 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradient for s-Rectangular Robust Markov Decision Processes
Jan 31, 2023



We present a novel robust policy gradient method (RPG) for s-rectangular robust Markov Decision Processes (MDPs). We are the first to derive the adversarial kernel in a closed form and demonstrate that it is a one-rank perturbation of the nominal kernel. This allows us to derive an RPG that is similar to the one used in non-robust MDPs, except with a robust Q-value function and an additional correction term. Both robust Q-values and correction terms are efficiently computable, thus the time complexity of our method matches that of non-robust MDPs, which is significantly faster compared to existing black box methods.
An Efficient Solution to s-Rectangular Robust Markov Decision Processes
Jan 31, 2023



We present an efficient robust value iteration for \texttt{s}-rectangular robust Markov Decision Processes (MDPs) with a time complexity comparable to standard (non-robust) MDPs which is significantly faster than any existing method. We do so by deriving the optimal robust Bellman operator in concrete forms using our $L_p$ water filling lemma. We unveil the exact form of the optimal policies, which turn out to be novel threshold policies with the probability of playing an action proportional to its advantage.
SoftTreeMax: Exponential Variance Reduction in Policy Gradient via Tree Search
Jan 30, 2023



Despite the popularity of policy gradient methods, they are known to suffer from large variance and high sample complexity. To mitigate this, we introduce SoftTreeMax -- a generalization of softmax that takes planning into account. In SoftTreeMax, we extend the traditional logits with the multi-step discounted cumulative reward, topped with the logits of future states. We consider two variants of SoftTreeMax, one for cumulative reward and one for exponentiated reward. For both, we analyze the gradient variance and reveal for the first time the role of a tree expansion policy in mitigating this variance. We prove that the resulting variance decays exponentially with the planning horizon as a function of the expansion policy. Specifically, we show that the closer the resulting state transitions are to uniform, the faster the decay. In a practical implementation, we utilize a parallelized GPU-based simulator for fast and efficient tree search. Our differentiable tree-based policy leverages all gradients at the tree leaves in each environment step instead of the traditional single-sample-based gradient. We then show in simulation how the variance of the gradient is reduced by three orders of magnitude, leading to better sample complexity compared to the standard policy gradient. On Atari, SoftTreeMax demonstrates up to 5x better performance in a faster run time compared to distributed PPO. Lastly, we demonstrate that high reward correlates with lower variance.
Train Hard, Fight Easy: Robust Meta Reinforcement Learning
Jan 26, 2023



A major challenge of reinforcement learning (RL) in real-world applications is the variation between environments, tasks or clients. Meta-RL (MRL) addresses this issue by learning a meta-policy that adapts to new tasks. Standard MRL methods optimize the average return over tasks, but often suffer from poor results in tasks of high risk or difficulty. This limits system reliability whenever test tasks are not known in advance. In this work, we propose a robust MRL objective with a controlled robustness level. Optimization of analogous robust objectives in RL often leads to both biased gradients and data inefficiency. We prove that the former disappears in MRL, and address the latter via the novel Robust Meta RL algorithm (RoML). RoML is a meta-algorithm that generates a robust version of any given MRL algorithm, by identifying and over-sampling harder tasks throughout training. We demonstrate that RoML learns substantially different meta-policies and achieves robust returns on several navigation and continuous control benchmarks.
Towards Deployable RL -- What's Broken with RL Research and a Potential Fix
Jan 03, 2023Reinforcement learning (RL) has demonstrated great potential, but is currently full of overhyping and pipe dreams. We point to some difficulties with current research which we feel are endemic to the direction taken by the community. To us, the current direction is not likely to lead to "deployable" RL: RL that works in practice and can work in practical situations yet still is economically viable. We also propose a potential fix to some of the difficulties of the field.
DiffStack: A Differentiable and Modular Control Stack for Autonomous Vehicles
Dec 13, 2022



Autonomous vehicle (AV) stacks are typically built in a modular fashion, with explicit components performing detection, tracking, prediction, planning, control, etc. While modularity improves reusability, interpretability, and generalizability, it also suffers from compounding errors, information bottlenecks, and integration challenges. To overcome these challenges, a prominent approach is to convert the AV stack into an end-to-end neural network and train it with data. While such approaches have achieved impressive results, they typically lack interpretability and reusability, and they eschew principled analytical components, such as planning and control, in favor of deep neural networks. To enable the joint optimization of AV stacks while retaining modularity, we present DiffStack, a differentiable and modular stack for prediction, planning, and control. Crucially, our model-based planning and control algorithms leverage recent advancements in differentiable optimization to produce gradients, enabling optimization of upstream components, such as prediction, via backpropagation through planning and control. Our results on the nuScenes dataset indicate that end-to-end training with DiffStack yields substantial improvements in open-loop and closed-loop planning metrics by, e.g., learning to make fewer prediction errors that would affect planning. Beyond these immediate benefits, DiffStack opens up new opportunities for fully data-driven yet modular and interpretable AV architectures. Project website: https://sites.google.com/view/diffstack
Reward-Mixing MDPs with a Few Latent Contexts are Learnable
Oct 05, 2022We consider episodic reinforcement learning in reward-mixing Markov decision processes (RMMDPs): at the beginning of every episode nature randomly picks a latent reward model among $M$ candidates and an agent interacts with the MDP throughout the episode for $H$ time steps. Our goal is to learn a near-optimal policy that nearly maximizes the $H$ time-step cumulative rewards in such a model. Previous work established an upper bound for RMMDPs for $M=2$. In this work, we resolve several open questions remained for the RMMDP model. For an arbitrary $M\ge2$, we provide a sample-efficient algorithm--$\texttt{EM}^2$--that outputs an $\epsilon$-optimal policy using $\tilde{O} \left(\epsilon^{-2} \cdot S^d A^d \cdot \texttt{poly}(H, Z)^d \right)$ episodes, where $S, A$ are the number of states and actions respectively, $H$ is the time-horizon, $Z$ is the support size of reward distributions and $d=\min(2M-1,H)$. Our technique is a higher-order extension of the method-of-moments based approach, nevertheless, the design and analysis of the \algname algorithm requires several new ideas beyond existing techniques. We also provide a lower bound of $(SA)^{\Omega(\sqrt{M})} / \epsilon^{2}$ for a general instance of RMMDP, supporting that super-polynomial sample complexity in $M$ is necessary.
Tractable Optimality in Episodic Latent MABs
Oct 05, 2022
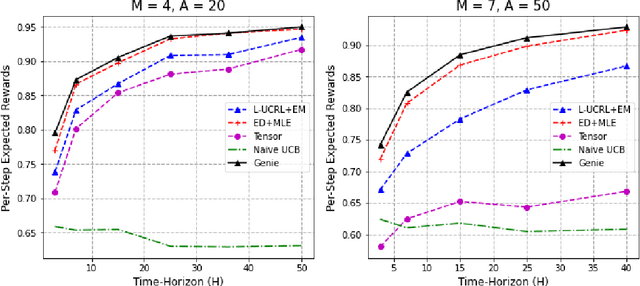
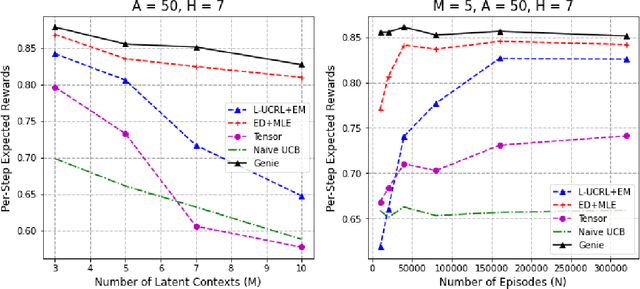
We consider a multi-armed bandit problem with $M$ latent contexts, where an agent interacts with the environment for an episode of $H$ time steps. Depending on the length of the episode, the learner may not be able to estimate accurately the latent context. The resulting partial observation of the environment makes the learning task significantly more challenging. Without any additional structural assumptions, existing techniques to tackle partially observed settings imply the decision maker can learn a near-optimal policy with $O(A)^H$ episodes, but do not promise more. In this work, we show that learning with {\em polynomial} samples in $A$ is possible. We achieve this by using techniques from experiment design. Then, through a method-of-moments approach, we design a procedure that provably learns a near-optimal policy with $O(\texttt{poly}(A) + \texttt{poly}(M,H)^{\min(M,H)})$ interactions. In practice, we show that we can formulate the moment-matching via maximum likelihood estimation. In our experiments, this significantly outperforms the worst-case guarantees, as well as existing practical methods.
Policy Gradient for Reinforcement Learning with General Utilities
Oct 03, 2022In Reinforcement Learning (RL), the goal of agents is to discover an optimal policy that maximizes the expected cumulative rewards. This objective may also be viewed as finding a policy that optimizes a linear function of its state-action occupancy measure, hereafter referred as Linear RL. However, many supervised and unsupervised RL problems are not covered in the Linear RL framework, such as apprenticeship learning, pure exploration and variational intrinsic control, where the objectives are non-linear functions of the occupancy measures. RL with non-linear utilities looks unwieldy, as methods like Bellman equation, value iteration, policy gradient, dynamic programming that had tremendous success in Linear RL, fail to trivially generalize. In this paper, we derive the policy gradient theorem for RL with general utilities. The policy gradient theorem proves to be a cornerstone in Linear RL due to its elegance and ease of implementability. Our policy gradient theorem for RL with general utilities shares the same elegance and ease of implementability. Based on the policy gradient theorem derived, we also present a simple sample-based algorithm. We believe our results will be of interest to the community and offer inspiration to future works in this generalized setting.
SoftTreeMax: Policy Gradient with Tree Search
Sep 28, 2022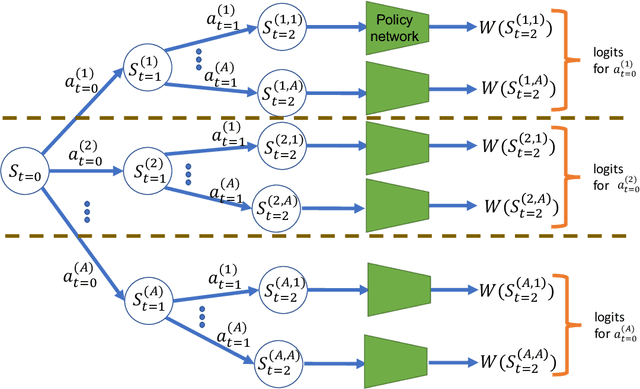
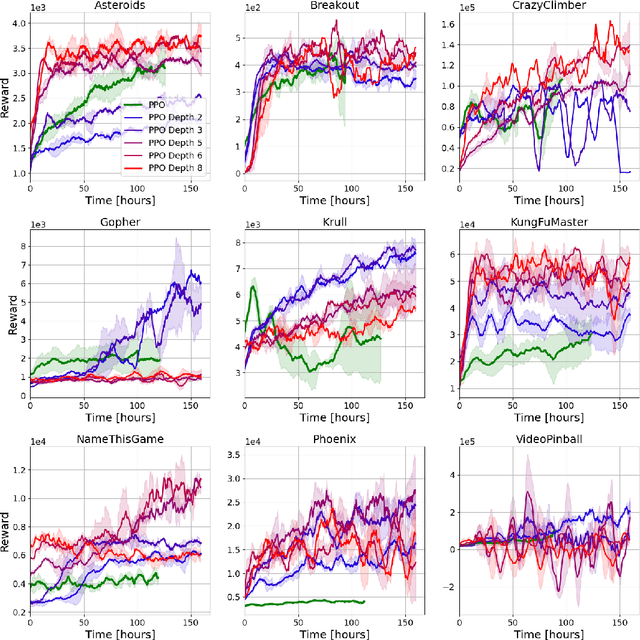
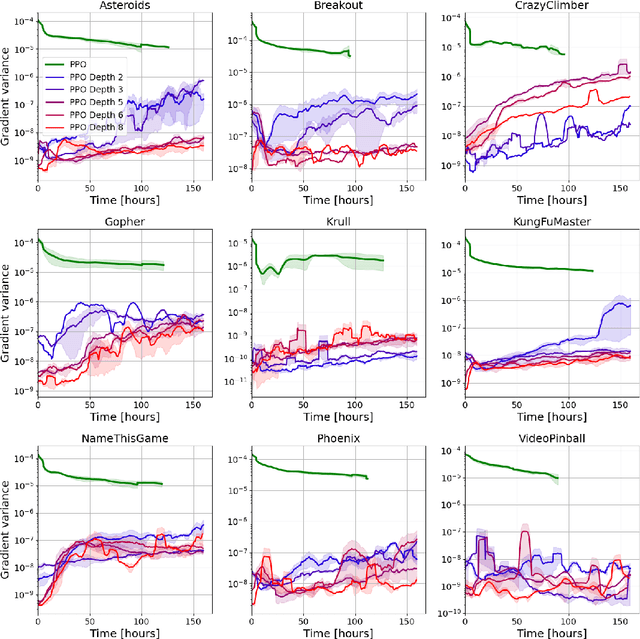
Policy-gradient methods are widely used for learning control policies. They can be easily distributed to multiple workers and reach state-of-the-art results in many domains. Unfortunately, they exhibit large variance and subsequently suffer from high-sample complexity since they aggregate gradients over entire trajectories. At the other extreme, planning methods, like tree search, optimize the policy using single-step transitions that consider future lookahead. These approaches have been mainly considered for value-based algorithms. Planning-based algorithms require a forward model and are computationally intensive at each step, but are more sample efficient. In this work, we introduce SoftTreeMax, the first approach that integrates tree-search into policy gradient. Traditionally, gradients are computed for single state-action pairs. Instead, our tree-based policy structure leverages all gradients at the tree leaves in each environment step. This allows us to reduce the variance of gradients by three orders of magnitude and to benefit from better sample complexity compared with standard policy gradient. On Atari, SoftTreeMax demonstrates up to 5x better performance in faster run-time compared with distributed PPO.