 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic-to-Dance Generation with Optimal Transport
Dec 03, 2021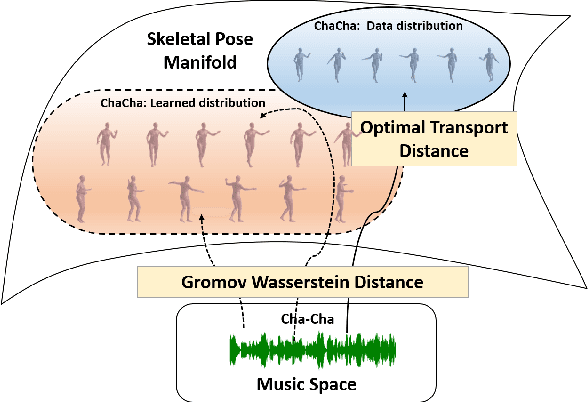
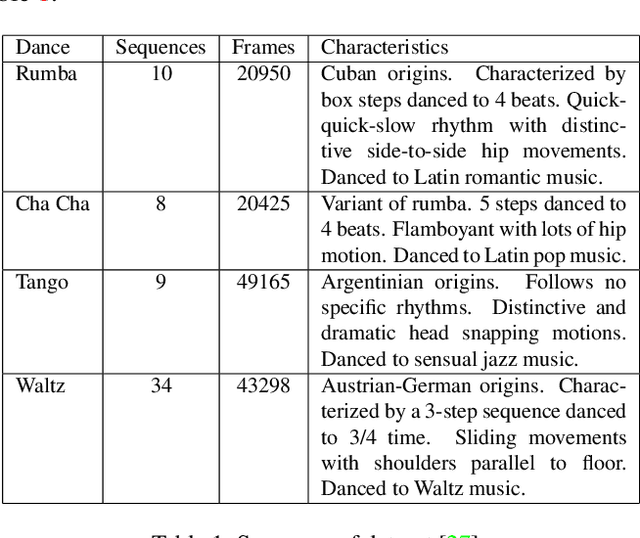
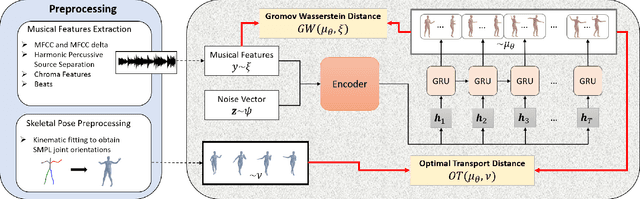
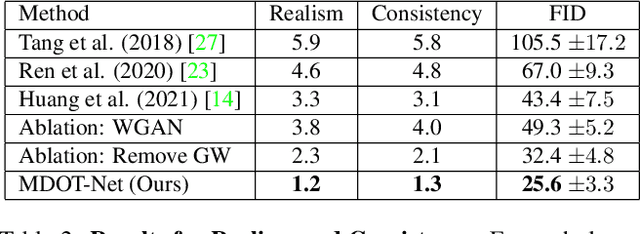
Dance choreography for a piece of music is a challenging task, having to be creative in presenting distinctive stylistic dance elements while taking into account the musical theme and rhythm. It has been tackled by different approaches such as similarity retrieval, sequence-to-sequence modeling and generative adversarial networks, but their generated dance sequences are often short of motion realism, diversity and music consistency. In this paper, we propose a Music-to-Dance with Optimal Transport Network (MDOT-Net) for learning to generate 3D dance choreographs from music. We introduce an optimal transport distance for evaluating the authenticity of the generated dance distribution and a Gromov-Wasserstein distance to measure the correspondence between the dance distribution and the input music. This gives a well defined and non-divergent training objective that mitigates the limitation of standard GAN training which is frequently plagued with instability and divergent generator loss issues. Extensive experiments demonstrate that our MDOT-Net can synthesize realistic and diverse dances which achieve an organic unity with the input music, reflecting the shared intentionality and matching the rhythmic articulation.
Model Adaptation: Historical Contrastive Learning for Unsupervised Domain Adaptation without Source Data
Oct 31, 2021
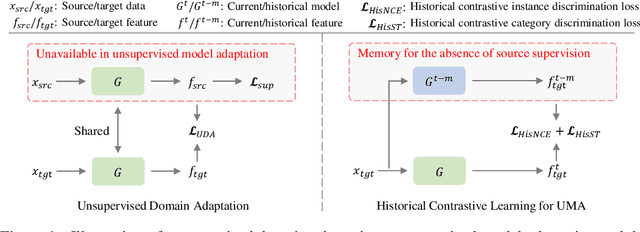
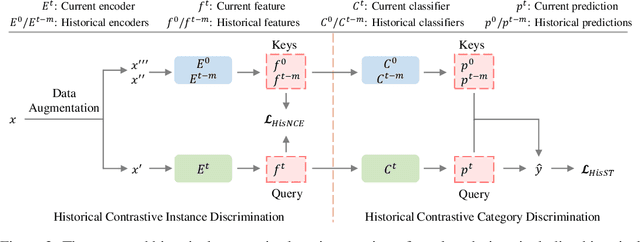
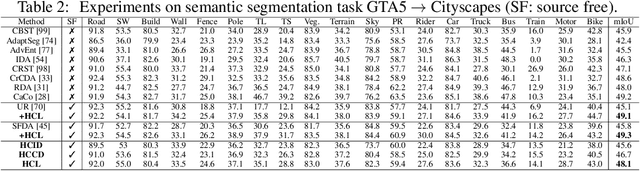
Unsupervised domain adaptation aims to align a labeled source domain and an unlabeled target domain, but it requires to access the source data which often raises concerns in data privacy, data portability and data transmission efficiency. We study unsupervised model adaptation (UMA), or called Unsupervised Domain Adaptation without Source Data, an alternative setting that aims to adapt source-trained models towards target distributions without accessing source data. To this end, we design an innovative historical contrastive learning (HCL) technique that exploits historical source hypothesis to make up for the absence of source data in UMA. HCL addresses the UMA challenge from two perspectives. First, it introduces historical contrastive instance discrimination (HCID) that learns from target samples by contrasting their embeddings which are generated by the currently adapted model and the historical models. With the historical models, HCID encourages UMA to learn instance-discriminative target representations while preserving the source hypothesis. Second, it introduces historical contrastive category discrimination (HCCD) that pseudo-labels target samples to learn category-discriminative target representations. Specifically, HCCD re-weights pseudo labels according to their prediction consistency across the current and historical models. Extensive experiments show that HCL outperforms and state-of-the-art methods consistently across a variety of visual tasks and setups.
GenCo: Generative Co-training on Data-Limited Image Generation
Oct 04, 2021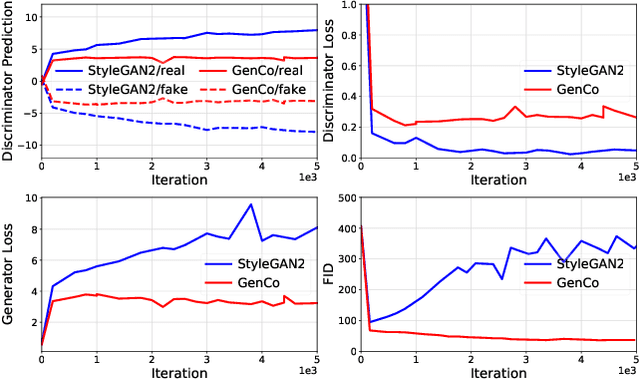
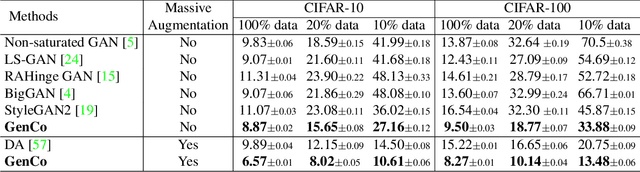
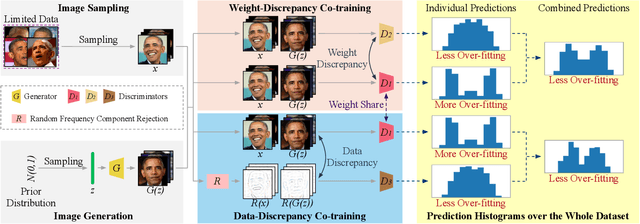
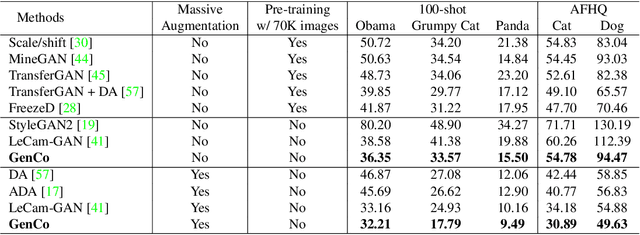
Training effective Generative Adversarial Networks (GANs) requires large amounts of training data, without which the trained models are usually sub-optimal with discriminator over-fitting. Several prior studies address this issue by expanding the distribution of the limited training data via massive and hand-crafted data augmentation. We handle data-limited image generation from a very different perspective. Specifically, we design GenCo, a Generative Co-training network that mitigates the discriminator over-fitting issue by introducing multiple complementary discriminators that provide diverse supervision from multiple distinctive views in training. We instantiate the idea of GenCo in two ways. The first way is Weight-Discrepancy Co-training (WeCo) which co-trains multiple distinctive discriminators by diversifying their parameters. The second way is Data-Discrepancy Co-training (DaCo) which achieves co-training by feeding discriminators with different views of the input images (e.g., different frequency components of the input images). Extensive experiments over multiple benchmarks show that GenCo achieves superior generation with limited training data. In addition, GenCo also complements the augmentation approach with consistent and clear performance gains when combined.
Unsupervised Domain Adaptive 3D Detection with Multi-Level Consistency
Aug 18, 2021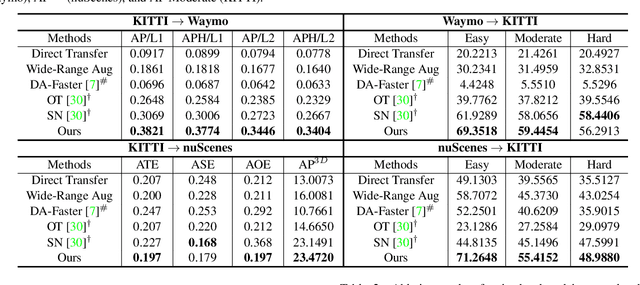
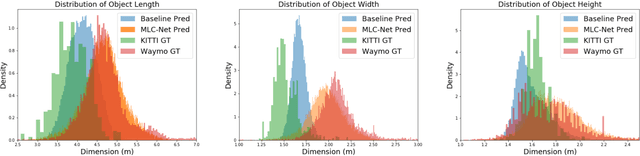
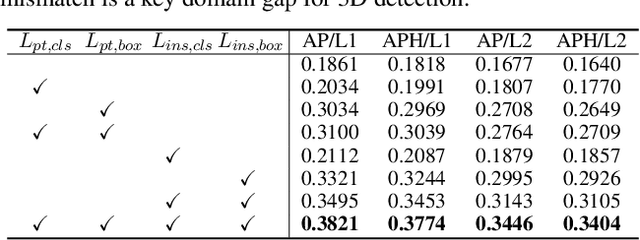
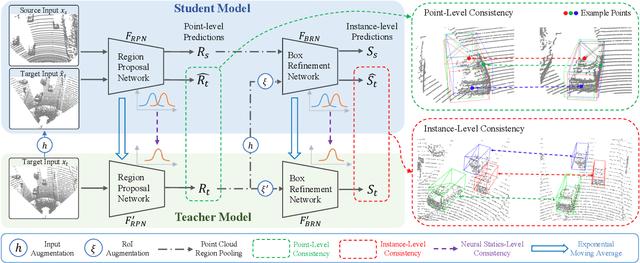
Deep learning-based 3D object detection has achieved unprecedented success with the advent of large-scale autonomous driving datasets. However, drastic performance degradation remains a critical challenge for cross-domain deployment. In addition, existing 3D domain adaptive detection methods often assume prior access to the target domain annotations, which is rarely feasible in the real world. To address this challenge, we study a more realistic setting, unsupervised 3D domain adaptive detection, which only utilizes source domain annotations. 1) We first comprehensively investigate the major underlying factors of the domain gap in 3D detection. Our key insight is that geometric mismatch is the key factor of domain shift. 2) Then, we propose a novel and unified framework, Multi-Level Consistency Network (MLC-Net), which employs a teacher-student paradigm to generate adaptive and reliable pseudo-targets. MLC-Net exploits point-, instance- and neural statistics-level consistency to facilitate cross-domain transfer. Extensive experiments demonstrate that MLC-Net outperforms existing state-of-the-art methods (including those using additional target domain information) on standard benchmarks. Notably, our approach is detector-agnostic, which achieves consistent gains on both single- and two-stage 3D detectors.
Skeleton Cloud Colorization for Unsupervised 3D Action Representation Learning
Aug 09, 2021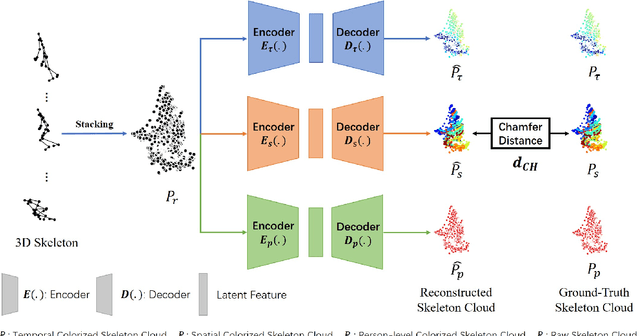
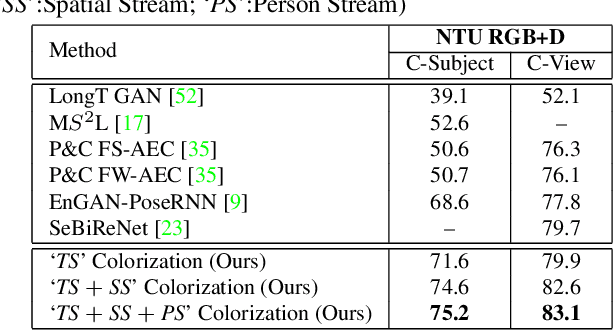
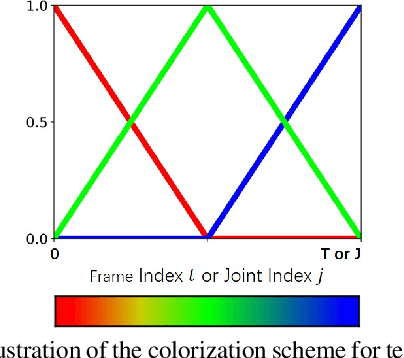
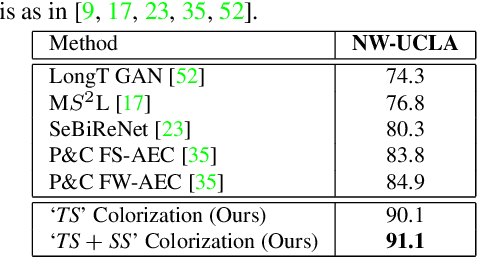
Skeleton-based human action recognition has attracted increasing attention in recent years. However, most of the existing works focus on supervised learning which requiring a large number of annotated action sequences that are often expensive to collect. We investigate unsupervised representation learning for skeleton action recognition, and design a novel skeleton cloud colorization technique that is capable of learning skeleton representations from unlabeled skeleton sequence data. Specifically, we represent a skeleton action sequence as a 3D skeleton cloud and colorize each point in the cloud according to its temporal and spatial orders in the original (unannotated) skeleton sequence. Leveraging the colorized skeleton point cloud, we design an auto-encoder framework that can learn spatial-temporal features from the artificial color labels of skeleton joints effectively. We evaluate our skeleton cloud colorization approach with action classifiers trained under different configurations, including unsupervised, semi-supervised and fully-supervised settings. Extensive experiments on NTU RGB+D and NW-UCLA datasets show that the proposed method outperforms existing unsupervised and semi-supervised 3D action recognition methods by large margins, and it achieves competitive performance in supervised 3D action recognition as well.
WaveFill: A Wavelet-based Generation Network for Image Inpainting
Jul 23, 2021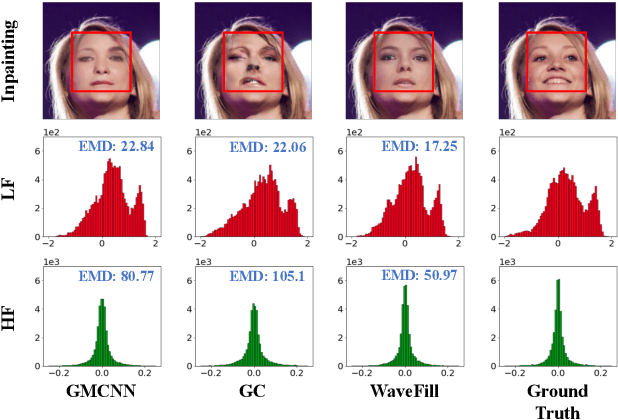
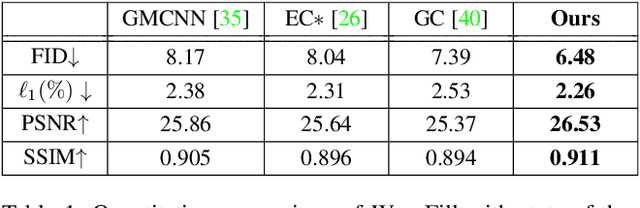
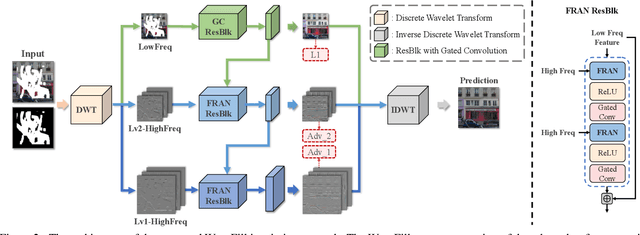
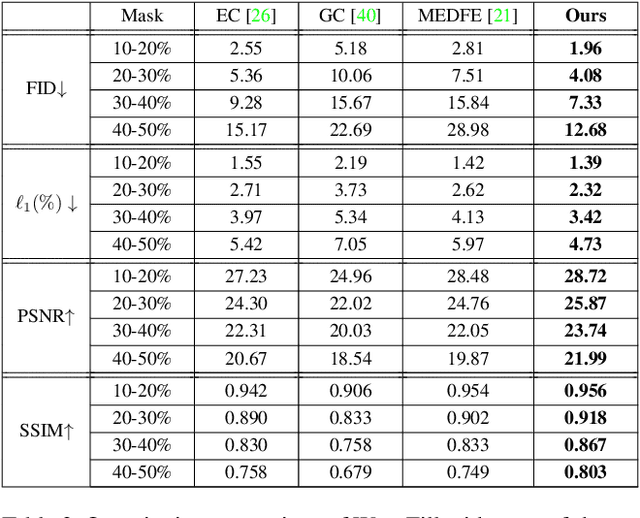
Image inpainting aims to complete the missing or corrupted regions of images with realistic contents. The prevalent approaches adopt a hybrid objective of reconstruction and perceptual quality by using generative adversarial networks. However, the reconstruction loss and adversarial loss focus on synthesizing contents of different frequencies and simply applying them together often leads to inter-frequency conflicts and compromised inpainting. This paper presents WaveFill, a wavelet-based inpainting network that decomposes images into multiple frequency bands and fills the missing regions in each frequency band separately and explicitly. WaveFill decomposes images by using discrete wavelet transform (DWT) that preserves spatial information naturally. It applies L1 reconstruction loss to the decomposed low-frequency bands and adversarial loss to high-frequency bands, hence effectively mitigate inter-frequency conflicts while completing images in spatial domain. To address the inpainting inconsistency in different frequency bands and fuse features with distinct statistics, we design a novel normalization scheme that aligns and fuses the multi-frequency features effectively. Extensive experiments over multiple datasets show that WaveFill achieves superior image inpainting qualitatively and quantitatively.
Domain Adaptive Video Segmentation via Temporal Consistency Regularization
Jul 23, 2021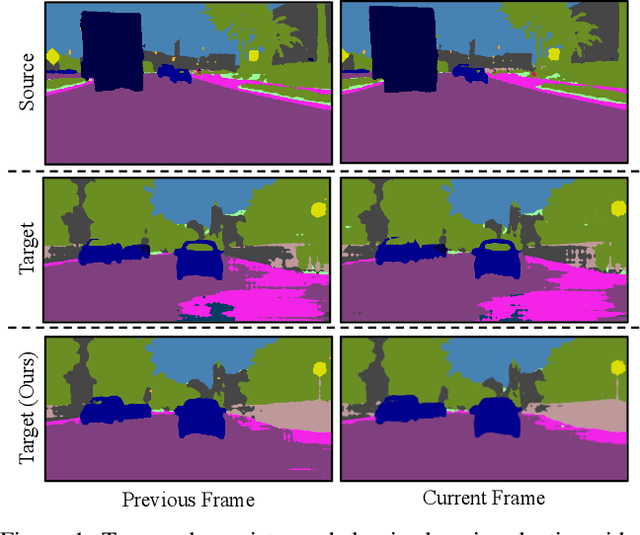

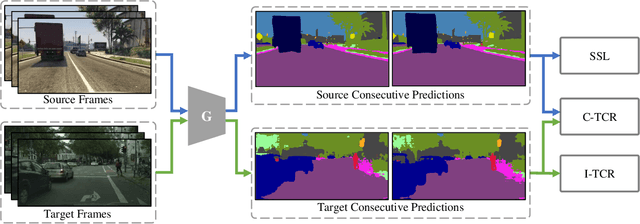

Video semantic segmentation is an essential task for the analysis and understanding of videos. Recent efforts largely focus on supervised video segmentation by learning from fully annotated data, but the learnt models often experience clear performance drop while applied to videos of a different domain. This paper presents DA-VSN, a domain adaptive video segmentation network that addresses domain gaps in videos by temporal consistency regularization (TCR) for consecutive frames of target-domain videos. DA-VSN consists of two novel and complementary designs. The first is cross-domain TCR that guides the prediction of target frames to have similar temporal consistency as that of source frames (learnt from annotated source data) via adversarial learning. The second is intra-domain TCR that guides unconfident predictions of target frames to have similar temporal consistency as confident predictions of target frames. Extensive experiments demonstrate the superiority of our proposed domain adaptive video segmentation network which outperforms multiple baselines consistently by large margins.
SynLiDAR: Learning From Synthetic LiDAR Sequential Point Cloud for Semantic Segmentation
Jul 12, 2021
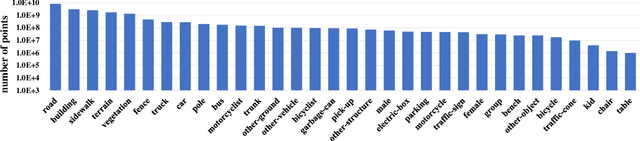
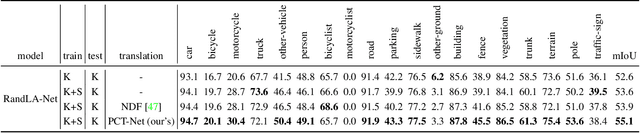
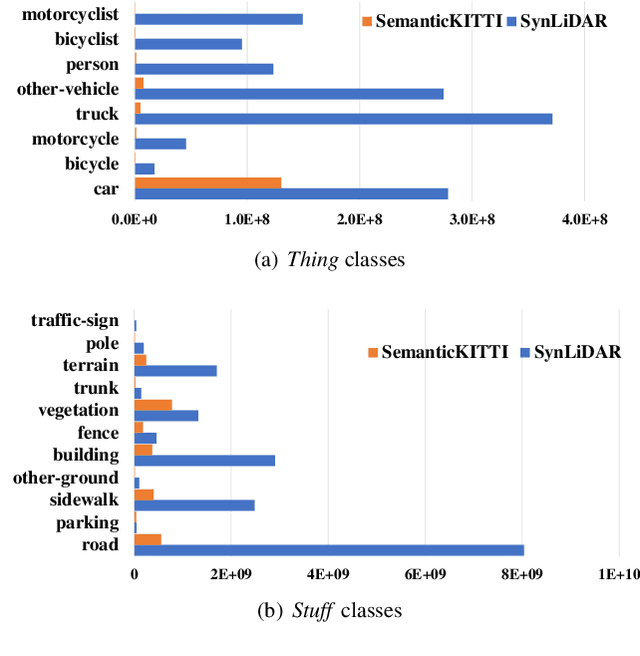
Transfer learning from synthetic to real data has been proved an effective way of mitigating data annotation constraints in various computer vision tasks. However, the developments focused on 2D images but lag far behind for 3D point clouds due to the lack of large-scale high-quality synthetic point cloud data and effective transfer methods. We address this issue by collecting SynLiDAR, a synthetic LiDAR point cloud dataset that contains large-scale point-wise annotated point cloud with accurate geometric shapes and comprehensive semantic classes, and designing PCT-Net, a point cloud translation network that aims to narrow down the gap with real-world point cloud data. For SynLiDAR, we leverage graphic tools and professionals who construct multiple realistic virtual environments with rich scene types and layouts where annotated LiDAR points can be generated automatically. On top of that, PCT-Net disentangles synthetic-to-real gaps into an appearance component and a sparsity component and translates SynLiDAR by aligning the two components with real-world data separately. Extensive experiments over multiple data augmentation and semi-supervised semantic segmentation tasks show very positive outcomes - including SynLiDAR can either train better models or reduce real-world annotated data without sacrificing performance, and PCT-Net translated data further improve model performance consistently.
FBC-GAN: Diverse and Flexible Image Synthesis via Foreground-Background Composition
Jul 07, 2021
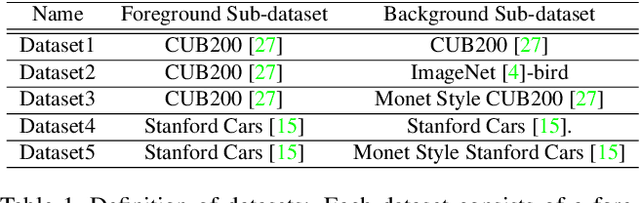
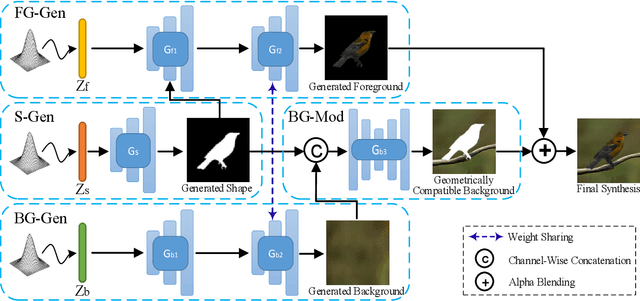
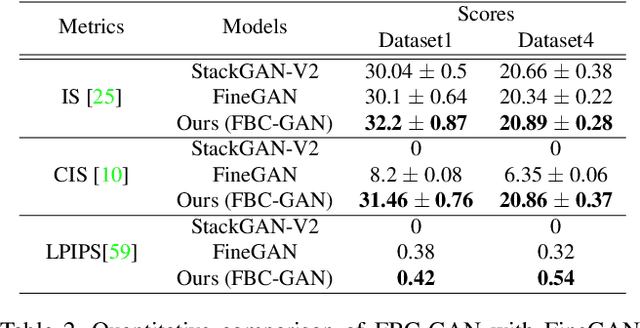
Generative Adversarial Networks (GANs) have become the de-facto standard in image synthesis. However, without considering the foreground-background decomposition, existing GANs tend to capture excessive content correlation between foreground and background, thus constraining the diversity in image generation. This paper presents a novel Foreground-Background Composition GAN (FBC-GAN) that performs image generation by generating foreground objects and background scenes concurrently and independently, followed by composing them with style and geometrical consistency. With this explicit design, FBC-GAN can generate images with foregrounds and backgrounds that are mutually independent in contents, thus lifting the undesirably learned content correlation constraint and achieving superior diversity. It also provides excellent flexibility by allowing the same foreground object with different background scenes, the same background scene with varying foreground objects, or the same foreground object and background scene with different object positions, sizes and poses. It can compose foreground objects and background scenes sampled from different datasets as well. Extensive experiments over multiple datasets show that FBC-GAN achieves competitive visual realism and superior diversity as compared with state-of-the-art methods.
Bi-level Feature Alignment for Versatile Image Translation and Manipulation
Jul 07, 2021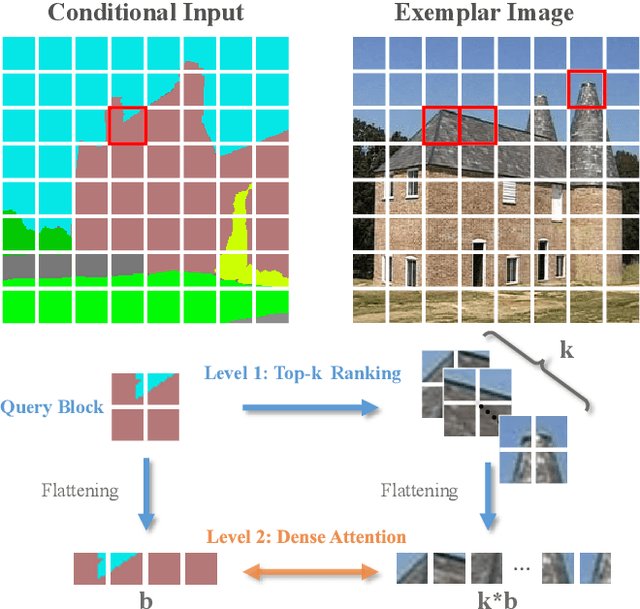
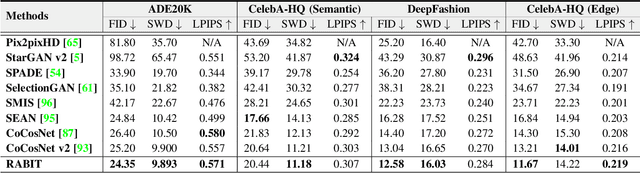
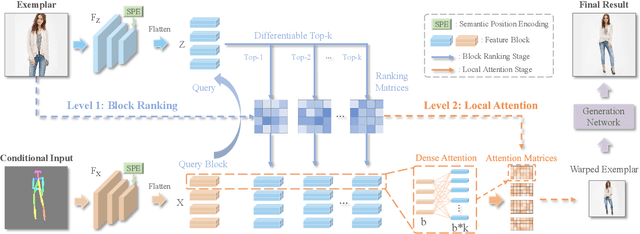
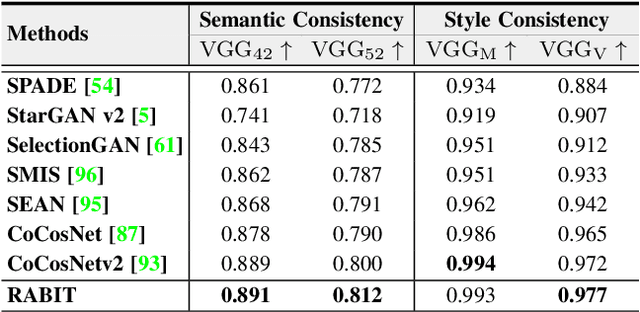
Generative adversarial networks (GANs) have achieved great success in image translation and manipulation. However, high-fidelity image generation with faithful style control remains a grand challenge in computer vision. This paper presents a versatile image translation and manipulation framework that achieves accurate semantic and style guidance in image generation by explicitly building a correspondence. To handle the quadratic complexity incurred by building the dense correspondences, we introduce a bi-level feature alignment strategy that adopts a top-$k$ operation to rank block-wise features followed by dense attention between block features which reduces memory cost substantially. As the top-$k$ operation involves index swapping which precludes the gradient propagation, we propose to approximate the non-differentiable top-$k$ operation with a regularized earth mover's problem so that its gradient can be effectively back-propagated. In addition, we design a novel semantic position encoding mechanism that builds up coordinate for each individual semantic region to preserve texture structures while building correspondences. Further, we design a novel confidence feature injection module which mitigates mismatch problem by fusing features adaptively according to the reliability of built correspondences. Extensive experiments show that our method achieves superior performance qualitatively and quantitatively as compared with the state-of-the-art. The code is available at \href{https://github.com/fnzhan/RABIT}{https://github.com/fnzhan/RABIT}.