 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidance and Evaluation: Semantic-Aware Image Inpainting for Mixed Scenes
Mar 17, 2020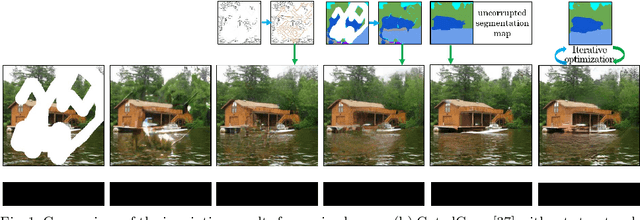
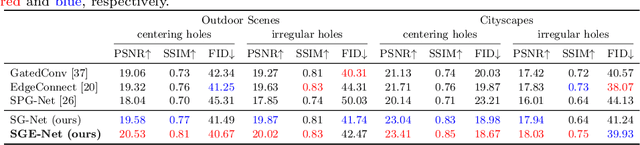
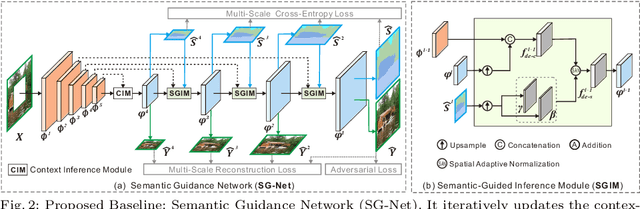

Completing a corrupted image with correct structures and reasonable textures for a mixed scene remains an elusive challenge. Since the missing hole in a mixed scene of a corrupted image often contains various semantic information, conventional two-stage approaches utilizing structural information often lead to the problem of unreliable structural prediction and ambiguous image texture generation. In this paper, we propose a Semantic Guidance and Evaluation Network (SGE-Net) to iteratively update the structural priors and the inpainted image in an interplay framework of semantics extraction and image inpainting. It utilizes semantic segmentation map as guidance in each scale of inpainting, under which location-dependent inferences are re-evaluated, and, accordingly, poorly-inferred regions are refined in subsequent scales. Extensive experiments on real-world images of mixed scenes demonstrated the superiority of our proposed method over state-of-the-art approaches, in terms of clear boundaries and photo-realistic textures.
Bridging the gap between AI and Healthcare sides: towards developing clinically relevant AI-powered diagnosis systems
Jan 12, 2020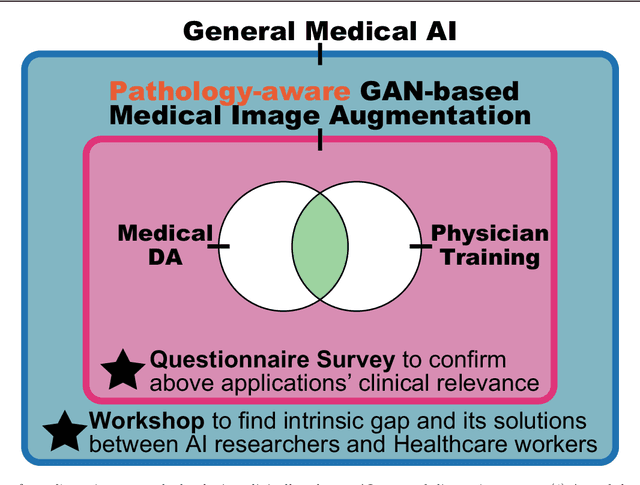

This work aims to identify/bridge the gap between Artificial Intelligence (AI) and Healthcare sides in Japan towards developing medical AI fitting into a clinical environment in five years. Moreover, we attempt to confirm the clinical relevance for diagnosis of our research-proven pathology-aware Generative Adversarial Network (GAN)-based medical image augmentation: a data wrangling and information conversion technique to address data paucity. We hold a clinically valuable AI-envisioning workshop among 2 Medical Imaging experts, 2 physicians, and 3 Healthcare/Informatics generalists. A qualitative/quantitative questionnaire survey for 3 project-related physicians and 6 project non-related radiologists evaluates the GAN projects in terms of Data Augmentation (DA) and physician training. The workshop reveals the intrinsic gap between AI/Healthcare sides and its preliminary solutions on Why (i.e., clinical significance/interpretation) and How (i.e., data acquisition, commercial deployment, and safety/feeling safe). The survey confirms our pathology-aware GANs' clinical relevance as a clinical decision support system and non-expert physician training tool. Radiologists generally have high expectations for AI-based diagnosis as a reliable second opinion and abnormal candidate detection, instead of replacing them. Our findings would play a key role in connecting inter-disciplinary research and clinical applications, not limited to the Japanese medical context and pathology-aware GANs. We find that better DA and expert physician training would require atypical image generation via further GAN-based extrapolation.
GAN-based Multiple Adjacent Brain MRI Slice Reconstruction for Unsupervised Alzheimer's Disease Diagnosis
Jul 08, 2019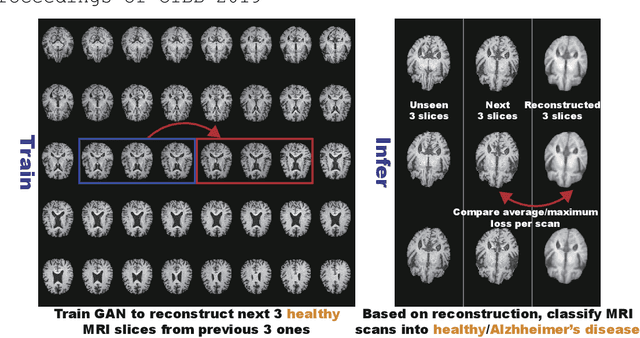
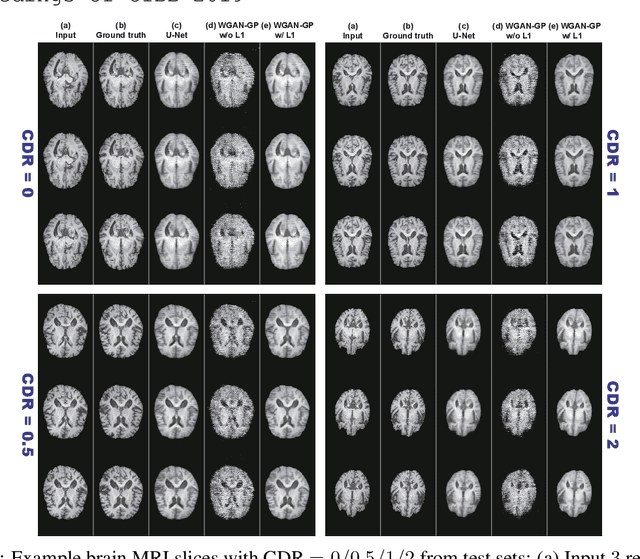
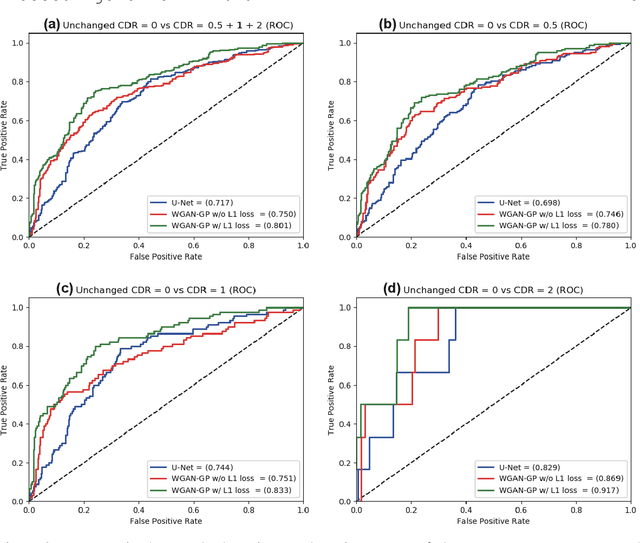
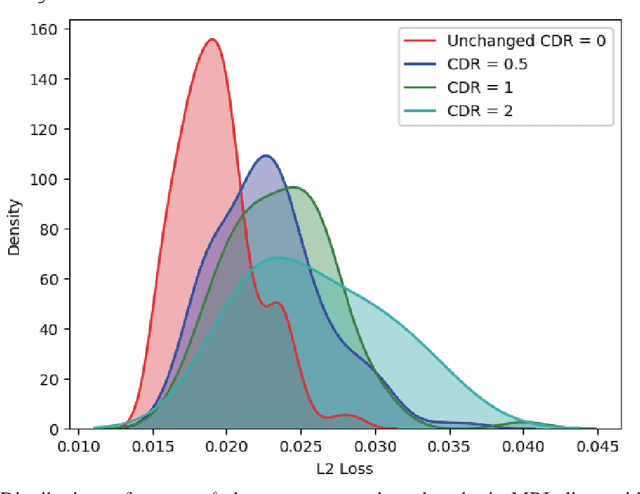
Unsupervised learning can discover various unseen diseases, relying on large-scale unannotated medical images of healthy subjects. Towards this, unsupervised methods reconstruct a single medical image to detect outliers either in the learned feature space or from high reconstruction loss. However, without considering continuity between multiple adjacent images, they cannot directly discriminate diseases composed of the accumulation of subtle anatomical anomalies, such as Alzheimer's Disease (AD). Moreover, no study shows how unsupervised anomaly detection is associated with disease stages. Therefore, we propose a two-step method using Generative Adversarial Network-based multiple adjacent brain MRI slice reconstruction to detect AD at various stages: (Reconstruction) Wasserstein loss with Gradient Penalty + L1 loss---trained on 3 healthy slices to reconstruct the next 3 ones---reconstructs unseen healthy/AD cases; (Diagnosis) Average/Maximum loss (e.g., L2 loss) per scan discriminates them, comparing the reconstructed/ground truth images. The results show that we can reliably detect AD at a very early stage with Area Under the Curve (AUC) 0.780 while also detecting AD at a late stage much more accurately with AUC 0.917; since our method is unsupervised, it should also discover and alert any anomalies including rare disease.
Beyond Intra-modality Discrepancy: A Comprehensive Survey of Heterogeneous Person Re-identification
May 24, 2019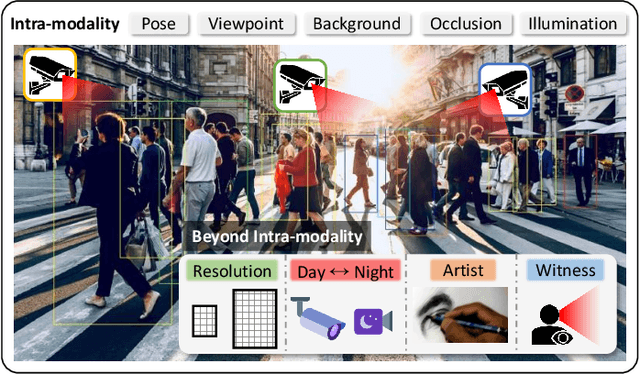
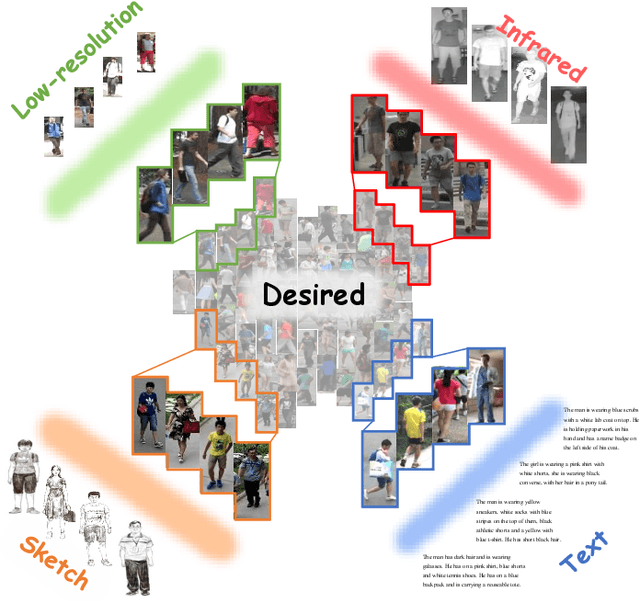
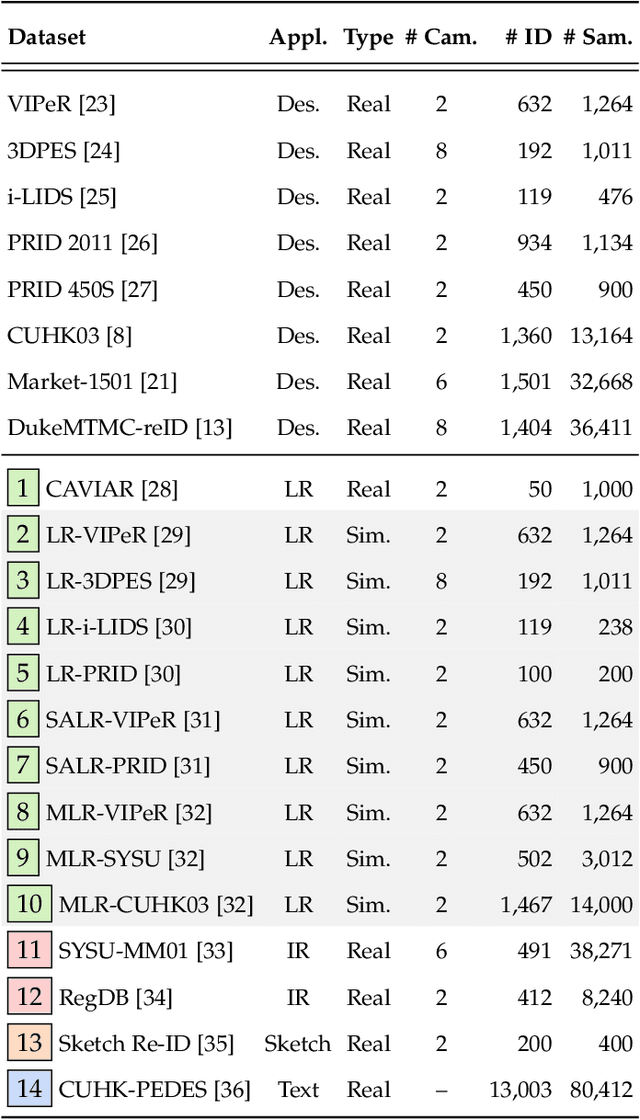

An effective and efficient person re-identification (ReID) algorithm will alleviate painful video watching, and accelerate the investigation progress. Recently, with the explosive requirements of practical applications, a lot of research efforts have been dedicated to heterogeneous person re-identification (He-ReID). In this paper, we review the state-of-the-art methods comprehensively with respect to four main application scenarios -- low-resolution, infrared, sketch and text. We begin with a comparison between He-ReID and the general Homogeneous ReID (Ho-ReID) task. Then, we survey the models that have been widely employed in He-ReID. Available existing datasets for performing evaluation are briefly described. We then summarize and compare the representative approaches. Finally, we discuss some future research directions.
Group Re-identification via Transferred Single and Couple Representation Learning
May 13, 2019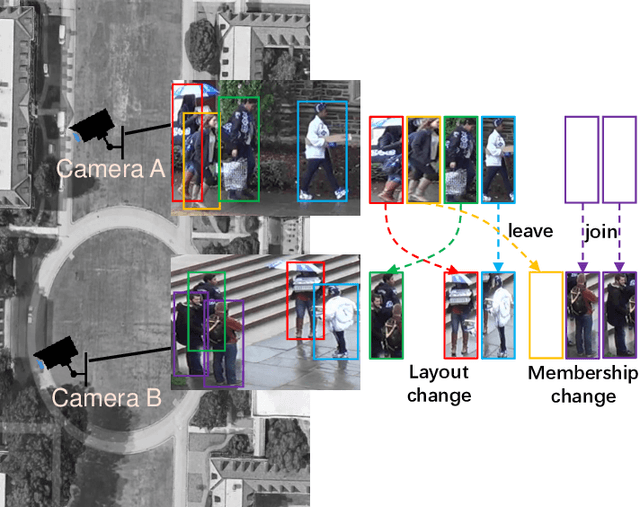
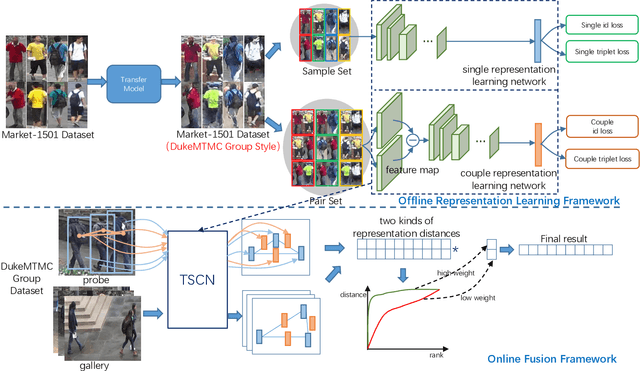
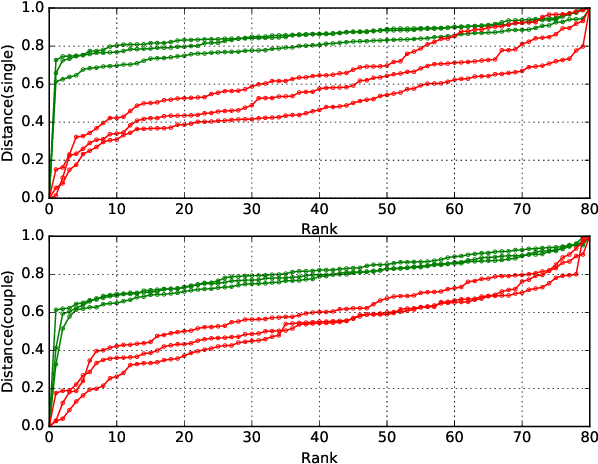

Group re-identification (G-ReID) is an important yet less-studied task. Its challenges not only lie in appearance changes of individuals which have been well-investigated in general person re-identification (ReID), but also derive from group layout and membership changes. So the key task of G-ReID is to learn representations robust to such changes. To address this issue, we propose a Transferred Single and Couple Representation Learning Network (TSCN). Its merits are two aspects: 1) Due to the lack of labelled training samples, existing G-ReID methods mainly rely on unsatisfactory hand-crafted features. To gain the superiority of deep learning models, we treat a group as multiple persons and transfer the domain of a labeled ReID dataset to a G-ReID target dataset style to learn single representations. 2) Taking into account the neighborhood relationship in a group, we further propose learning a novel couple representation between two group members, that achieves more discriminative power in G-ReID tasks. In addition, an unsupervised weight learning method is exploited to adaptively fuse the results of different views together according to result patterns. Extensive experimental results demonstrate the effectiveness of our approach that significantly outperforms state-of-the-art methods by 11.7\% CMC-1 on the Road Group dataset and by 39.0\% CMC-1 on the DukeMCMT dataset.
Illumination-Adaptive Person Re-identification
May 11, 2019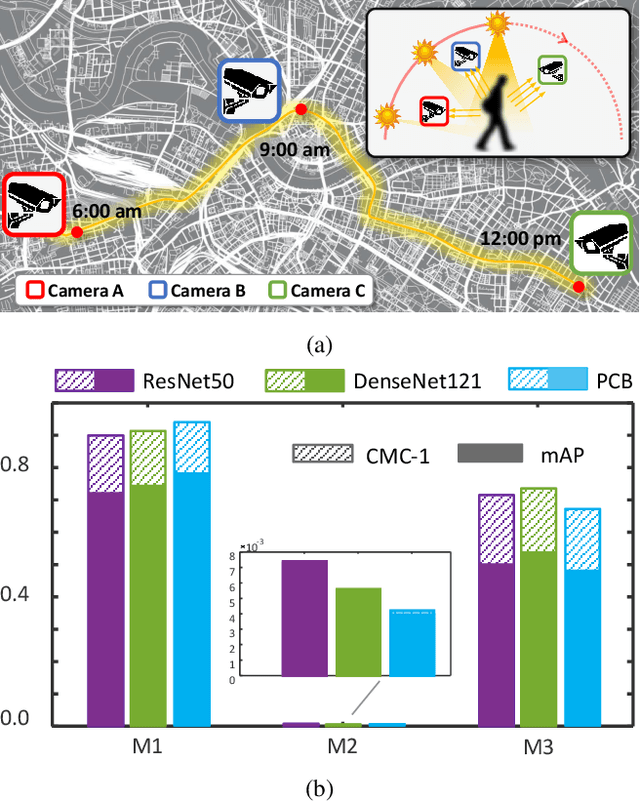
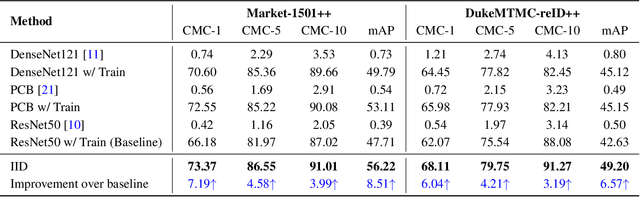
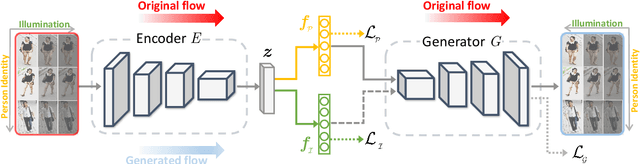

Most person re-identification (ReID) approaches assume that person images are captured under relatively similar illumination conditions. In reality, long-term person retrieval is common and person images are captured under different illumination conditions at different times across a day. In this situation, the performances of existing ReID models often degrade dramatically. This paper addresses the ReID problem with illumination variations and names it as {\em Illumination-Adaptive Person Re-identification (IA-ReID)}. We propose an Illumination-Identity Disentanglement (IID) network to separate different scales of illuminations apart, while preserving individuals' identity information. To demonstrate the illumination issue and to evaluate our network, we construct two large-scale simulated datasets with a wide range of illumination variations. Experimental results on the simulated datasets and real-world images demonstrate the effectiveness of the proposed framework.
Learning More with Less: GAN-based Medical Image Augmentation
May 07, 2019

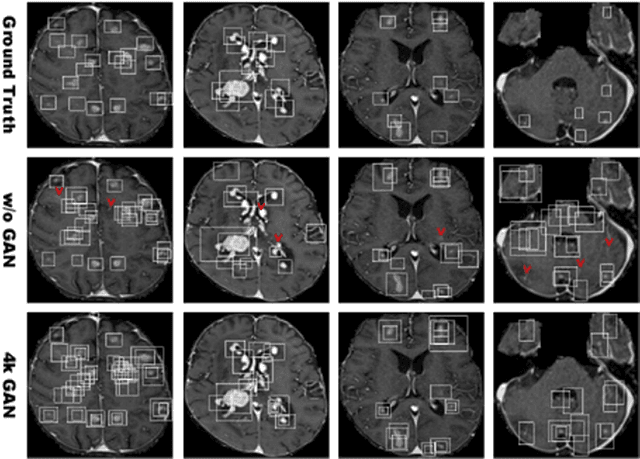
Convolutional Neural Network (CNN)-based accurate prediction typically requires large-scale annotated training data. In Medical Imaging, however, both obtaining medical data and annotating them by expert physicians are challenging; to overcome this lack of data, Data Augmentation (DA) using Generative Adversarial Networks (GANs) is essential, since they can synthesize additional annotated training data to handle small and fragmented medical images from various scanners--those generated images, realistic but completely novel, can further fill the real image distribution uncovered by the original dataset. As a tutorial, this paper introduces GAN-based Medical Image Augmentation, along with tricks to boost classification/object detection/segmentation performance using them, based on our experience and related work. Moreover, we show our first GAN-based DA work using automatic bounding box annotation, for robust CNN-based brain metastases detection on 256 x 256 MR images; GAN-based DA can boost 10% sensitivity in diagnosis with a clinically acceptable number of additional False Positives, even with highly-rough and inconsistent bounding boxes.
Learning More with Less: Conditional PGGAN-based Data Augmentation for Brain Metastases Detection Using Highly-Rough Annotation on MR Images
Mar 03, 2019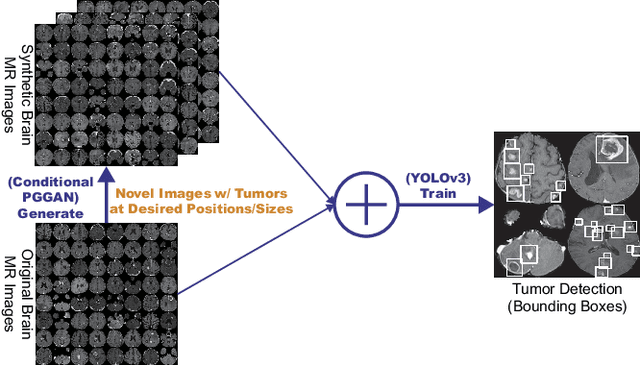
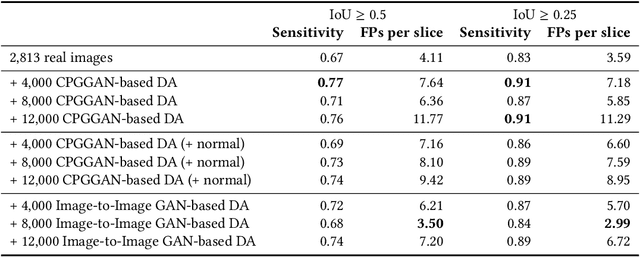

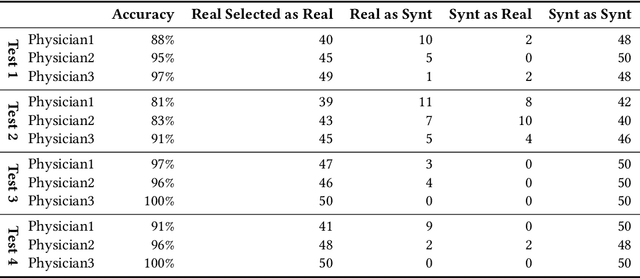
Accurate computer-assisted diagnosis can alleviate the risk of overlooking the diagnosis in a clinical environment. Towards this, as a Data Augmentation (DA) technique, Generative Adversarial Networks (GANs) can synthesize additional training data to handle small/fragmented medical images from various scanners; those images are realistic but completely different from the original ones, filling the data lack in the real image distribution. However, we cannot easily use them to locate the position of disease areas, considering expert physicians' annotation as time-expensive tasks. Therefore, this paper proposes Conditional Progressive Growing of GANs (CPGGANs), incorporating bounding box conditions into PGGANs to place brain metastases at desired position/size on 256 x 256 Magnetic Resonance (MR) images, for Convolutional Neural Network-based tumor detection; this first GAN-based medical DA using automatic bounding box annotation improves the robustness during training. The results show that CPGGAN-based DA can boost 10% sensitivity in diagnosis with an acceptable amount of additional False Positives---even with physicians' highly-rough and inconsistent bounding box annotation. Surprisingly, further realistic tumor appearance, achieved with additional normal brain MR images for CPGGAN training, does not contribute to detection performance, while even three expert physicians cannot accurately distinguish them from the real ones in Visual Turing Test.
Efficient Image Retrieval via Decoupling Diffusion into Online and Offline Processing
Nov 27, 2018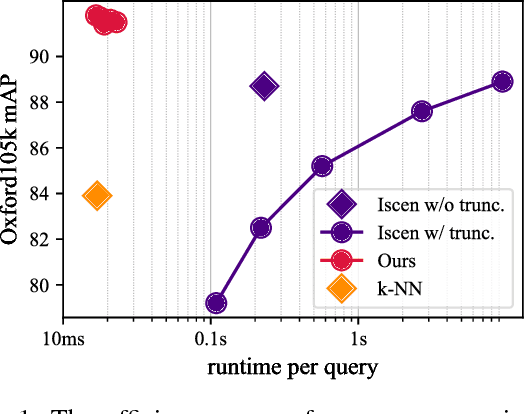
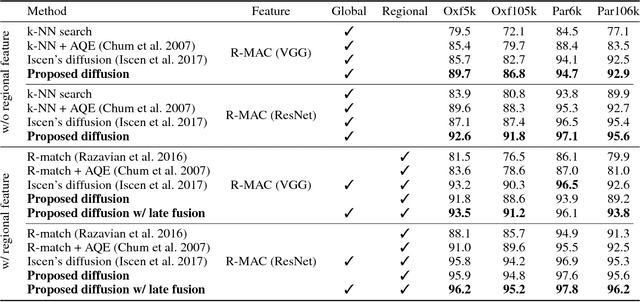
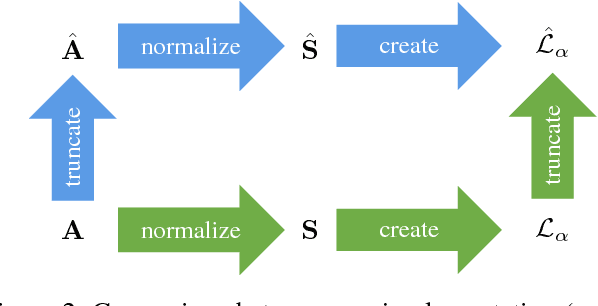
Diffusion is commonly used as a ranking or re-ranking method in retrieval tasks to achieve higher retrieval performance, and has attracted lots of attention in recent years. A downside to diffusion is that it performs slowly in comparison to the naive k-NN search, which causes a non-trivial online computational cost on large datasets. To overcome this weakness, we propose a novel diffusion technique in this paper. In our work, instead of applying diffusion to the query, we pre-compute the diffusion results of each element in the database, making the online search a simple linear combination on top of the k-NN search process. Our proposed method becomes 10~ times faster in terms of online search speed. Moreover, we propose to use late truncation instead of early truncation in previous works to achieve better retrieval performance.
Discriminative Learning of Open-Vocabulary Object Retrieval and Localization by Negative Phrase Augmentation
Sep 04, 2018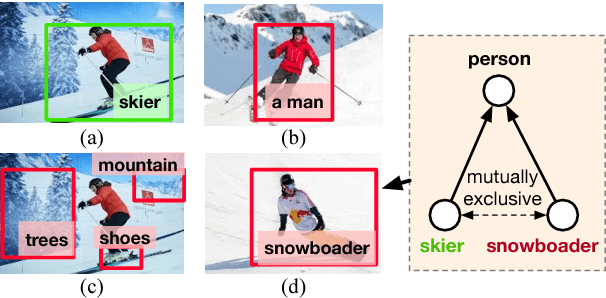
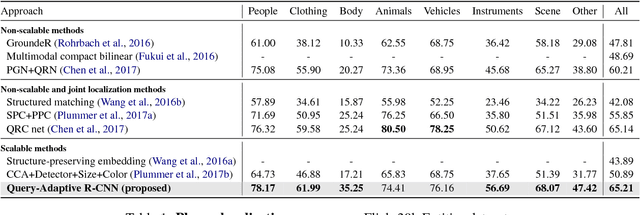
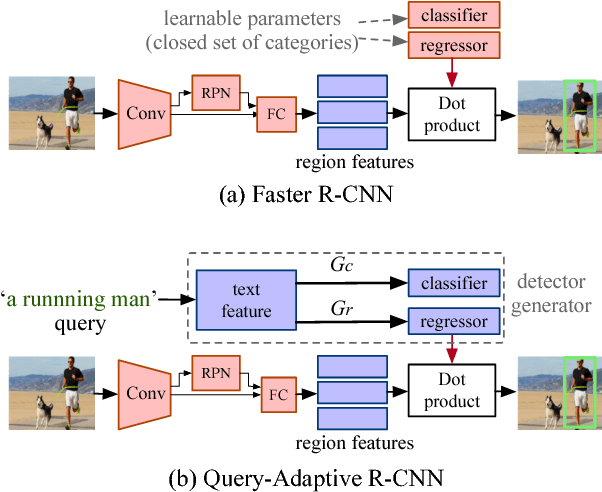
Thanks to the success of object detection technology, we can retrieve objects of the specified classes even from huge image collections. However, the current state-of-the-art object detectors (such as Faster R-CNN) can only handle pre-specified classes. In addition, large amounts of positive and negative visual samples are required for training. In this paper, we address the problem of open-vocabulary object retrieval and localization, where the target object is specified by a textual query (e.g., a word or phrase). We first propose Query-Adaptive R-CNN, a simple extension of Faster R-CNN adapted to open-vocabulary queries, by transforming the text embedding vector into an object classifier and localization regressor. Then, for discriminative training, we then propose negative phrase augmentation (NPA) to mine hard negative samples which are visually similar to the query and at the same time semantically mutually exclusive of the query. The proposed method can retrieve and localize objects specified by a textual query from one million images in only 0.5 seconds with high precision.