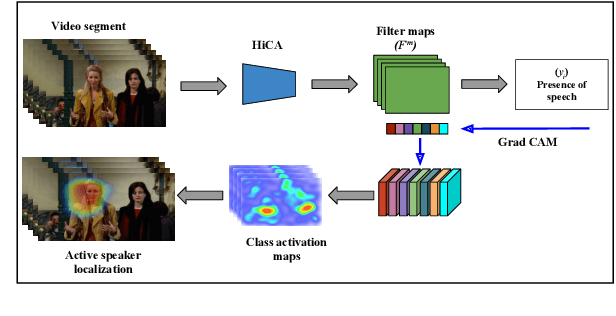
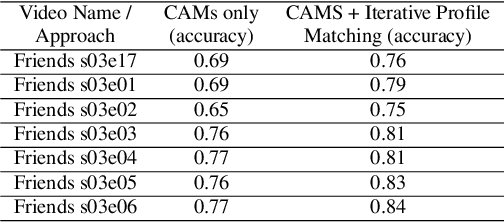
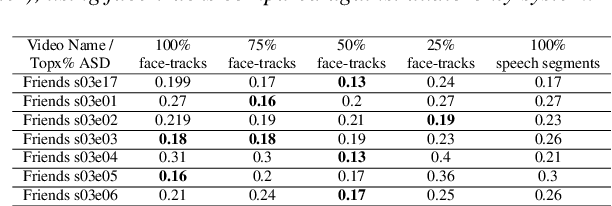
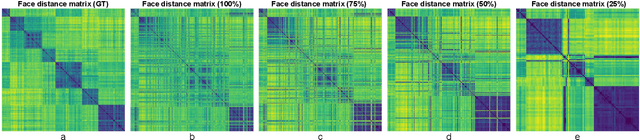
Speaker diarization is one of the critical components of computational media intelligence as it enables a character-level analysis of story portrayals and media content understanding. Automated audio-based speaker diarization of entertainment media poses challenges due to the diverse acoustic conditions present in media content, be it background music, overlapping speakers, or sound effects. At the same time, speaking faces in the visual modality provide complementary information and not prone to the errors seen in the audio modality. In this paper, we address the problem of speaker diarization in TV shows using the active speaker faces. We perform face clustering on the active speaker faces and show superior speaker diarization performance compared to the state-of-the-art audio-based diarization methods. We additionally report a systematic analysis of the impact of active speaker face detection quality on the diarization performance. We also observe that a moderately well-performing active speaker system could outperform the audio-based diarization systems.