 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Variable-Length Generation in Diffusion Language Models via Length Regularization
Feb 07, 2026Diffusion Large Language Models (DLLMs) are inherently ill-suited for variable-length generation, as their inference is defined on a fixed-length canvas and implicitly assumes a known target length. When the length is unknown, as in realistic completion and infilling, naively comparing confidence across mask lengths becomes systematically biased, leading to under-generation or redundant continuations. In this paper, we show that this failure arises from an intrinsic lengthinduced bias in generation confidence estimates, leaving existing DLLMs without a robust way to determine generation length and making variablelength inference unreliable. To address this issue, we propose LR-DLLM, a length-regularized inference framework for DLLMs that treats generation length as an explicit variable and achieves reliable length determination at inference time. It decouples semantic compatibility from lengthinduced uncertainty through an explicit length regularization that corrects biased confidence estimates. Based on this, LR-DLLM enables dynamic expansion or contraction of the generation span without modifying the underlying DLLM or its training procedure. Experiments show that LRDLLM achieves 51.3% Pass@1 on HumanEvalInfilling under fully unknown lengths (+13.4% vs. DreamOn) and 51.5% average Pass@1 on four-language McEval (+14.3% vs. DreamOn).
DEER: Draft with Diffusion, Verify with Autoregressive Models
Dec 17, 2025



Efficiency, as a critical practical challenge for LLM-driven agentic and reasoning systems, is increasingly constrained by the inherent latency of autoregressive (AR) decoding. Speculative decoding mitigates this cost through a draft-verify scheme, yet existing approaches rely on AR draft models (a.k.a., drafters), which introduce two fundamental issues: (1) step-wise uncertainty accumulation leads to a progressive collapse of trust between the target model and the drafter, and (2) inherently sequential decoding of AR drafters. Together, these factors cause limited speedups. In this paper, we show that a diffusion large language model (dLLM) drafters can naturally overcome these issues through its fundamentally different probabilistic modeling and efficient parallel decoding strategy. Building on this insight, we introduce DEER, an efficient speculative decoding framework that drafts with diffusion and verifies with AR models. To enable high-quality drafting, DEER employs a two-stage training pipeline to align the dLLM-based drafters with the target AR model, and further adopts single-step decoding to generate long draft segments. Experiments show DEER reaches draft acceptance lengths of up to 32 tokens, far surpassing the 10 tokens achieved by EAGLE-3. Moreover, on HumanEval with Qwen3-30B-A3B, DEER attains a 5.54x speedup, while EAGLE-3 achieves only 2.41x. Code, model, demo, etc, will be available at https://czc726.github.io/DEER/
R-Bench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation
May 04, 2025Reasoning stands as a cornerstone of intelligence, enabling the synthesis of existing knowledge to solve complex problems. Despite remarkable progress, existing reasoning benchmarks often fail to rigorously evaluate the nuanced reasoning capabilities required for complex, real-world problemsolving, particularly in multi-disciplinary and multimodal contexts. In this paper, we introduce a graduate-level, multi-disciplinary, EnglishChinese benchmark, dubbed as Reasoning Bench (R-Bench), for assessing the reasoning capability of both language and multimodal models. RBench spans 1,094 questions across 108 subjects for language model evaluation and 665 questions across 83 subjects for multimodal model testing in both English and Chinese. These questions are meticulously curated to ensure rigorous difficulty calibration, subject balance, and crosslinguistic alignment, enabling the assessment to be an Olympiad-level multi-disciplinary benchmark. We evaluate widely used models, including OpenAI o1, GPT-4o, DeepSeek-R1, etc. Experimental results indicate that advanced models perform poorly on complex reasoning, especially multimodal reasoning. Even the top-performing model OpenAI o1 achieves only 53.2% accuracy on our multimodal evaluation. Data and code are made publicly available at here.
Recursive-NeRF: An Efficient and Dynamically Growing NeRF
May 19, 2021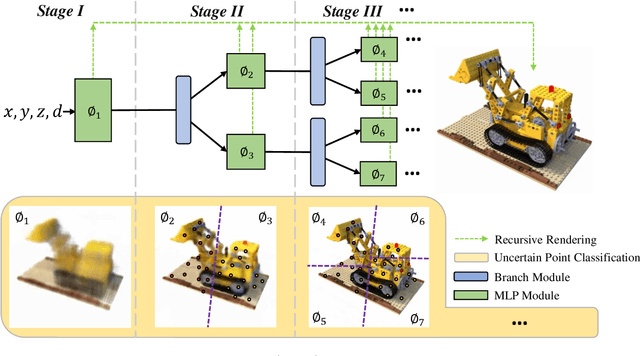
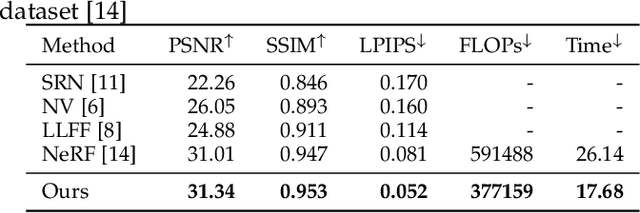
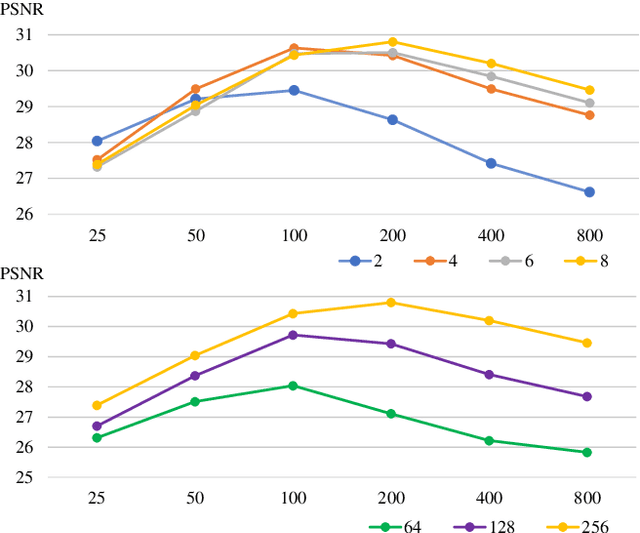
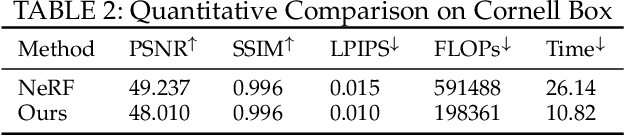
View synthesis methods using implicit continuous shape representations learned from a set of images, such as the Neural Radiance Field (NeRF) method, have gained increasing attention due to their high quality imagery and scalability to high resolution. However, the heavy computation required by its volumetric approach prevents NeRF from being useful in practice; minutes are taken to render a single image of a few megapixels. Now, an image of a scene can be rendered in a level-of-detail manner, so we posit that a complicated region of the scene should be represented by a large neural network while a small neural network is capable of encoding a simple region, enabling a balance between efficiency and quality. Recursive-NeRF is our embodiment of this idea, providing an efficient and adaptive rendering and training approach for NeRF. The core of Recursive-NeRF learns uncertainties for query coordinates, representing the quality of the predicted color and volumetric intensity at each level. Only query coordinates with high uncertainties are forwarded to the next level to a bigger neural network with a more powerful representational capability. The final rendered image is a composition of results from neural networks of all levels. Our evaluation on three public datasets shows that Recursive-NeRF is more efficient than NeRF while providing state-of-the-art quality. The code will be available at https://github.com/Gword/Recursive-NeRF.