 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaUF: Learning the Spatial Uncertainty Field of Radar
Mar 01, 2026Millimeter-wave radar offers unique advantages in adverse weather but suffers from low spatial fidelity, severe azimuth ambiguity, and clutter-induced spurious returns. Existing methods mainly focus on improving spatial perception effectiveness via coarse-to-fine cross-modal supervision, yet often overlook the ambiguous feature-to-label mapping, which may lead to ill-posed geometric inference and pose fundamental challenges to downstream perception tasks. In this work, we propose RaUF, a spatial uncertainty field learning framework that models radar measurements through their physically grounded anisotropic properties. To resolve conflicting feature-to-label mapping, we design an anisotropic probabilistic model that learns fine-grained uncertainty. To further enhance reliability, we propose a Bidirectional Domain Attention mechanism that exploits the mutual complementarity between spatial structure and Doppler consistency, effectively suppressing spurious or multipath-induced reflections. Extensive experiments on public benchmarks and real-world datasets demonstrate that RaUF delivers highly reliable spatial detections with well-calibrated uncertainty. Moreover, downstream case studies further validate the enhanced reliability and scalability of RaUF under challenging real-world driving scenarios.
Towards LLM-Empowered Knowledge Tracing via LLM-Student Hierarchical Behavior Alignment in Hyperbolic Space
Feb 26, 2026Knowledge Tracing (KT) diagnoses students' concept mastery through continuous learning state monitoring in education.Existing methods primarily focus on studying behavioral sequences based on ID or textual information.While existing methods rely on ID-based sequences or shallow textual features, they often fail to capture (1) the hierarchical evolution of cognitive states and (2) individualized problem difficulty perception due to limited semantic modeling. Therefore, this paper proposes a Large Language Model Hyperbolic Aligned Knowledge Tracing(L-HAKT). First, the teacher agent deeply parses question semantics and explicitly constructs hierarchical dependencies of knowledge points; the student agent simulates learning behaviors to generate synthetic data. Then, contrastive learning is performed between synthetic and real data in hyperbolic space to reduce distribution differences in key features such as question difficulty and forgetting patterns. Finally, by optimizing hyperbolic curvature, we explicitly model the tree-like hierarchical structure of knowledge points, precisely characterizing differences in learning curve morphology for knowledge points at different levels. Extensive experiments on four real-world educational datasets validate the effectiveness of our Large Language Model Hyperbolic Aligned Knowledge Tracing (L-HAKT) framework.
RaLD: Generating High-Resolution 3D Radar Point Clouds with Latent Diffusion
Nov 10, 2025



Millimeter-wave radar offers a promising sensing modality for autonomous systems thanks to its robustness in adverse conditions and low cost. However, its utility is significantly limited by the sparsity and low resolution of radar point clouds, which poses challenges for tasks requiring dense and accurate 3D perception. Despite that recent efforts have shown great potential by exploring generative approaches to address this issue, they often rely on dense voxel representations that are inefficient and struggle to preserve structural detail. To fill this gap, we make the key observation that latent diffusion models (LDMs), though successful in other modalities, have not been effectively leveraged for radar-based 3D generation due to a lack of compatible representations and conditioning strategies. We introduce RaLD, a framework that bridges this gap by integrating scene-level frustum-based LiDAR autoencoding, order-invariant latent representations, and direct radar spectrum conditioning. These insights lead to a more compact and expressive generation process. Experiments show that RaLD produces dense and accurate 3D point clouds from raw radar spectrums, offering a promising solution for robust perception in challenging environments.
Real-Time Quantized Image Super-Resolution on Mobile NPUs, Mobile AI 2021 Challenge: Report
May 17, 2021
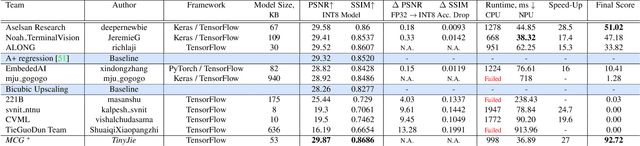
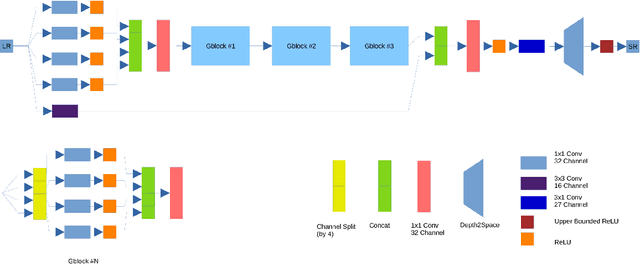
Image super-resolution is one of the most popular computer vision problems with many important applications to mobile devices. While many solutions have been proposed for this task, they are usually not optimized even for common smartphone AI hardware, not to mention more constrained smart TV platforms that are often supporting INT8 inference only. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image super-resolution solutions that can demonstrate a real-time performance on mobile or edge NPUs. For this, the participants were provided with the DIV2K dataset and trained quantized models to do an efficient 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated NPU capable of accelerating quantized neural networks. The proposed solutions are fully compatible with all major mobile AI accelerators and are capable of reconstructing Full HD images under 40-60 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.