 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling Equivariant Self-attention Networks for Object Detection in Aerial Images
Nov 05, 2021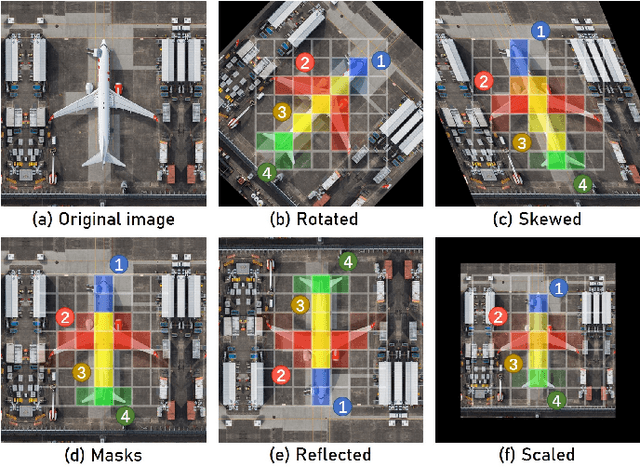
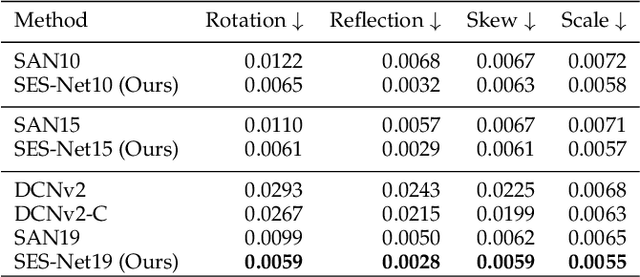
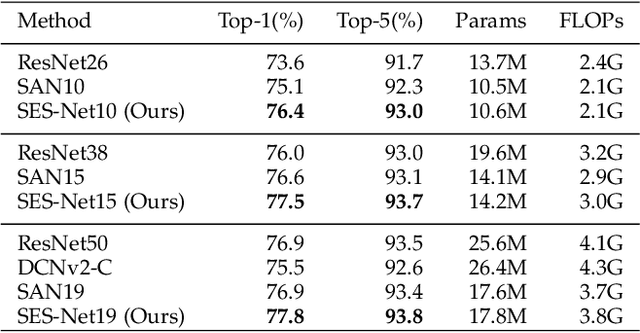
Objects in aerial images have greater variations in scale and orientation than in typical images, so detection is more difficult. Convolutional neural networks use a variety of frequency- and orientation-specific kernels to identify objects subject to different transformations; these require many parameters. Sampling equivariant networks can adjust sampling from input feature maps according to the transformation of the object, allowing a kernel to extract features of an object under different transformations. Doing so requires fewer parameters, and makes the network more suitable for representing deformable objects, like those in aerial images. However, methods like deformable convolutional networks can only provide sampling equivariance under certain circumstances, because of the locations used for sampling. We propose sampling equivariant self-attention networks which consider self-attention restricted to a local image patch as convolution sampling with masks instead of locations, and design a transformation embedding module to further improve the equivariant sampling ability. We also use a novel randomized normalization module to tackle overfitting due to limited aerial image data. We show that our model (i) provides significantly better sampling equivariance than existing methods, without additional supervision, (ii) provides improved classification on ImageNet, and (iii) achieves state-of-the-art results on the DOTA dataset, without increased computation.
Subdivision-Based Mesh Convolution Networks
Jun 04, 2021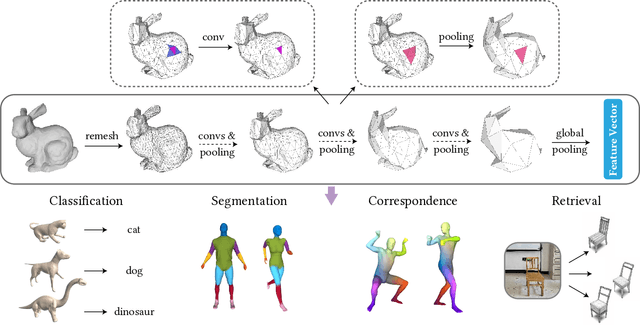
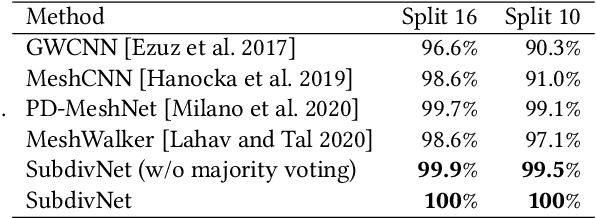
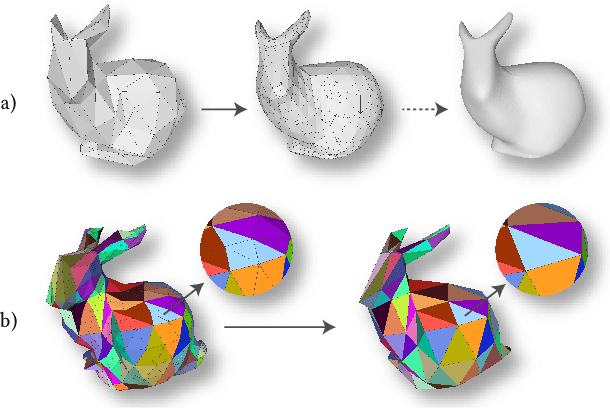
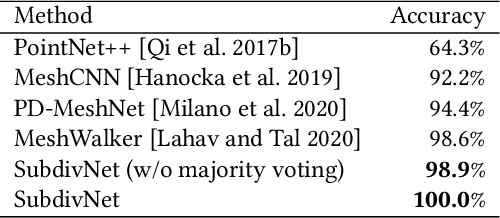
Convolutional neural networks (CNNs) have made great breakthroughs in 2D computer vision. However, the irregular structure of meshes makes it hard to exploit the power of CNNs directly. A subdivision surface provides a hierarchical multi-resolution structure, and each face in a closed 2-manifold triangle mesh is exactly adjacent to three faces. Motivated by these two properties, this paper introduces a novel and flexible CNN framework, named SubdivNet, for 3D triangle meshes with Loop subdivision sequence connectivity. Making an analogy between mesh faces and pixels in a 2D image allows us to present a mesh convolution operator to aggregate local features from adjacent faces. By exploiting face neighborhoods, this convolution can support standard 2D convolutional network concepts, e.g. variable kernel size, stride, and dilation. Based on the multi-resolution hierarchy, we propose a spatial uniform pooling layer which merges four faces into one and an upsampling method which splits one face into four. As a result, many popular 2D CNN architectures can be readily adapted to processing 3D meshes. Meshes with arbitrary connectivity can be remeshed to hold Loop subdivision sequence connectivity via self-parameterization, making SubdivNet a general approach. Experiments on mesh classification, segmentation, correspondence, and retrieval from the real-world demonstrate the effectiveness and efficiency of SubdivNet.
Can Attention Enable MLPs To Catch Up With CNNs?
May 31, 2021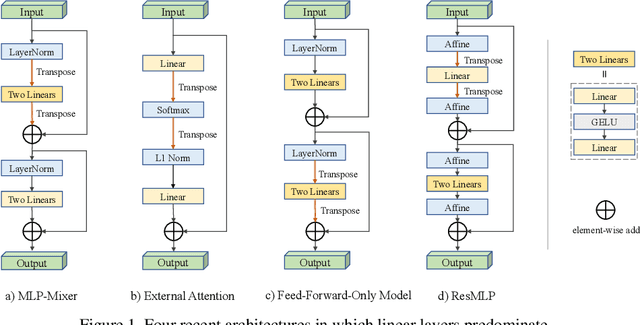
In the first week of May, 2021, researchers from four different institutions: Google, Tsinghua University, Oxford University and Facebook, shared their latest work [16, 7, 12, 17] on arXiv.org almost at the same time, each proposing new learning architectures, consisting mainly of linear layers, claiming them to be comparable, or even superior to convolutional-based models. This sparked immediate discussion and debate in both academic and industrial communities as to whether MLPs are sufficient, many thinking that learning architectures are returning to MLPs. Is this true? In this perspective, we give a brief history of learning architectures, including multilayer perceptrons (MLPs), convolutional neural networks (CNNs) and transformers. We then examine what the four newly proposed architectures have in common. Finally, we give our views on challenges and directions for new learning architectures, hoping to inspire future research.
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
May 31, 2021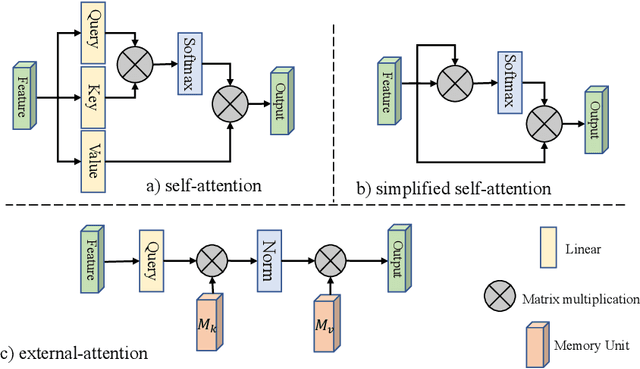
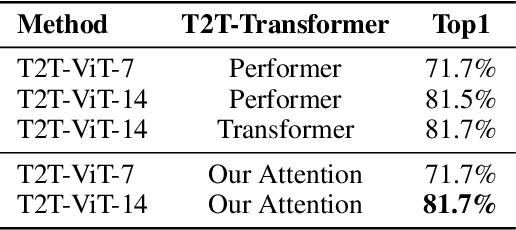

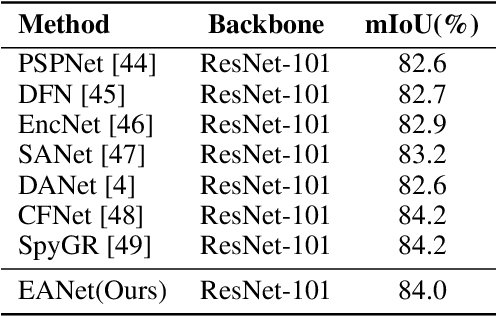
Attention mechanisms, especially self-attention, have played an increasingly important role in deep feature representation for visual tasks. Self-attention updates the feature at each position by computing a weighted sum of features using pair-wise affinities across all positions to capture the long-range dependency within a single sample. However, self-attention has quadratic complexity and ignores potential correlation between different samples. This paper proposes a novel attention mechanism which we call external attention, based on two external, small, learnable, shared memories, which can be implemented easily by simply using two cascaded linear layers and two normalization layers; it conveniently replaces self-attention in existing popular architectures. External attention has linear complexity and implicitly considers the correlations between all data samples. We further incorporate the multi-head mechanism into external attention to provide an all-MLP architecture, external attention MLP (EAMLP), for image classification. Extensive experiments on image classification, object detection, semantic segmentation, instance segmentation, image generation, and point cloud analysis reveal that our method provides results comparable or superior to the self-attention mechanism and some of its variants, with much lower computational and memory costs.
Recursive-NeRF: An Efficient and Dynamically Growing NeRF
May 19, 2021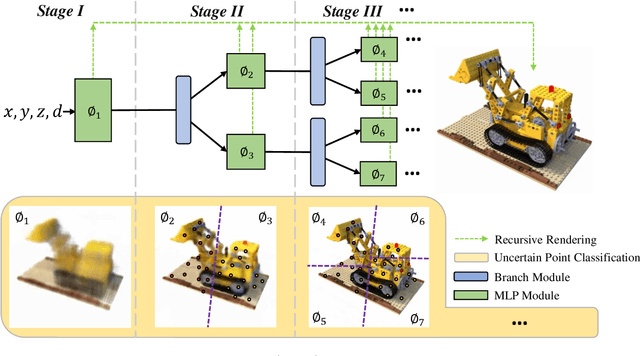
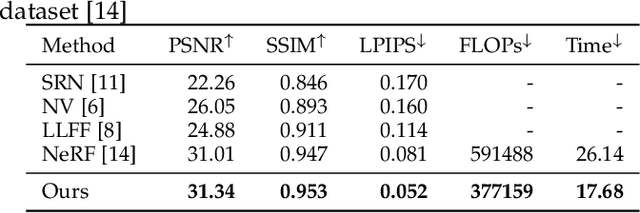
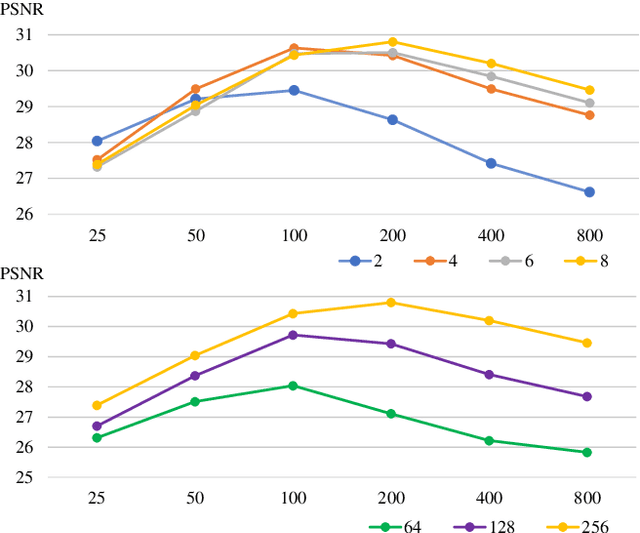
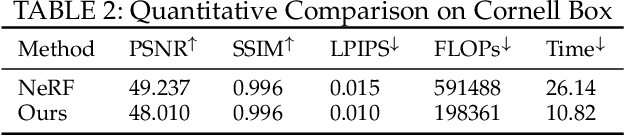
View synthesis methods using implicit continuous shape representations learned from a set of images, such as the Neural Radiance Field (NeRF) method, have gained increasing attention due to their high quality imagery and scalability to high resolution. However, the heavy computation required by its volumetric approach prevents NeRF from being useful in practice; minutes are taken to render a single image of a few megapixels. Now, an image of a scene can be rendered in a level-of-detail manner, so we posit that a complicated region of the scene should be represented by a large neural network while a small neural network is capable of encoding a simple region, enabling a balance between efficiency and quality. Recursive-NeRF is our embodiment of this idea, providing an efficient and adaptive rendering and training approach for NeRF. The core of Recursive-NeRF learns uncertainties for query coordinates, representing the quality of the predicted color and volumetric intensity at each level. Only query coordinates with high uncertainties are forwarded to the next level to a bigger neural network with a more powerful representational capability. The final rendered image is a composition of results from neural networks of all levels. Our evaluation on three public datasets shows that Recursive-NeRF is more efficient than NeRF while providing state-of-the-art quality. The code will be available at https://github.com/Gword/Recursive-NeRF.
MultiBodySync: Multi-Body Segmentation and Motion Estimation via 3D Scan Synchronization
Jan 17, 2021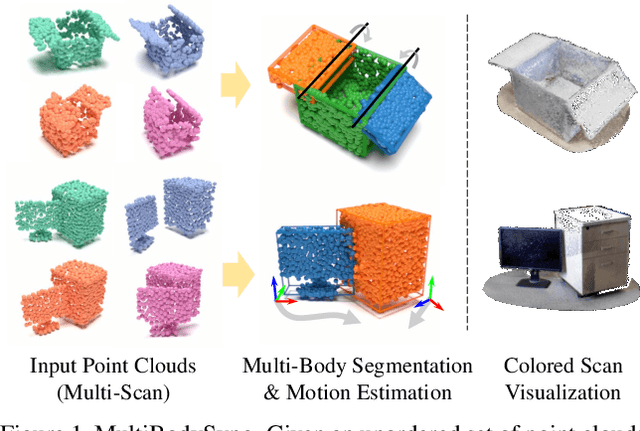
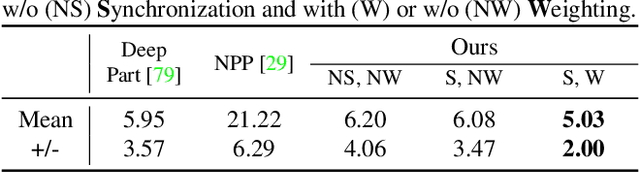
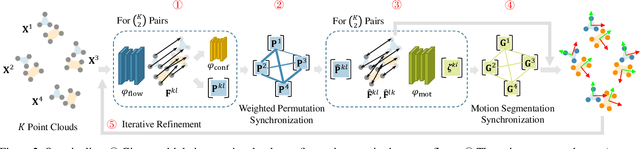
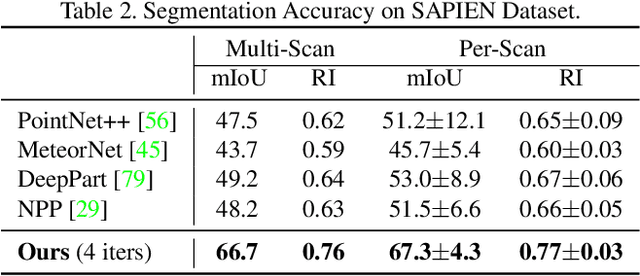
We present MultiBodySync, a novel, end-to-end trainable multi-body motion segmentation and rigid registration framework for multiple input 3D point clouds. The two non-trivial challenges posed by this multi-scan multibody setting that we investigate are: (i) guaranteeing correspondence and segmentation consistency across multiple input point clouds capturing different spatial arrangements of bodies or body parts; and (ii) obtaining robust motion-based rigid body segmentation applicable to novel object categories. We propose an approach to address these issues that incorporates spectral synchronization into an iterative deep declarative network, so as to simultaneously recover consistent correspondences as well as motion segmentation. At the same time, by explicitly disentangling the correspondence and motion segmentation estimation modules, we achieve strong generalizability across different object categories. Our extensive evaluations demonstrate that our method is effective on various datasets ranging from rigid parts in articulated objects to individually moving objects in a 3D scene, be it single-view or full point clouds.
PCT: Point Cloud Transformer
Dec 17, 2020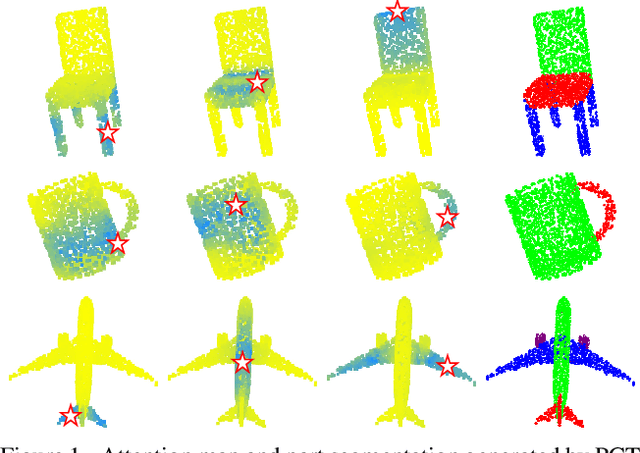
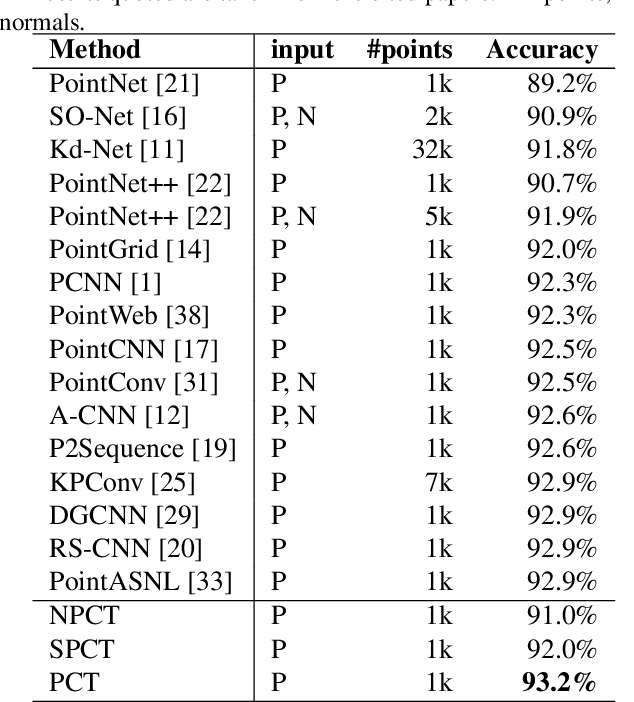
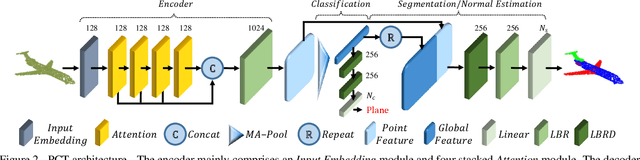
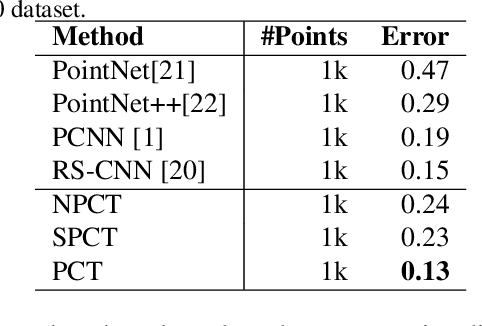
The irregular domain and lack of ordering make it challenging to design deep neural networks for point cloud processing. This paper presents a novel framework named Point Cloud Transformer(PCT) for point cloud learning. PCT is based on Transformer, which achieves huge success in natural language processing and displays great potential in image processing. It is inherently permutation invariant for processing a sequence of points, making it well-suited for point cloud learning. To better capture local context within the point cloud, we enhance input embedding with the support of farthest point sampling and nearest neighbor search. Extensive experiments demonstrate that the PCT achieves the state-of-the-art performance on shape classification, part segmentation and normal estimation tasks.
DI-Fusion: Online Implicit 3D Reconstruction with Deep Priors
Dec 10, 2020
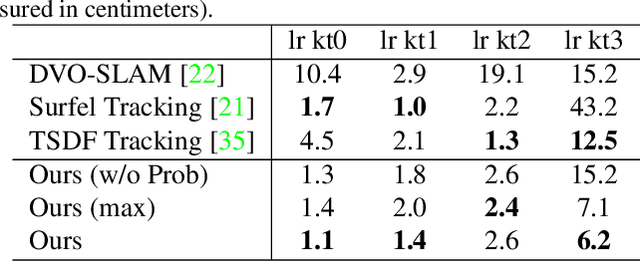
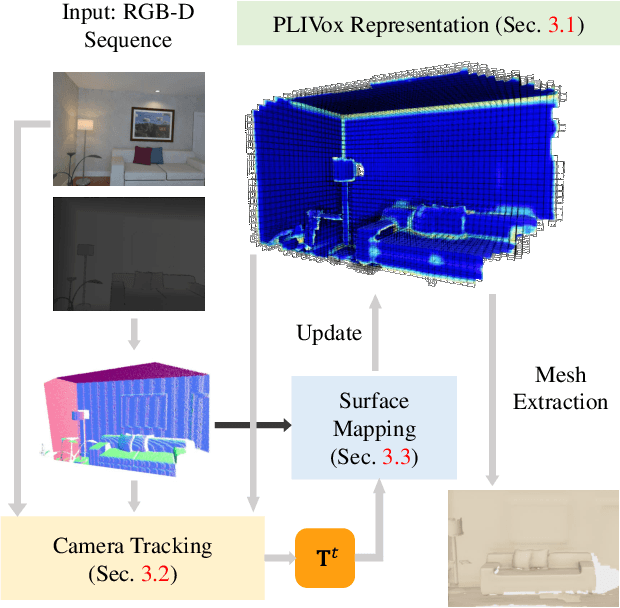
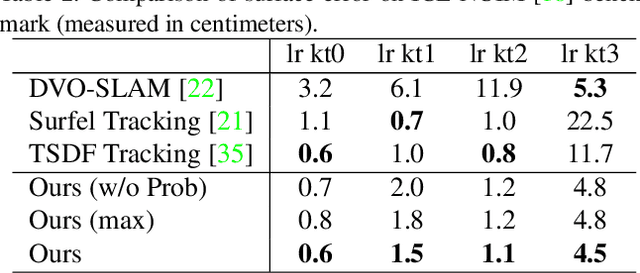
Previous online 3D dense reconstruction methods often cost massive memory storage while achieving unsatisfactory surface quality mainly due to the usage of stagnant underlying geometry representation, such as TSDF (truncated signed distance functions) or surfels, without any knowledge of the scene priors. In this paper, we present DI-Fusion (Deep Implicit Fusion), based on a novel 3D representation, called Probabilistic Local Implicit Voxels (PLIVoxs), for online 3D reconstruction using a commodity RGB-D camera. Our PLIVox encodes scene priors considering both the local geometry and uncertainty parameterized by a deep neural network. With such deep priors, we demonstrate by extensive experiments that we are able to perform online implicit 3D reconstruction achieving state-of-the-art mapping quality and camera trajectory estimation accuracy, while taking much less storage compared with previous online 3D reconstruction approaches.
Alternating ConvLSTM: Learning Force Propagation with Alternate State Updates
Jun 14, 2020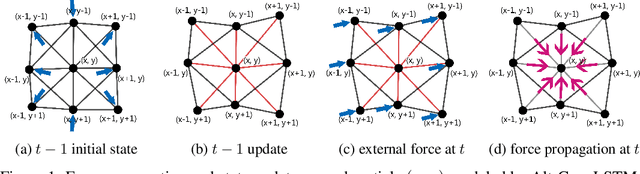
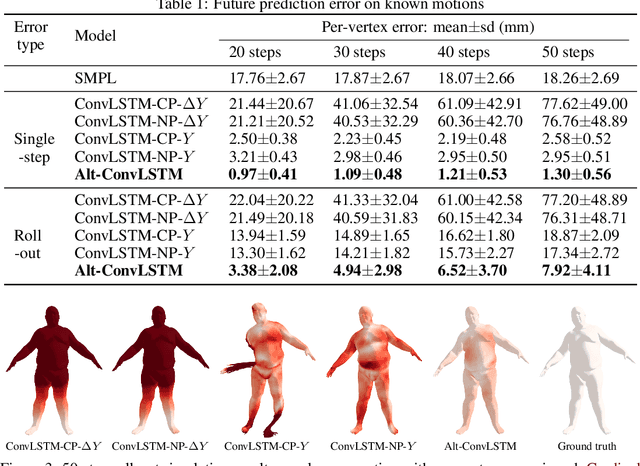
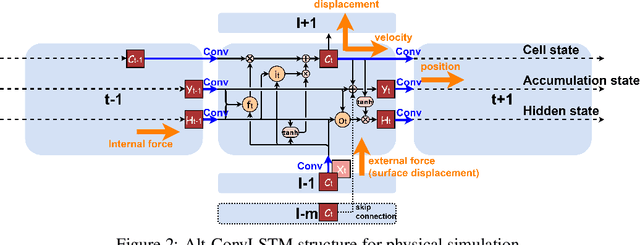
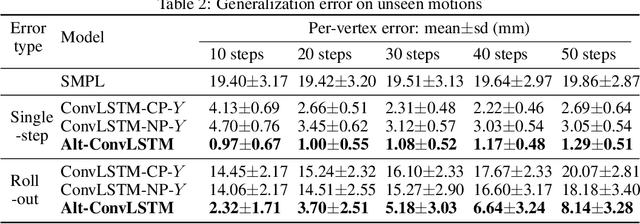
Data-driven simulation is an important step-forward in computational physics when traditional numerical methods meet their limits. Learning-based simulators have been widely studied in past years; however, most previous works view simulation as a general spatial-temporal prediction problem and take little physical guidance in designing their neural network architectures. In this paper, we introduce the alternating convolutional Long Short-Term Memory (Alt-ConvLSTM) that models the force propagation mechanisms in a deformable object with near-uniform material properties. Specifically, we propose an accumulation state, and let the network update its cell state and the accumulation state alternately. We demonstrate how this novel scheme imitates the alternate updates of the first and second-order terms in the forward Euler method of numerical PDE solvers. Benefiting from this, our network only requires a small number of parameters, independent of the number of the simulated particles, and also retains the essential features in ConvLSTM, making it naturally applicable to sequential data with spatial inputs and outputs. We validate our Alt-ConvLSTM on human soft tissue simulation with thousands of particles and consistent body pose changes. Experimental results show that Alt-ConvLSTM efficiently models the material kinetic features and greatly outperforms vanilla ConvLSTM with only the single state update.
ClusterVO: Clustering Moving Instances and Estimating Visual Odometry for Self and Surroundings
Mar 29, 2020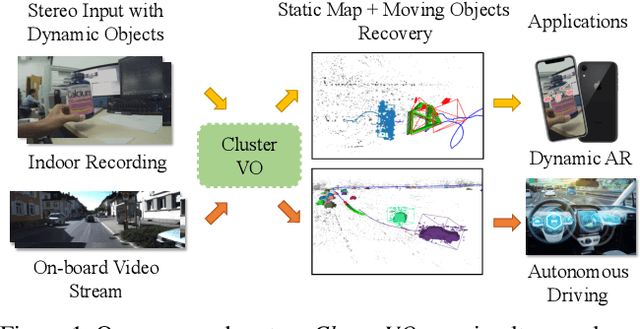

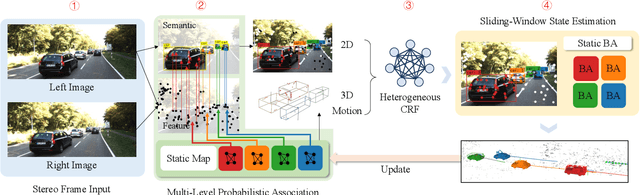

We present ClusterVO, a stereo Visual Odometry which simultaneously clusters and estimates the motion of both ego and surrounding rigid clusters/objects. Unlike previous solutions relying on batch input or imposing priors on scene structure or dynamic object models, ClusterVO is online, general and thus can be used in various scenarios including indoor scene understanding and autonomous driving. At the core of our system lies a multi-level probabilistic association mechanism and a heterogeneous Conditional Random Field (CRF) clustering approach combining semantic, spatial and motion information to jointly infer cluster segmentations online for every frame. The poses of camera and dynamic objects are instantly solved through a sliding-window optimization. Our system is evaluated on Oxford Multimotion and KITTI dataset both quantitatively and qualitatively, reaching comparable results to state-of-the-art solutions on both odometry and dynamic trajectory recovery.