 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Attentive Pooling for Extracting Speaker Embeddings from Multi-Speaker Recordings
Aug 30, 2024



This paper proposes a method for extracting speaker embedding for each speaker from a variable-length recording containing multiple speakers. Speaker embeddings are crucial not only for speaker recognition but also for various multi-speaker speech applications such as speaker diarization and target-speaker speech processing. Despite the challenges of obtaining a single speaker's speech without pre-registration in multi-speaker scenarios, most studies on speaker embedding extraction focus on extracting embeddings only from single-speaker recordings. Some methods have been proposed for extracting speaker embeddings directly from multi-speaker recordings, but they typically require preparing a model for each possible number of speakers or involve complicated training procedures. The proposed method computes the embeddings of multiple speakers by focusing on different parts of the frame-wise embeddings extracted from the input multi-speaker audio. This is achieved by recursively computing attention weights for pooling the frame-wise embeddings. Additionally, we propose using the calculated attention weights to estimate the number of speakers in the recording, which allows the same model to be applied to various numbers of speakers. Experimental evaluations demonstrate the effectiveness of the proposed method in speaker verification and diarization tasks.
SpeakerBeam-SS: Real-time Target Speaker Extraction with Lightweight Conv-TasNet and State Space Modeling
Jul 01, 2024


Real-time target speaker extraction (TSE) is intended to extract the desired speaker's voice from the observed mixture of multiple speakers in a streaming manner. Implementing real-time TSE is challenging as the computational complexity must be reduced to provide real-time operation. This work introduces to Conv-TasNet-based TSE a new architecture based on state space modeling (SSM) that has been shown to model long-term dependency effectively. Owing to SSM, fewer dilated convolutional layers are required to capture temporal dependency in Conv-TasNet, resulting in the reduction of model complexity. We also enlarge the window length and shift of the convolutional (TasNet) frontend encoder to reduce the computational cost further; the performance decline is compensated by over-parameterization of the frontend encoder. The proposed method reduces the real-time factor by 78% from the conventional causal Conv-TasNet-based TSE while matching its performance.
Factor-Conditioned Speaking-Style Captioning
Jun 27, 2024



This paper presents a novel speaking-style captioning method that generates diverse descriptions while accurately predicting speaking-style information. Conventional learning criteria directly use original captions that contain not only speaking-style factor terms but also syntax words, which disturbs learning speaking-style information. To solve this problem, we introduce factor-conditioned captioning (FCC), which first outputs a phrase representing speaking-style factors (e.g., gender, pitch, etc.), and then generates a caption to ensure the model explicitly learns speaking-style factors. We also propose greedy-then-sampling (GtS) decoding, which first predicts speaking-style factors deterministically to guarantee semantic accuracy, and then generates a caption based on factor-conditioned sampling to ensure diversity. Experiments show that FCC outperforms the original caption-based training, and with GtS, it generates more diverse captions while keeping style prediction performance.
Thresholding Data Shapley for Data Cleansing Using Multi-Armed Bandits
Feb 13, 2024



Data cleansing aims to improve model performance by removing a set of harmful instances from the training dataset. Data Shapley is a common theoretically guaranteed method to evaluate the contribution of each instance to model performance; however, it requires training on all subsets of the training data, which is computationally expensive. In this paper, we propose an iterativemethod to fast identify a subset of instances with low data Shapley values by using the thresholding bandit algorithm. We provide a theoretical guarantee that the proposed method can accurately select harmful instances if a sufficiently large number of iterations is conducted. Empirical evaluation using various models and datasets demonstrated that the proposed method efficiently improved the computational speed while maintaining the model performance.
Streaming Active Learning for Regression Problems Using Regression via Classification
Sep 02, 2023


One of the challenges in deploying a machine learning model is that the model's performance degrades as the operating environment changes. To maintain the performance, streaming active learning is used, in which the model is retrained by adding a newly annotated sample to the training dataset if the prediction of the sample is not certain enough. Although many streaming active learning methods have been proposed for classification, few efforts have been made for regression problems, which are often handled in the industrial field. In this paper, we propose to use the regression-via-classification framework for streaming active learning for regression. Regression-via-classification transforms regression problems into classification problems so that streaming active learning methods proposed for classification problems can be applied directly to regression problems. Experimental validation on four real data sets shows that the proposed method can perform regression with higher accuracy at the same annotation cost.
CAPTDURE: Captioned Sound Dataset of Single Sources
May 28, 2023
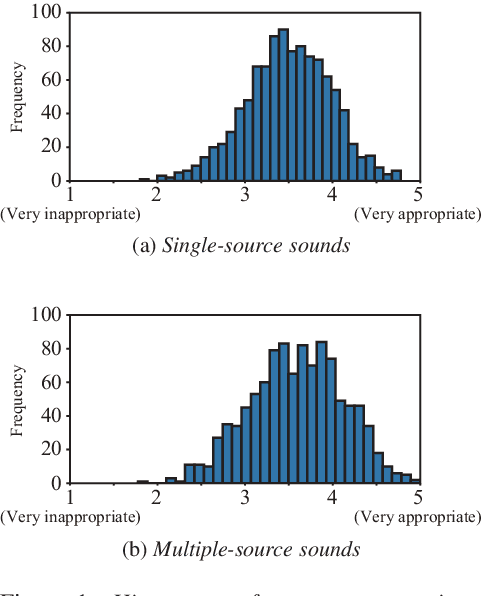
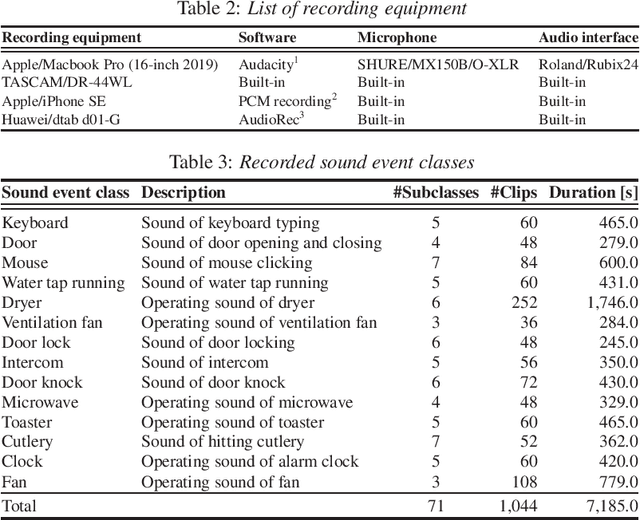
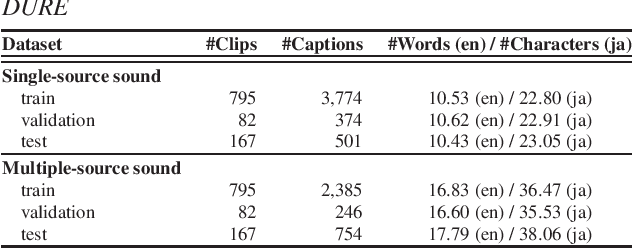
In conventional studies on environmental sound separation and synthesis using captions, datasets consisting of multiple-source sounds with their captions were used for model training. However, when we collect the captions for multiple-source sound, it is not easy to collect detailed captions for each sound source, such as the number of sound occurrences and timbre. Therefore, it is difficult to extract only the single-source target sound by the model-training method using a conventional captioned sound dataset. In this work, we constructed a dataset with captions for a single-source sound named CAPTDURE, which can be used in various tasks such as environmental sound separation and synthesis. Our dataset consists of 1,044 sounds and 4,902 captions. We evaluated the performance of environmental sound extraction using our dataset. The experimental results show that the captions for single-source sounds are effective in extracting only the single-source target sound from the mixture sound.
Spoofing Attacker Also Benefits from Self-Supervised Pretrained Model
May 24, 2023



Large-scale pretrained models using self-supervised learning have reportedly improved the performance of speech anti-spoofing. However, the attacker side may also make use of such models. Also, since it is very expensive to train such models from scratch, pretrained models on the Internet are often used, but the attacker and defender may possibly use the same pretrained model. This paper investigates whether the improvement in anti-spoofing with pretrained models holds under the condition that the models are available to attackers. As the attacker, we train a model that enhances spoofed utterances so that the speaker embedding extractor based on the pretrained models cannot distinguish between bona fide and spoofed utterances. Experimental results show that the gains the anti-spoofing models obtained by using the pretrained models almost disappear if the attacker also makes use of the pretrained models.
Mutual Learning of Single- and Multi-Channel End-to-End Neural Diarization
Oct 07, 2022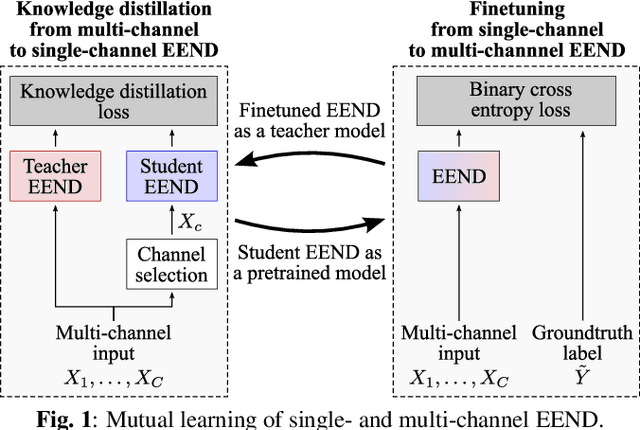
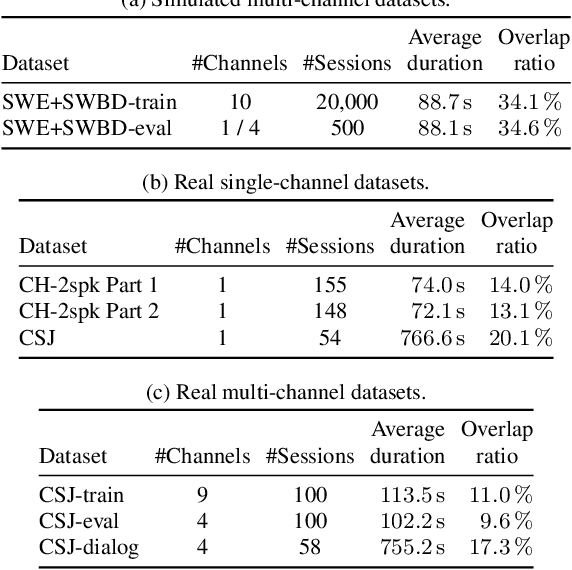
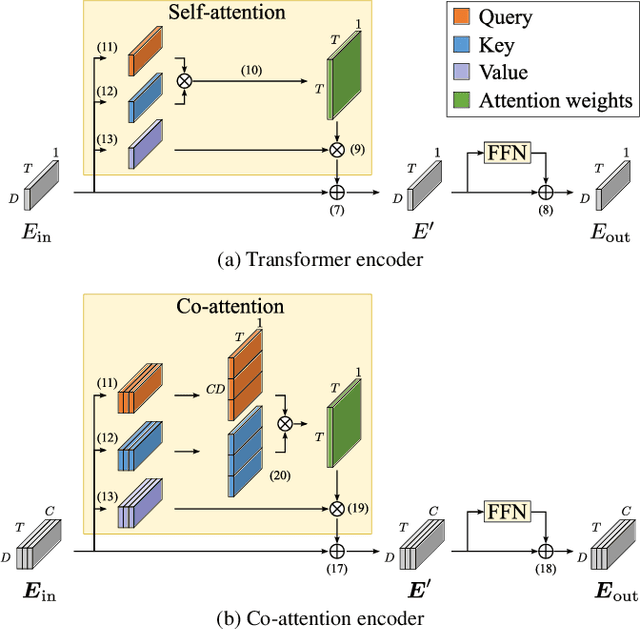
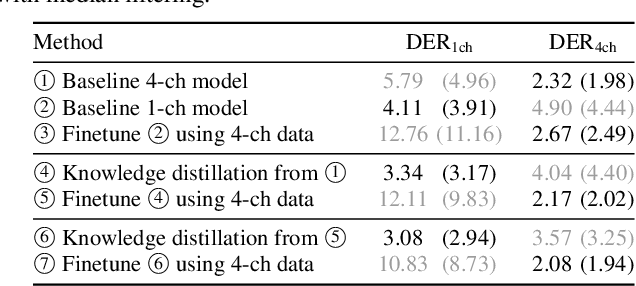
Due to the high performance of multi-channel speech processing, we can use the outputs from a multi-channel model as teacher labels when training a single-channel model with knowledge distillation. To the contrary, it is also known that single-channel speech data can benefit multi-channel models by mixing it with multi-channel speech data during training or by using it for model pretraining. This paper focuses on speaker diarization and proposes to conduct the above bi-directional knowledge transfer alternately. We first introduce an end-to-end neural diarization model that can handle both single- and multi-channel inputs. Using this model, we alternately conduct i) knowledge distillation from a multi-channel model to a single-channel model and ii) finetuning from the distilled single-channel model to a multi-channel model. Experimental results on two-speaker data show that the proposed method mutually improved single- and multi-channel speaker diarization performances.
Updating Only Encoders Prevents Catastrophic Forgetting of End-to-End ASR Models
Jul 01, 2022
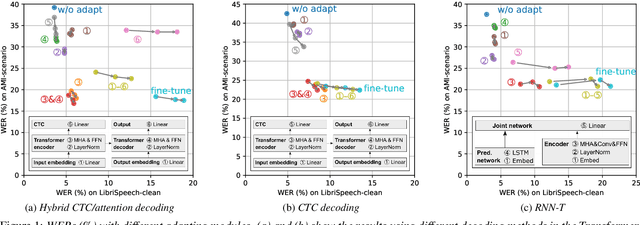
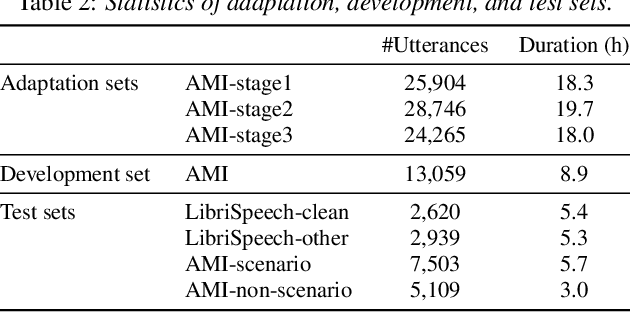
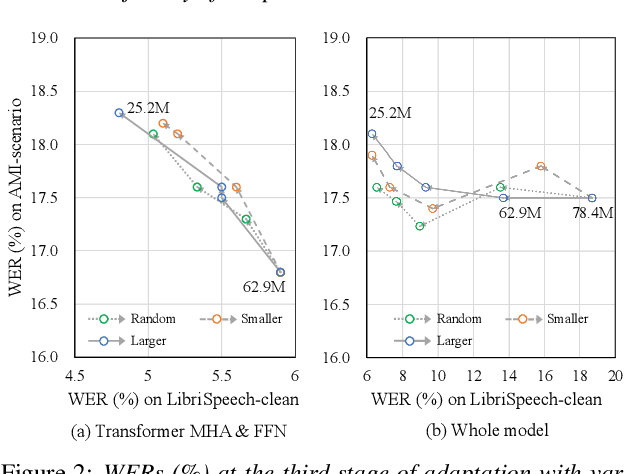
In this paper, we present an incremental domain adaptation technique to prevent catastrophic forgetting for an end-to-end automatic speech recognition (ASR) model. Conventional approaches require extra parameters of the same size as the model for optimization, and it is difficult to apply these approaches to end-to-end ASR models because they have a huge amount of parameters. To solve this problem, we first investigate which parts of end-to-end ASR models contribute to high accuracy in the target domain while preventing catastrophic forgetting. We conduct experiments on incremental domain adaptation from the LibriSpeech dataset to the AMI meeting corpus with two popular end-to-end ASR models and found that adapting only the linear layers of their encoders can prevent catastrophic forgetting. Then, on the basis of this finding, we develop an element-wise parameter selection focused on specific layers to further reduce the number of fine-tuning parameters. Experimental results show that our approach consistently prevents catastrophic forgetting compared to parameter selection from the whole model.
Online Neural Diarization of Unlimited Numbers of Speakers
Jun 06, 2022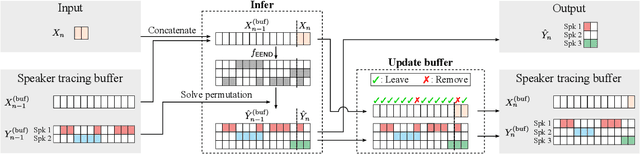
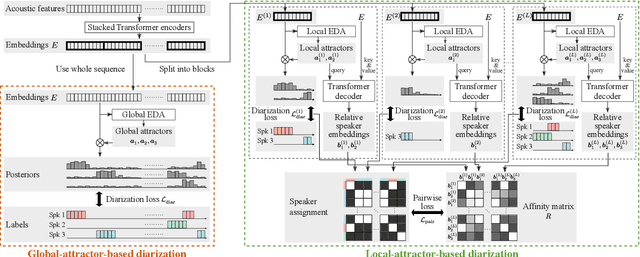
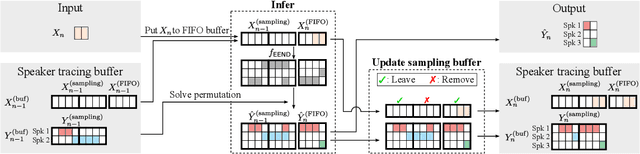
A method to perform offline and online speaker diarization for an unlimited number of speakers is described in this paper. End-to-end neural diarization (EEND) has achieved overlap-aware speaker diarization by formulating it as a multi-label classification problem. It has also been extended for a flexible number of speakers by introducing speaker-wise attractors. However, the output number of speakers of attractor-based EEND is empirically capped; it cannot deal with cases where the number of speakers appearing during inference is higher than that during training because its speaker counting is trained in a fully supervised manner. Our method, EEND-GLA, solves this problem by introducing unsupervised clustering into attractor-based EEND. In the method, the input audio is first divided into short blocks, then attractor-based diarization is performed for each block, and finally the results of each blocks are clustered on the basis of the similarity between locally-calculated attractors. While the number of output speakers is limited within each block, the total number of speakers estimated for the entire input can be higher than the limitation. To use EEND-GLA in an online manner, our method also extends the speaker-tracing buffer, which was originally proposed to enable online inference of conventional EEND. We introduces a block-wise buffer update to make the speaker-tracing buffer compatible with EEND-GLA. Finally, to improve online diarization, our method improves the buffer update method and revisits the variable chunk-size training of EEND. The experimental results demonstrate that EEND-GLA can perform speaker diarization of an unseen number of speakers in both offline and online inferences.