 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Unlearning Method Based On Projection Residual
Sep 30, 2022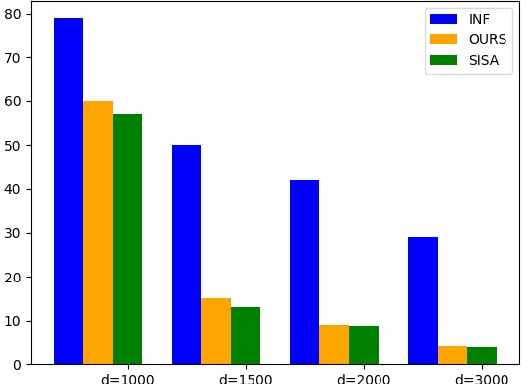
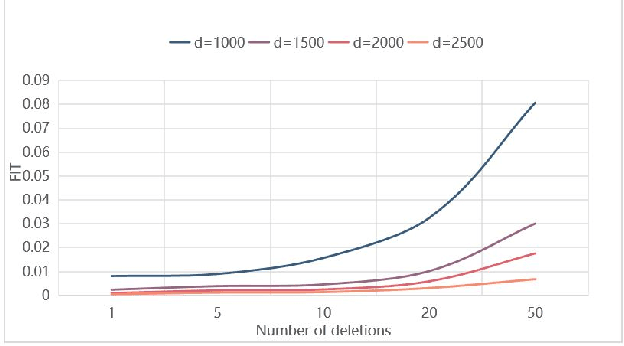
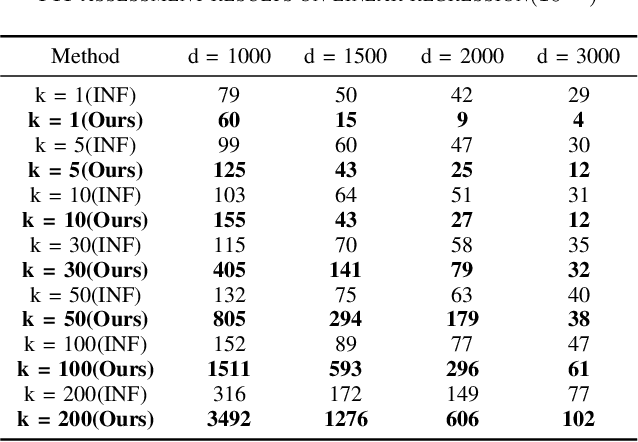

Machine learning models (mainly neural networks) are used more and more in real life. Users feed their data to the model for training. But these processes are often one-way. Once trained, the model remembers the data. Even when data is removed from the dataset, the effects of these data persist in the model. With more and more laws and regulations around the world protecting data privacy, it becomes even more important to make models forget this data completely through machine unlearning. This paper adopts the projection residual method based on Newton iteration method. The main purpose is to implement machine unlearning tasks in the context of linear regression models and neural network models. This method mainly uses the iterative weighting method to completely forget the data and its corresponding influence, and its computational cost is linear in the feature dimension of the data. This method can improve the current machine learning method. At the same time, it is independent of the size of the training set. Results were evaluated by feature injection testing (FIT). Experiments show that this method is more thorough in deleting data, which is close to model retraining.
Boosting Star-GANs for Voice Conversion with Contrastive Discriminator
Sep 27, 2022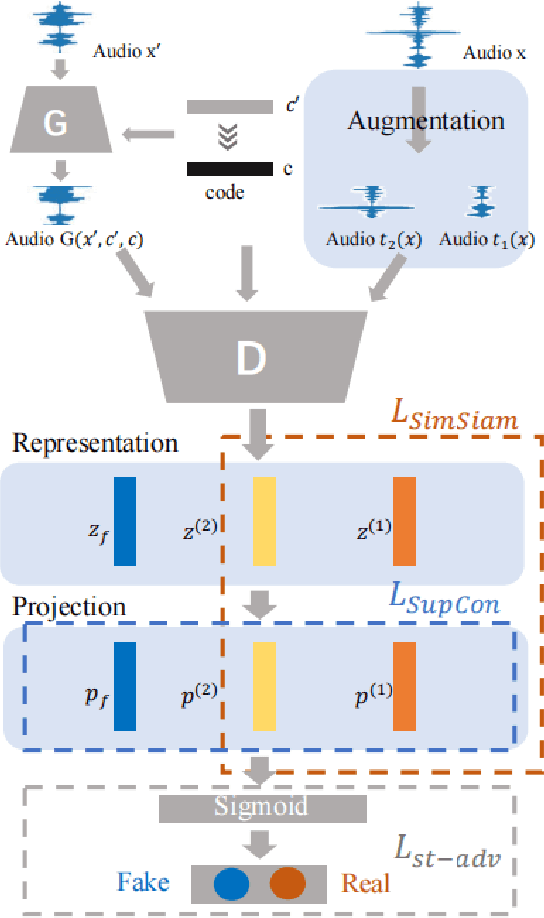


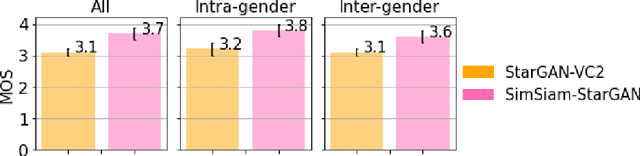
Nonparallel multi-domain voice conversion methods such as the StarGAN-VCs have been widely applied in many scenarios. However, the training of these models usually poses a challenge due to their complicated adversarial network architectures. To address this, in this work we leverage the state-of-the-art contrastive learning techniques and incorporate an efficient Siamese network structure into the StarGAN discriminator. Our method is called SimSiam-StarGAN-VC and it boosts the training stability and effectively prevents the discriminator overfitting issue in the training process. We conduct experiments on the Voice Conversion Challenge (VCC 2018) dataset, plus a user study to validate the performance of our framework. Our experimental results show that SimSiam-StarGAN-VC significantly outperforms existing StarGAN-VC methods in terms of both the objective and subjective metrics.
Debias the Black-box: A Fair Ranking Framework via Knowledge Distillation
Aug 24, 2022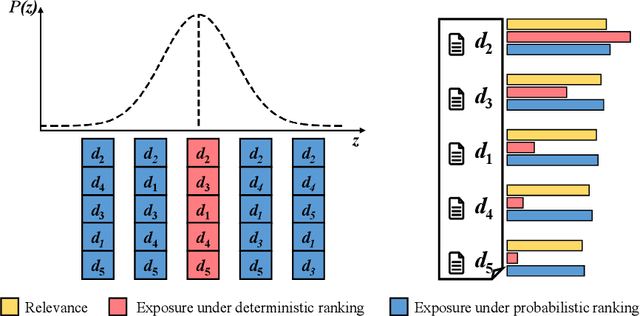
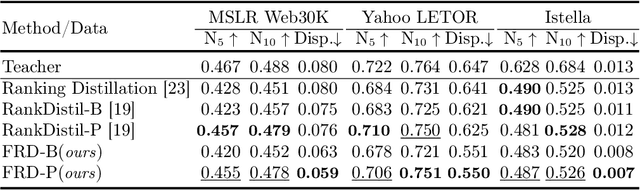
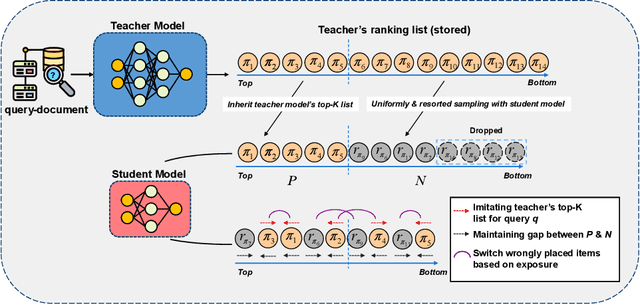
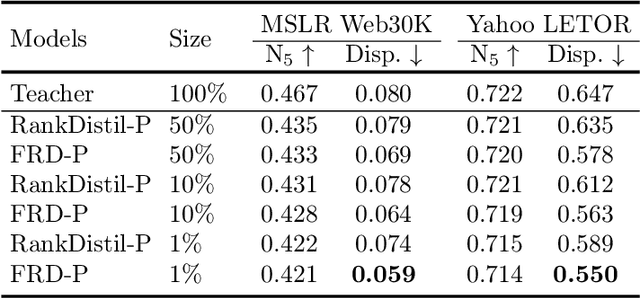
Deep neural networks can capture the intricate interaction history information between queries and documents, because of their many complicated nonlinear units, allowing them to provide correct search recommendations. However, service providers frequently face more complex obstacles in real-world circumstances, such as deployment cost constraints and fairness requirements. Knowledge distillation, which transfers the knowledge of a well-trained complex model (teacher) to a simple model (student), has been proposed to alleviate the former concern, but the best current distillation methods focus only on how to make the student model imitate the predictions of the teacher model. To better facilitate the application of deep models, we propose a fair information retrieval framework based on knowledge distillation. This framework can improve the exposure-based fairness of models while considerably decreasing model size. Our extensive experiments on three huge datasets show that our proposed framework can reduce the model size to a minimum of 1% of its original size while maintaining its black-box state. It also improves fairness performance by 15%~46% while keeping a high level of recommendation effectiveness.
Uncertainty Calibration for Deep Audio Classifiers
Jun 27, 2022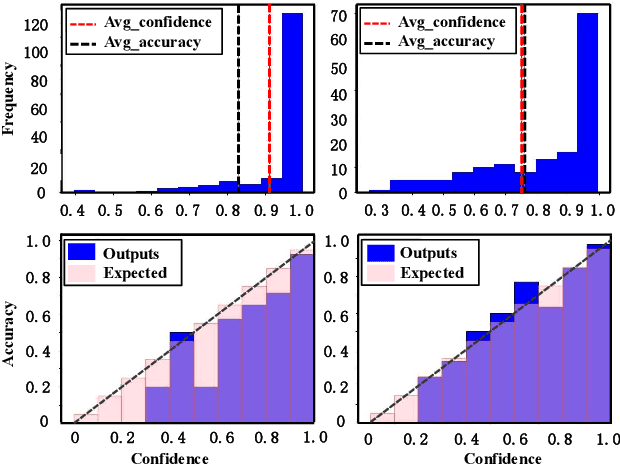
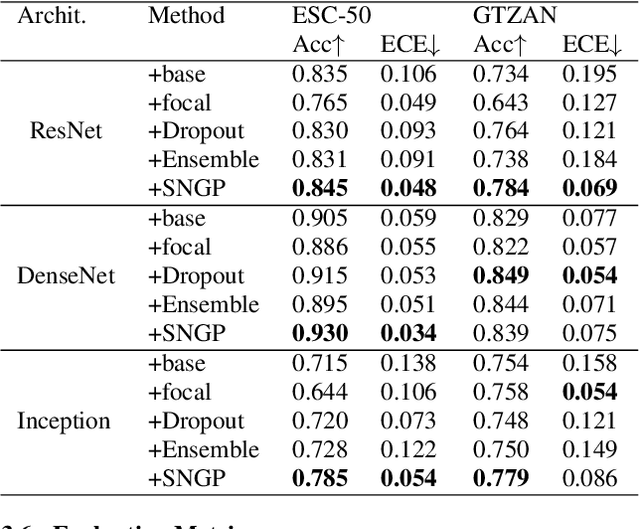
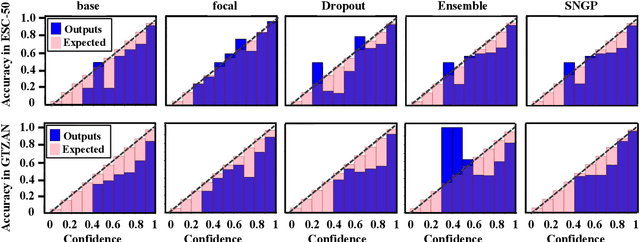
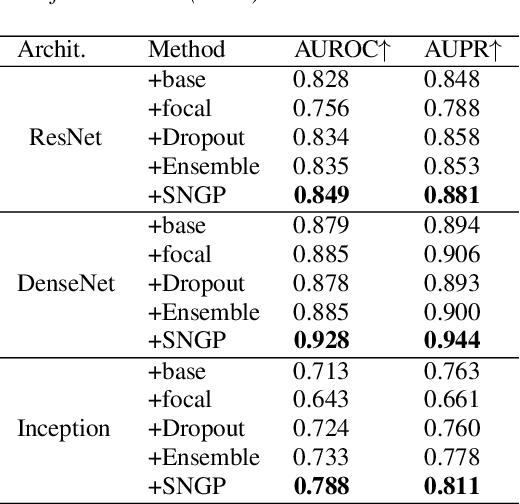
Although deep Neural Networks (DNNs) have achieved tremendous success in audio classification tasks, their uncertainty calibration are still under-explored. A well-calibrated model should be accurate when it is certain about its prediction and indicate high uncertainty when it is likely to be inaccurate. In this work, we investigate the uncertainty calibration for deep audio classifiers. In particular, we empirically study the performance of popular calibration methods: (i) Monte Carlo Dropout, (ii) ensemble, (iii) focal loss, and (iv) spectral-normalized Gaussian process (SNGP), on audio classification datasets. To this end, we evaluate (i-iv) for the tasks of environment sound and music genre classification. Results indicate that uncalibrated deep audio classifiers may be over-confident, and SNGP performs the best and is very efficient on the two datasets of this paper.
Leveraging Causal Inference for Explainable Automatic Program Repair
Jun 06, 2022
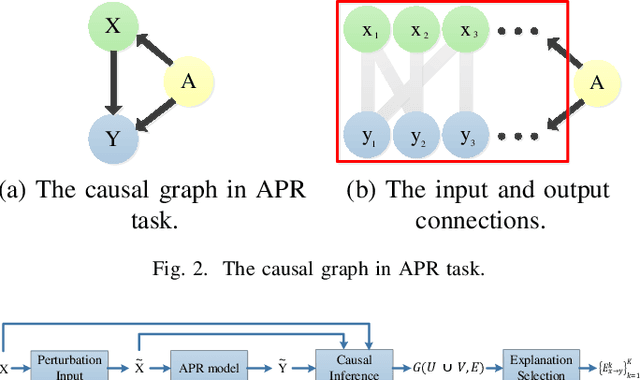
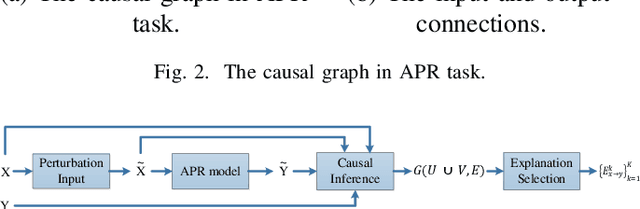
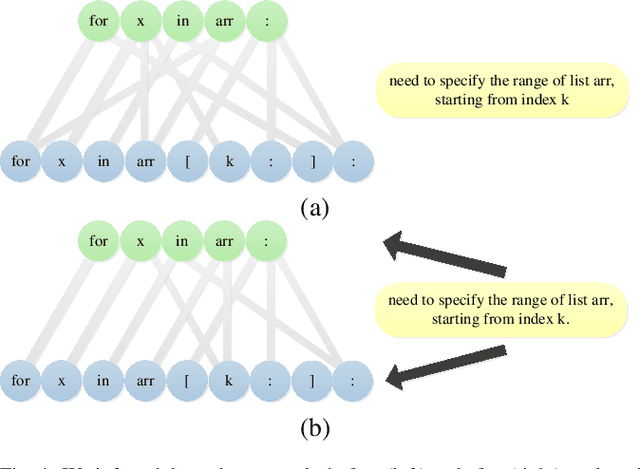
Deep learning models have made significant progress in automatic program repair. However, the black-box nature of these methods has restricted their practical applications. To address this challenge, this paper presents an interpretable approach for program repair based on sequence-to-sequence models with causal inference and our method is called CPR, short for causal program repair. Our CPR can generate explanations in the process of decision making, which consists of groups of causally related input-output tokens. Firstly, our method infers these relations by querying the model with inputs disturbed by data augmentation. Secondly, it generates a graph over tokens from the responses and solves a partitioning problem to select the most relevant components. The experiments on four programming languages (Java, C, Python, and JavaScript) show that CPR can generate causal graphs for reasonable interpretations and boost the performance of bug fixing in automatic program repair.
A Fair Federated Learning Framework With Reinforcement Learning
May 26, 2022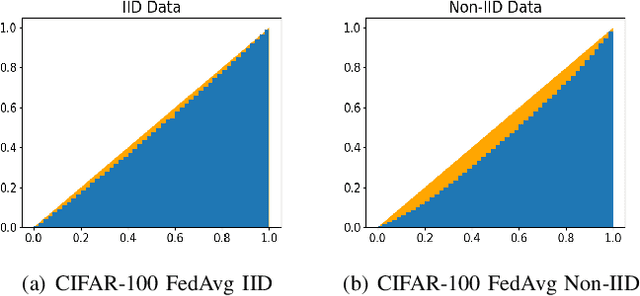
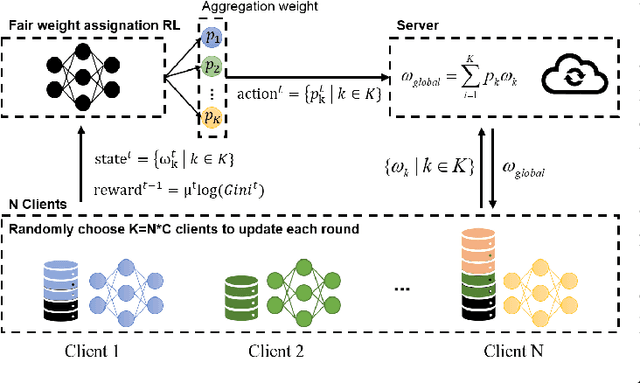
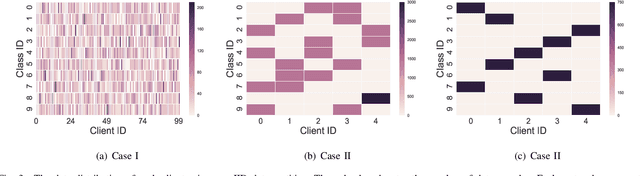
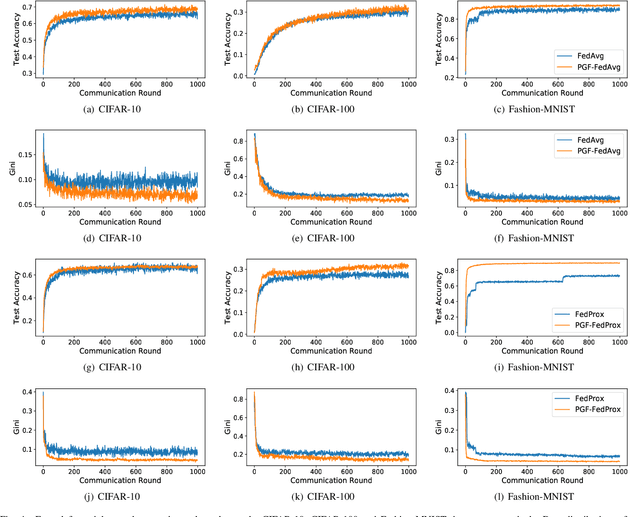
Federated learning (FL) is a paradigm where many clients collaboratively train a model under the coordination of a central server, while keeping the training data locally stored. However, heterogeneous data distributions over different clients remain a challenge to mainstream FL algorithms, which may cause slow convergence, overall performance degradation and unfairness of performance across clients. To address these problems, in this study we propose a reinforcement learning framework, called PG-FFL, which automatically learns a policy to assign aggregation weights to clients. Additionally, we propose to utilize Gini coefficient as the measure of fairness for FL. More importantly, we apply the Gini coefficient and validation accuracy of clients in each communication round to construct a reward function for the reinforcement learning. Our PG-FFL is also compatible to many existing FL algorithms. We conduct extensive experiments over diverse datasets to verify the effectiveness of our framework. The experimental results show that our framework can outperform baseline methods in terms of overall performance, fairness and convergence speed.
Federated Non-negative Matrix Factorization for Short Texts Topic Modeling with Mutual Information
May 26, 2022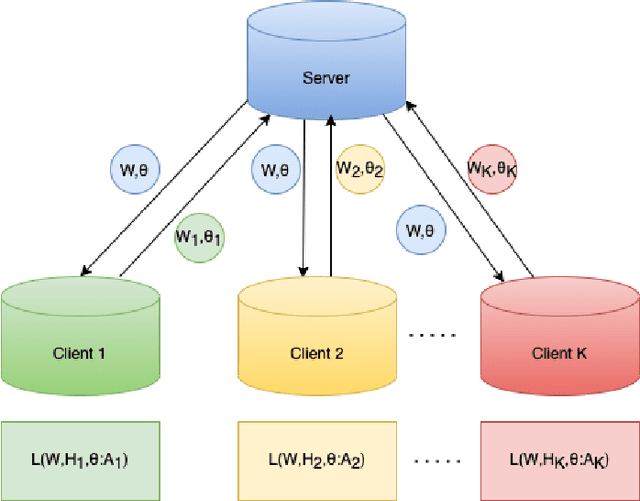
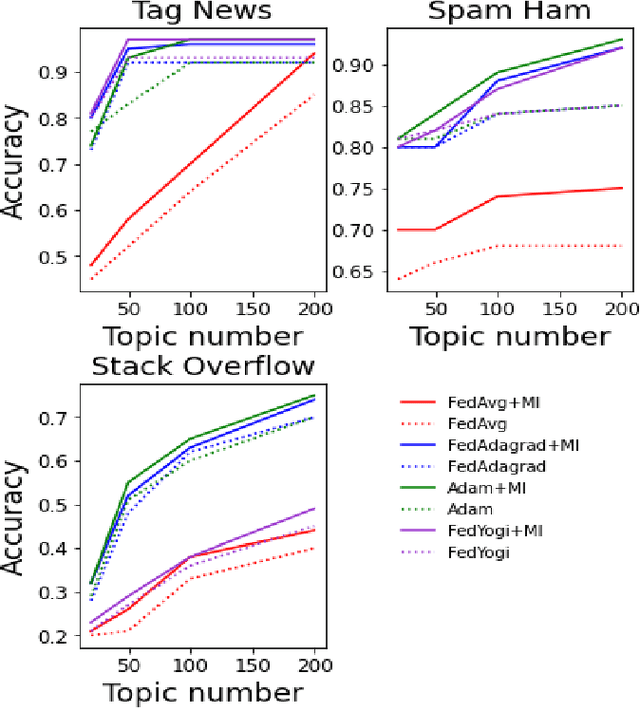
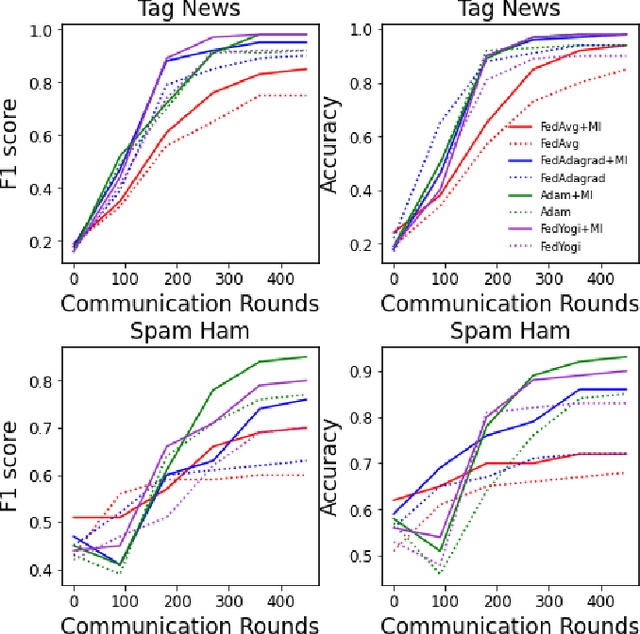
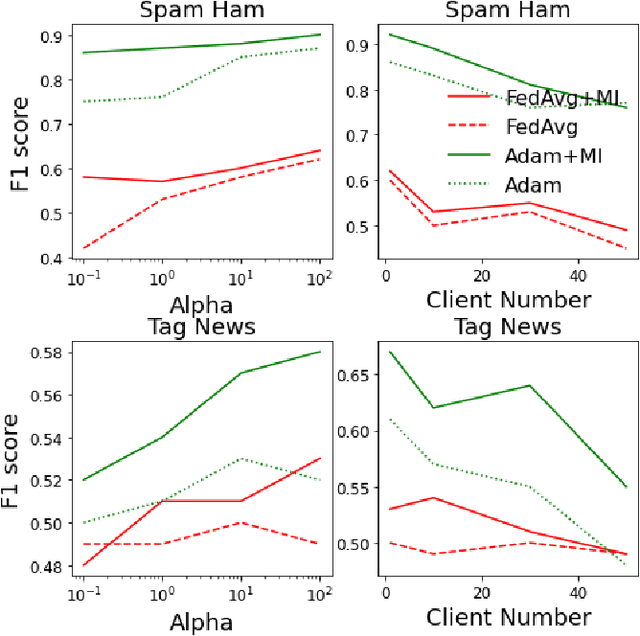
Non-negative matrix factorization (NMF) based topic modeling is widely used in natural language processing (NLP) to uncover hidden topics of short text documents. Usually, training a high-quality topic model requires large amount of textual data. In many real-world scenarios, customer textual data should be private and sensitive, precluding uploading to data centers. This paper proposes a Federated NMF (FedNMF) framework, which allows multiple clients to collaboratively train a high-quality NMF based topic model with locally stored data. However, standard federated learning will significantly undermine the performance of topic models in downstream tasks (e.g., text classification) when the data distribution over clients is heterogeneous. To alleviate this issue, we further propose FedNMF+MI, which simultaneously maximizes the mutual information (MI) between the count features of local texts and their topic weight vectors to mitigate the performance degradation. Experimental results show that our FedNMF+MI methods outperform Federated Latent Dirichlet Allocation (FedLDA) and the FedNMF without MI methods for short texts by a significant margin on both coherence score and classification F1 score.
* 7 pages, 4 figures, accepted by IJCNN 2022
Federated Split BERT for Heterogeneous Text Classification
May 26, 2022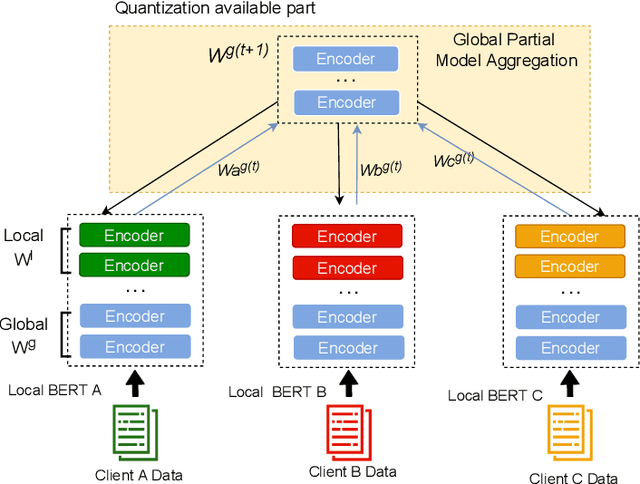
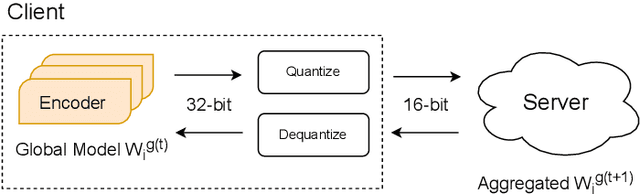
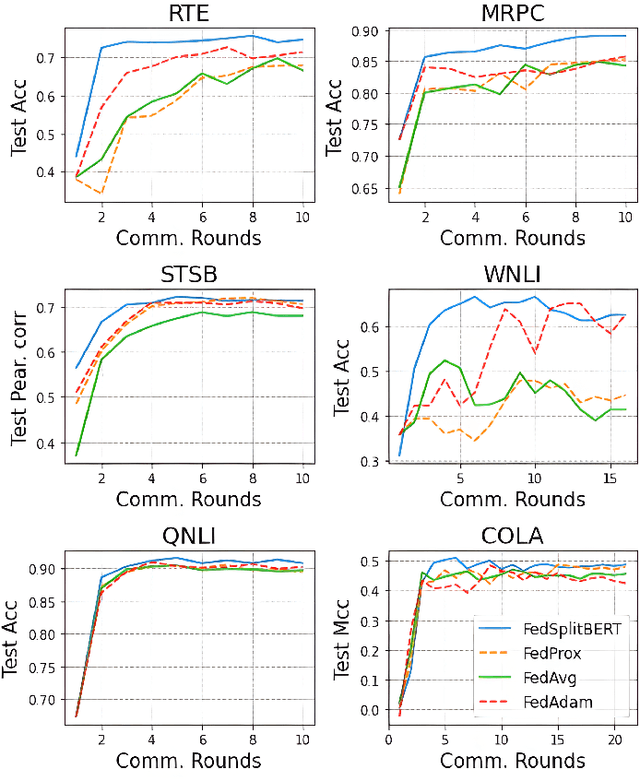
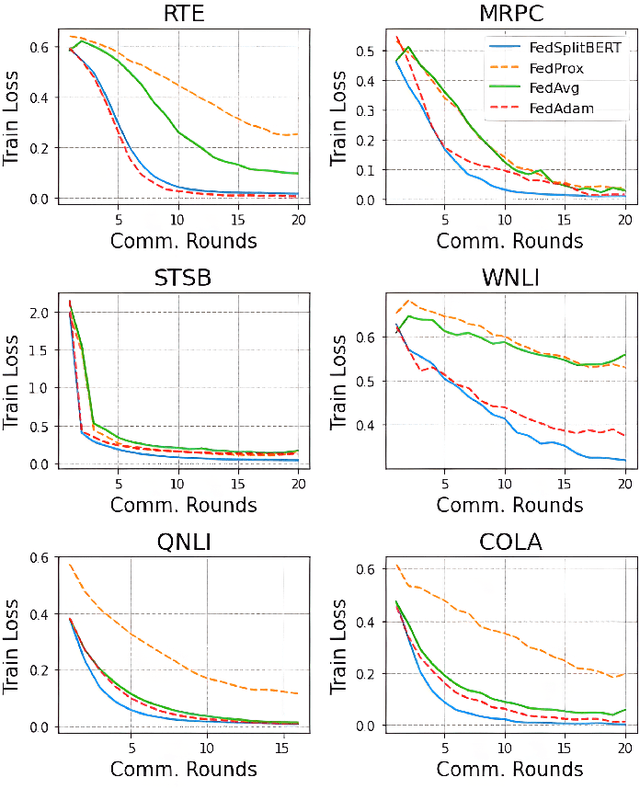
Pre-trained BERT models have achieved impressive performance in many natural language processing (NLP) tasks. However, in many real-world situations, textual data are usually decentralized over many clients and unable to be uploaded to a central server due to privacy protection and regulations. Federated learning (FL) enables multiple clients collaboratively to train a global model while keeping the local data privacy. A few researches have investigated BERT in federated learning setting, but the problem of performance loss caused by heterogeneous (e.g., non-IID) data over clients remain under-explored. To address this issue, we propose a framework, FedSplitBERT, which handles heterogeneous data and decreases the communication cost by splitting the BERT encoder layers into local part and global part. The local part parameters are trained by the local client only while the global part parameters are trained by aggregating gradients of multiple clients. Due to the sheer size of BERT, we explore a quantization method to further reduce the communication cost with minimal performance loss. Our framework is ready-to-use and compatible to many existing federated learning algorithms, including FedAvg, FedProx and FedAdam. Our experiments verify the effectiveness of the proposed framework, which outperforms baseline methods by a significant margin, while FedSplitBERT with quantization can reduce the communication cost by $11.9\times$.
Improving Human Image Synthesis with Residual Fast Fourier Transformation and Wasserstein Distance
May 26, 2022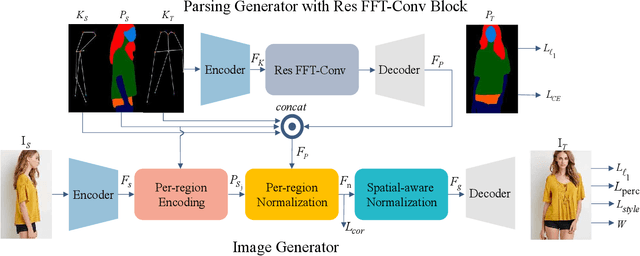
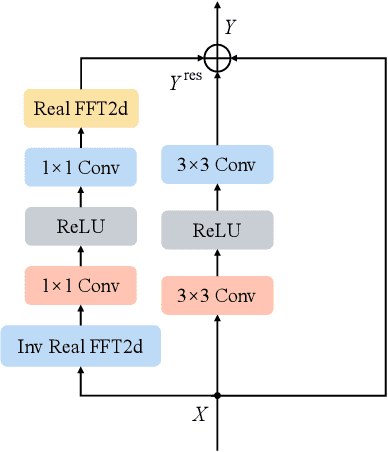
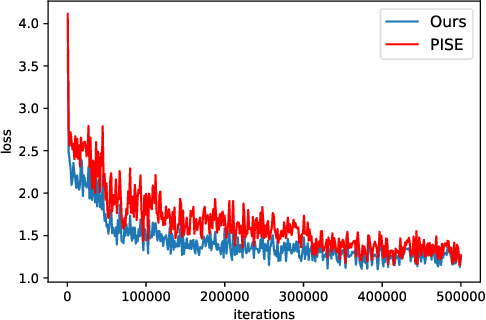
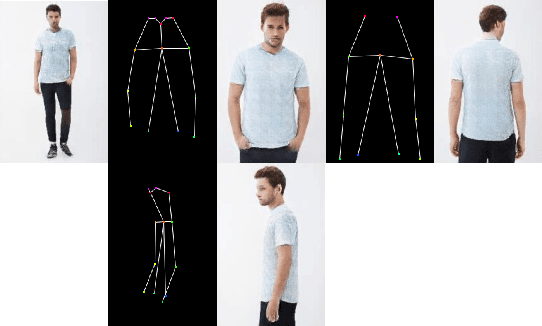
With the rapid development of the Metaverse, virtual humans have emerged, and human image synthesis and editing techniques, such as pose transfer, have recently become popular. Most of the existing techniques rely on GANs, which can generate good human images even with large variants and occlusions. But from our best knowledge, the existing state-of-the-art method still has the following problems: the first is that the rendering effect of the synthetic image is not realistic, such as poor rendering of some regions. And the second is that the training of GAN is unstable and slow to converge, such as model collapse. Based on the above two problems, we propose several methods to solve them. To improve the rendering effect, we use the Residual Fast Fourier Transform Block to replace the traditional Residual Block. Then, spectral normalization and Wasserstein distance are used to improve the speed and stability of GAN training. Experiments demonstrate that the methods we offer are effective at solving the problems listed above, and we get state-of-the-art scores in LPIPS and PSNR.
Augmentation-induced Consistency Regularization for Classification
May 26, 2022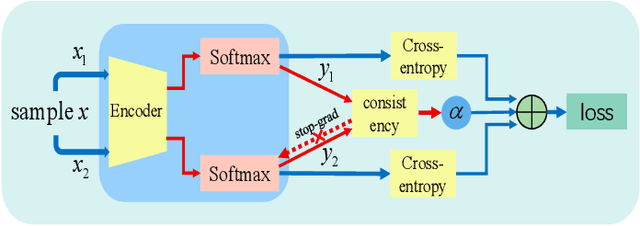
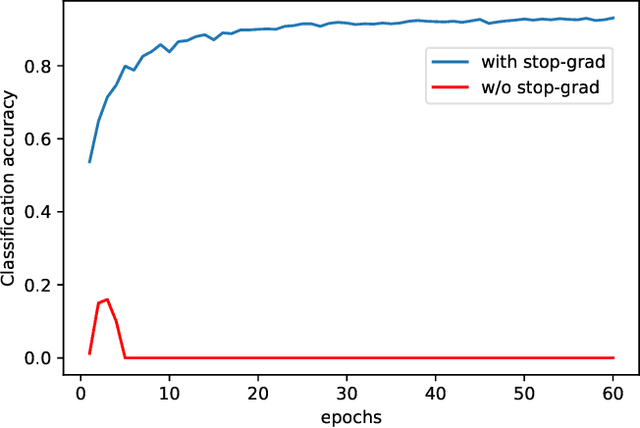
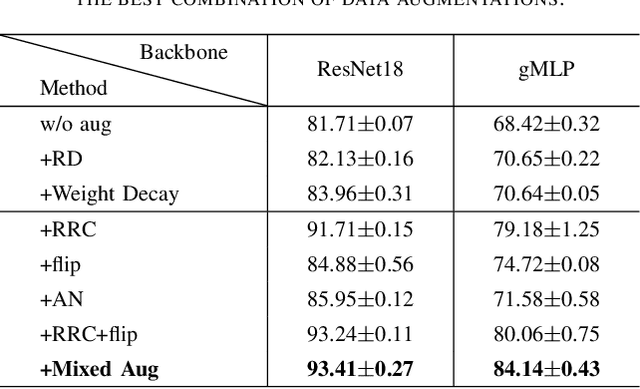
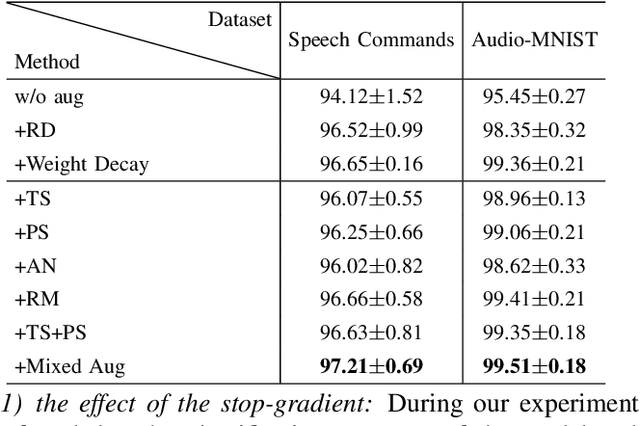
Deep neural networks have become popular in many supervised learning tasks, but they may suffer from overfitting when the training dataset is limited. To mitigate this, many researchers use data augmentation, which is a widely used and effective method for increasing the variety of datasets. However, the randomness introduced by data augmentation causes inevitable inconsistency between training and inference, which leads to poor improvement. In this paper, we propose a consistency regularization framework based on data augmentation, called CR-Aug, which forces the output distributions of different sub models generated by data augmentation to be consistent with each other. Specifically, CR-Aug evaluates the discrepancy between the output distributions of two augmented versions of each sample, and it utilizes a stop-gradient operation to minimize the consistency loss. We implement CR-Aug to image and audio classification tasks and conduct extensive experiments to verify its effectiveness in improving the generalization ability of classifiers. Our CR-Aug framework is ready-to-use, it can be easily adapted to many state-of-the-art network architectures. Our empirical results show that CR-Aug outperforms baseline methods by a significant margin.