 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Uncertainty Guided Multi-Phase Learning for Semi-Supervised Object Detection
Mar 29, 2021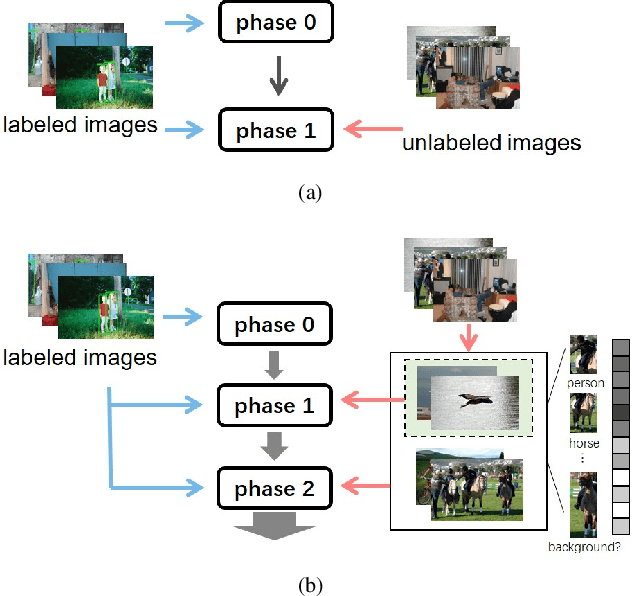
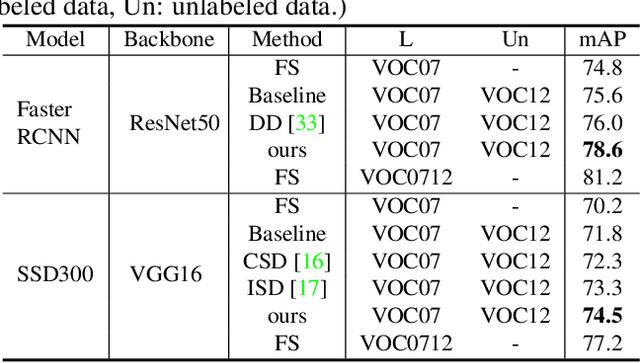
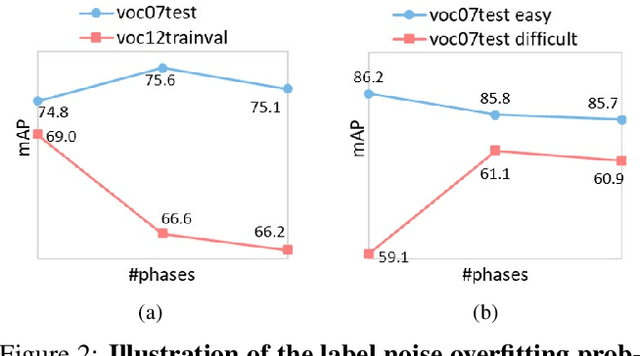
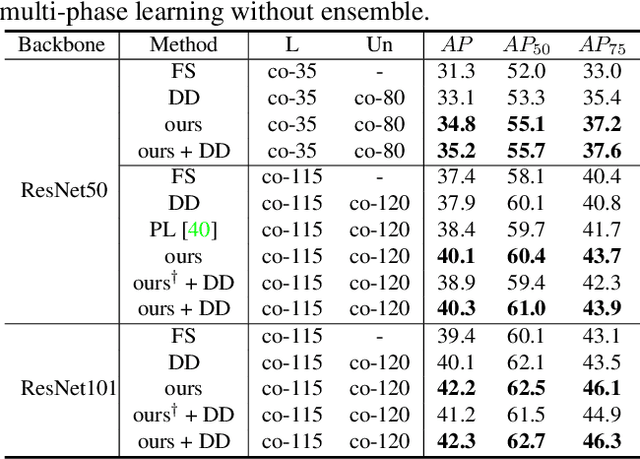
In this paper, we delve into semi-supervised object detection where unlabeled images are leveraged to break through the upper bound of fully-supervised object detection models. Previous semi-supervised methods based on pseudo labels are severely degenerated by noise and prone to overfit to noisy labels, thus are deficient in learning different unlabeled knowledge well. To address this issue, we propose a data-uncertainty guided multi-phase learning method for semi-supervised object detection. We comprehensively consider divergent types of unlabeled images according to their difficulty levels, utilize them in different phases and ensemble models from different phases together to generate ultimate results. Image uncertainty guided easy data selection and region uncertainty guided RoI Re-weighting are involved in multi-phase learning and enable the detector to concentrate on more certain knowledge. Through extensive experiments on PASCAL VOC and MS COCO, we demonstrate that our method behaves extraordinarily compared to baseline approaches and outperforms them by a large margin, more than 3% on VOC and 2% on COCO.
Revisiting Temporal Modeling for Video Super-resolution
Aug 20, 2020
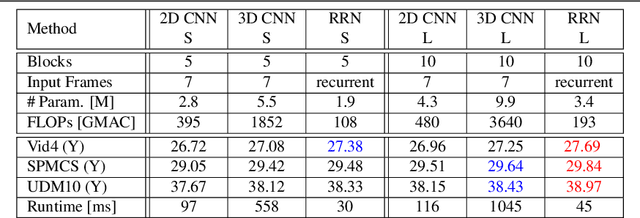
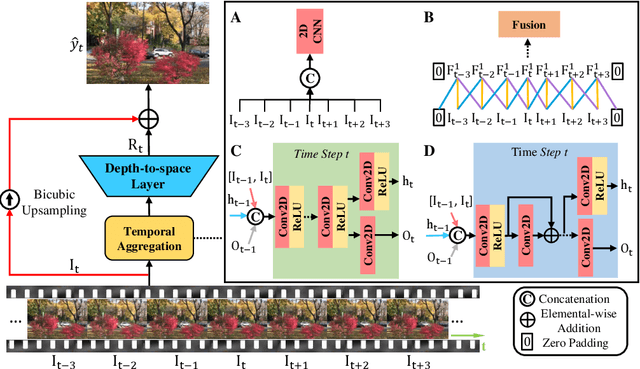

Video super-resolution plays an important role in surveillance video analysis and ultra-high-definition video display, which has drawn much attention in both the research and industrial communities. Although many deep learning-based VSR methods have been proposed, it is hard to directly compare these methods since the different loss functions and training datasets have a significant impact on the super-resolution results. In this work, we carefully study and compare three temporal modeling methods (2D CNN with early fusion, 3D CNN with slow fusion and Recurrent Neural Network) for video super-resolution. We also propose a novel Recurrent Residual Network (RRN) for efficient video super-resolution, where residual learning is utilized to stabilize the training of RNN and meanwhile to boost the super-resolution performance. Extensive experiments show that the proposed RRN is highly computational efficiency and produces temporal consistent VSR results with finer details than other temporal modeling methods. Besides, the proposed method achieves state-of-the-art results on several widely used benchmarks.
Video Super-Resolution with Recurrent Structure-Detail Network
Aug 02, 2020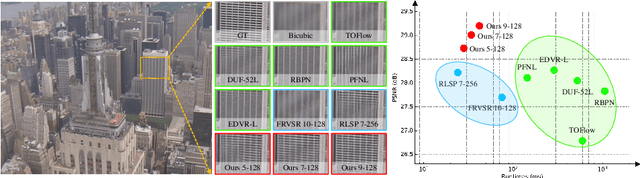

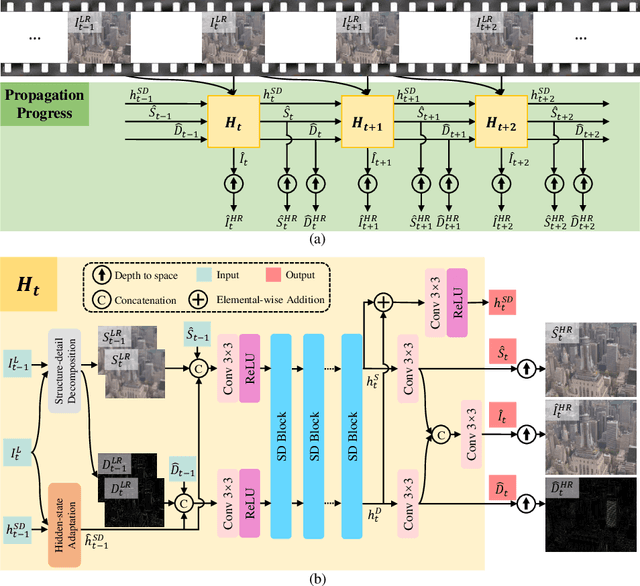

Most video super-resolution methods super-resolve a single reference frame with the help of neighboring frames in a temporal sliding window. They are less efficient compared to the recurrent-based methods. In this work, we propose a novel recurrent video super-resolution method which is both effective and efficient in exploiting previous frames to super-resolve the current frame. It divides the input into structure and detail components which are fed to a recurrent unit composed of several proposed two-stream structure-detail blocks. In addition, a hidden state adaptation module that allows the current frame to selectively use information from hidden state is introduced to enhance its robustness to appearance change and error accumulation. Extensive ablation study validate the effectiveness of the proposed modules. Experiments on several benchmark datasets demonstrate the superior performance of the proposed method compared to state-of-the-art methods on video super-resolution.
Video Super-resolution with Temporal Group Attention
Jul 21, 2020
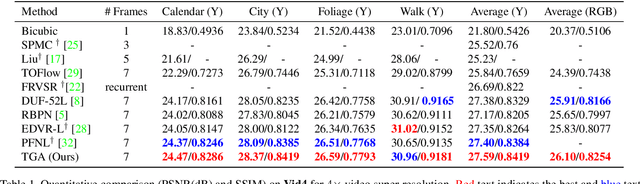
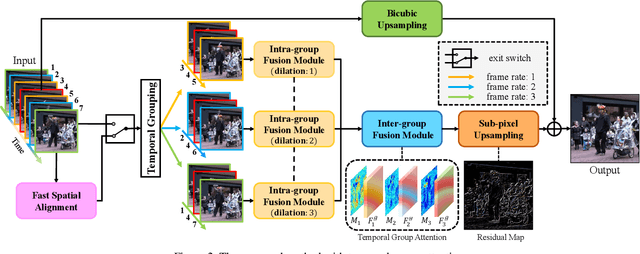

Video super-resolution, which aims at producing a high-resolution video from its corresponding low-resolution version, has recently drawn increasing attention. In this work, we propose a novel method that can effectively incorporate temporal information in a hierarchical way. The input sequence is divided into several groups, with each one corresponding to a kind of frame rate. These groups provide complementary information to recover missing details in the reference frame, which is further integrated with an attention module and a deep intra-group fusion module. In addition, a fast spatial alignment is proposed to handle videos with large motion. Extensive results demonstrate the capability of the proposed model in handling videos with various motion. It achieves favorable performance against state-of-the-art methods on several benchmark datasets.
CycAs: Self-supervised Cycle Association for Learning Re-identifiable Descriptions
Jul 15, 2020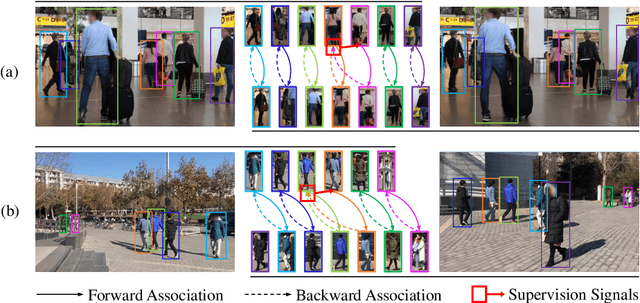
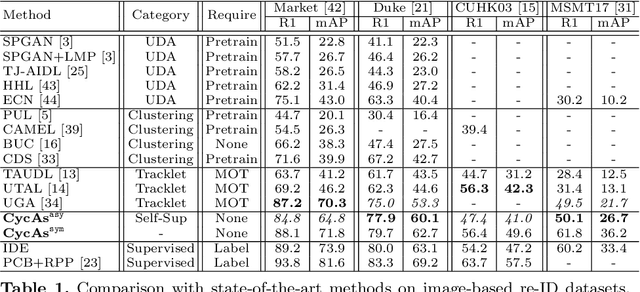
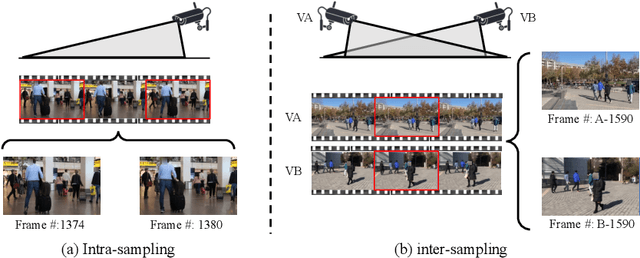
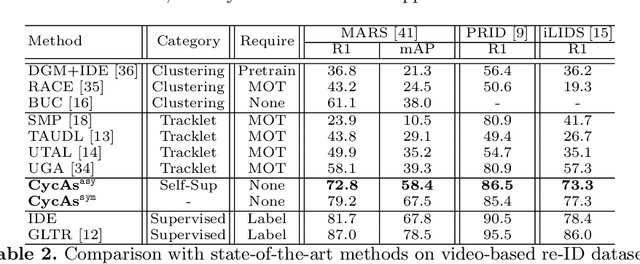
This paper proposes a self-supervised learning method for the person re-identification (re-ID) problem, where existing unsupervised methods usually rely on pseudo labels, such as those from video tracklets or clustering. A potential drawback of using pseudo labels is that errors may accumulate and it is challenging to estimate the number of pseudo IDs. We introduce a different unsupervised method that allows us to learn pedestrian embeddings from raw videos, without resorting to pseudo labels. The goal is to construct a self-supervised pretext task that matches the person re-ID objective. Inspired by the \emph{data association} concept in multi-object tracking, we propose the \textbf{Cyc}le \textbf{As}sociation (\textbf{CycAs}) task: after performing data association between a pair of video frames forward and then backward, a pedestrian instance is supposed to be associated to itself. To fulfill this goal, the model must learn a meaningful representation that can well describe correspondences between instances in frame pairs. We adapt the discrete association process to a differentiable form, such that end-to-end training becomes feasible. Experiments are conducted in two aspects: We first compare our method with existing unsupervised re-ID methods on seven benchmarks and demonstrate CycAs' superiority. Then, to further validate the practical value of CycAs in real-world applications, we perform training on self-collected videos and report promising performance on standard test sets.
Locality Aware Appearance Metric for Multi-Target Multi-Camera Tracking
Nov 27, 2019
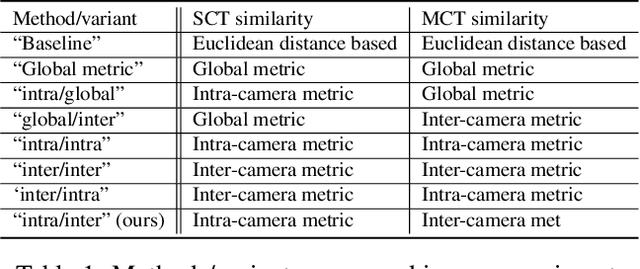
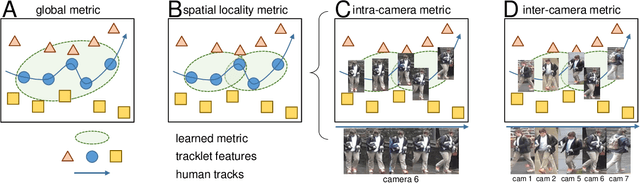
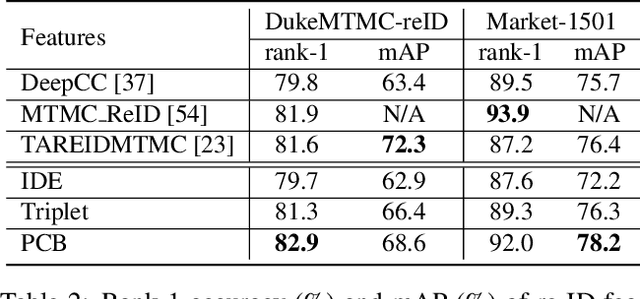
Multi-target multi-camera tracking (MTMCT) systems track targets across cameras. Due to the continuity of target trajectories, tracking systems usually restrict their data association within a local neighborhood. In single camera tracking, local neighborhood refers to consecutive frames; in multi-camera tracking, it refers to neighboring cameras that the target may appear successively. For similarity estimation, tracking systems often adopt appearance features learned from the re-identification (re-ID) perspective. Different from tracking, re-ID usually does not have access to the trajectory cues that can limit the search space to a local neighborhood. Due to its global matching property, the re-ID perspective requires to learn global appearance features. We argue that the mismatch between the local matching procedure in tracking and the global nature of re-ID appearance features may compromise MTMCT performance. To fit the local matching procedure in MTMCT, in this work, we introduce locality aware appearance metric (LAAM). Specifically, we design an intra-camera metric for single camera tracking, and an inter-camera metric for multi-camera tracking. Both metrics are trained with data pairs sampled from their corresponding local neighborhoods, as opposed to global sampling in the re-ID perspective. We show that the locally learned metrics can be successfully applied on top of several globally learned re-ID features. With the proposed method, we report new state-of-the-art performance on the DukeMTMC dataset, and a substantial improvement on the CityFlow dataset.
Towards Real-Time Multi-Object Tracking
Sep 27, 2019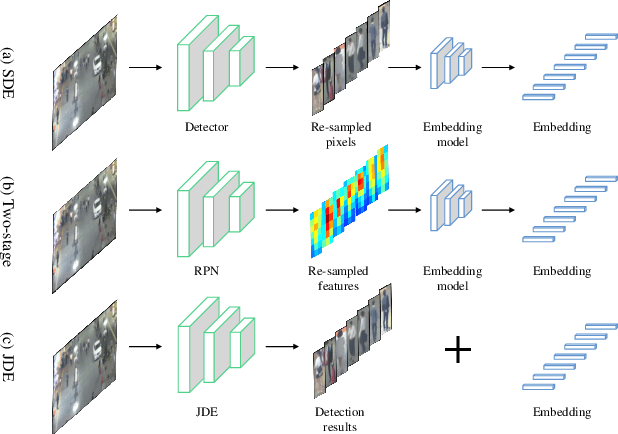
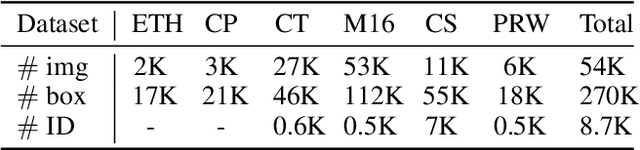
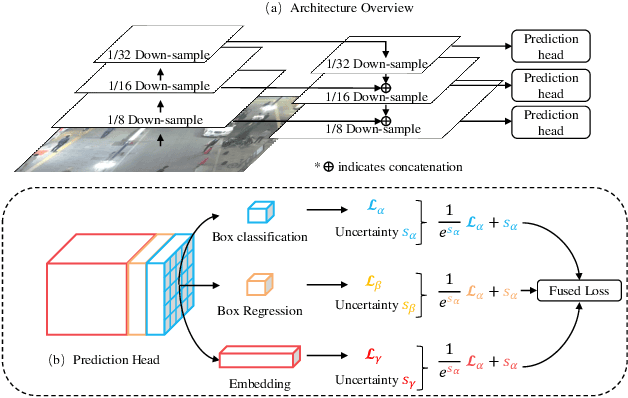
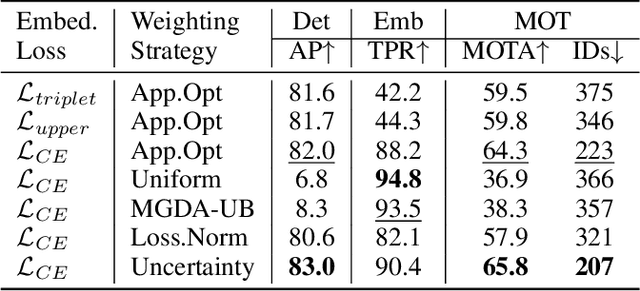
Modern multiple object tracking (MOT) systems usually follow the tracking-by-detection paradigm. It has 1) a detection model for target localization and 2) an appearance embedding model for data association. Having the two models separately executed might lead to efficiency problems, as the running time is simply a sum of the two steps without investigating potential structures that can be shared between them. Existing research efforts on real-time MOT usually focus on the association step, so they are essentially real-time association methods but not real-time MOT system. In this paper, we propose an MOT system that allows target detection and appearance embedding to be learned in a shared model. Specifically, we incorporate the appearance embedding model into a single-shot detector, such that the model can simultaneously output detections and the corresponding embeddings. As such, the system is formulated as a multi-task learning problem: there are multiple objectives, i.e., anchor classification, bounding box regression, and embedding learning; and the individual losses are automatically weighted. To our knowledge, this work reports the first (near) real-time MOT system, with a running speed of 18.8 to 24.1 FPS depending on the input resolution. Meanwhile, its tracking accuracy is comparable to the state-of-the-art trackers embodying separate detection and embedding (SDE) learning (64.4% MOTA v.s. 66.1% MOTA on MOT-16 challenge). The code and models are available at https://github.com/Zhongdao/Towards-Realtime-MOT.
Adversarial View-Consistent Learning for Monocular Depth Estimation
Aug 04, 2019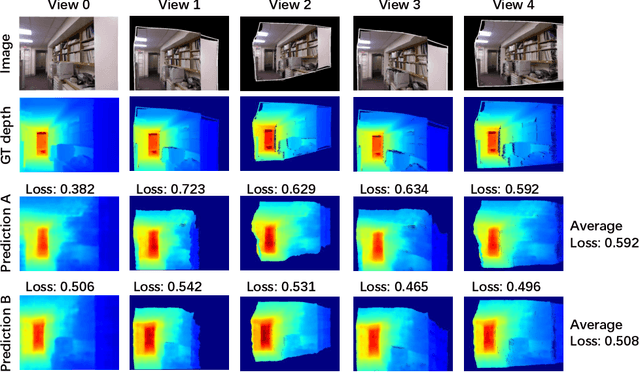
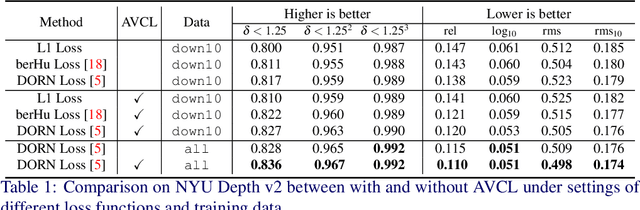
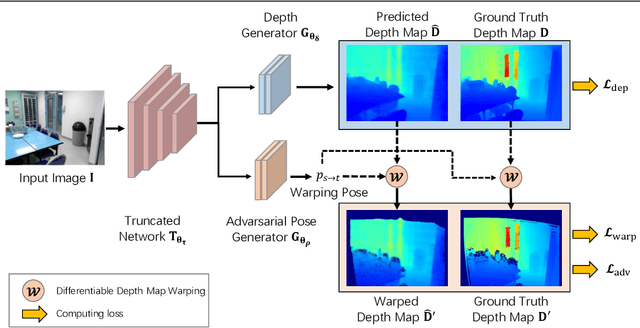

This paper addresses the problem of Monocular Depth Estimation (MDE). Existing approaches on MDE usually model it as a pixel-level regression problem, ignoring the underlying geometry property. We empirically find this may result in sub-optimal solution: while the predicted depth map presents small loss value in one specific view, it may exhibit large loss if viewed in different directions. In this paper, inspired by multi-view stereo (MVS), we propose an Adversarial View-Consistent Learning (AVCL) framework to force the estimated depth map to be all reasonable viewed from multiple views. To this end, we first design a differentiable depth map warping operation, which is end-to-end trainable, and then propose a pose generator to generate novel views for a given image in an adversarial manner. Collaborating with the differentiable depth map warping operation, the pose generator encourages the depth estimation network to learn from hard views, hence produce view-consistent depth maps . We evaluate our method on NYU Depth V2 dataset and the experimental results show promising performance gain upon state-of-the-art MDE approaches.
Softmax Dissection: Towards Understanding Intra- and Inter-clas Objective for Embedding Learning
Aug 04, 2019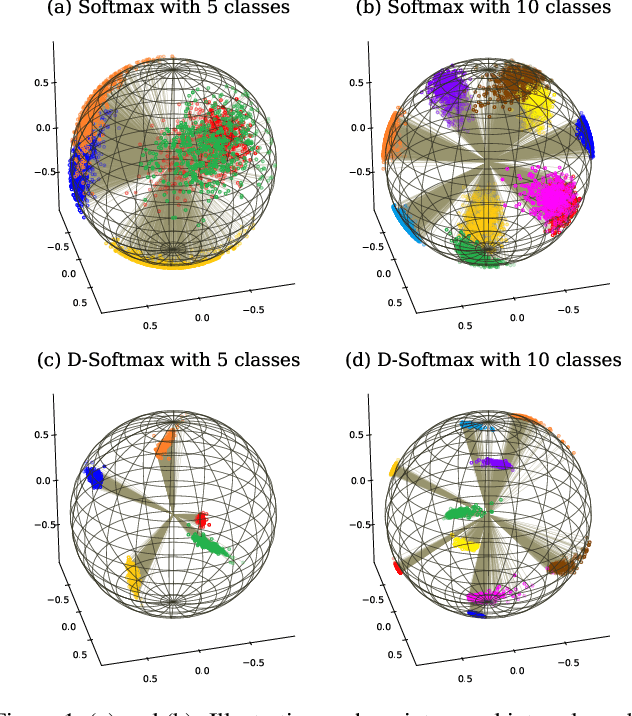
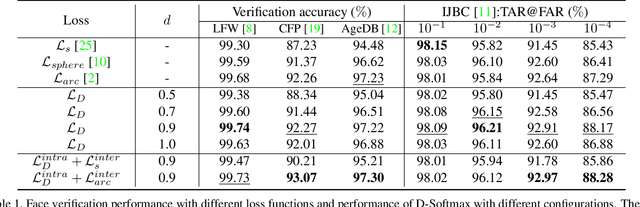
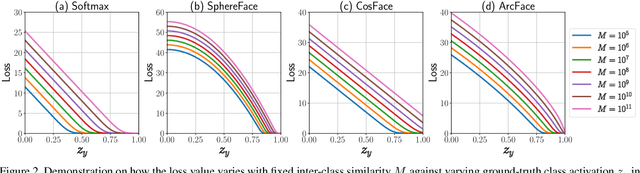
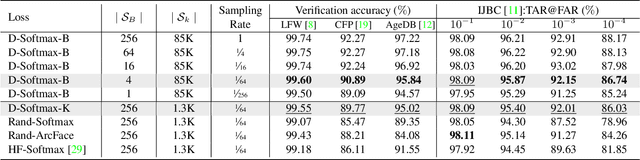
The softmax loss and its variants are widely used as objectives for embedding learning, especially in applications like face recognition. However, the intra- and inter-class objectives in the softmax loss are entangled, therefore a well-optimized inter-class objective leads to relaxation on the intra-class objective, and vice versa. In this paper, we propose to dissect the softmax loss into independent intra- and inter-class objective (D-Softmax). With D-Softmax as objective, we can have a clear understanding of both the intra- and inter-class objective, therefore it is straightforward to tune each part to the best state. Furthermore, we find the computation of the inter-class objective is redundant and propose two sampling-based variants of D-Softmax to reduce the computation cost. Training with regular-scale data, experiments in face verification show D-Softmax is favorably comparable to existing losses such as SphereFace and ArcFace. Training with massive-scale data, experiments show the fast variants of D-Softmax significantly accelerates the training process (such as 64x) with only a minor sacrifice in performance, outperforming existing acceleration methods of softmax in terms of both performance and efficiency.
Hierarchical Structure and Joint Training for Large Scale Semi-supervised Object Detection
May 30, 2019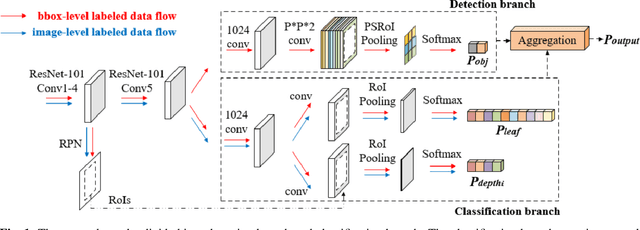
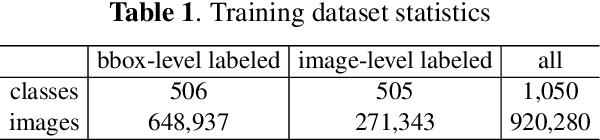
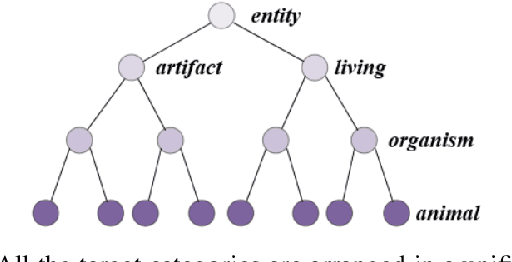
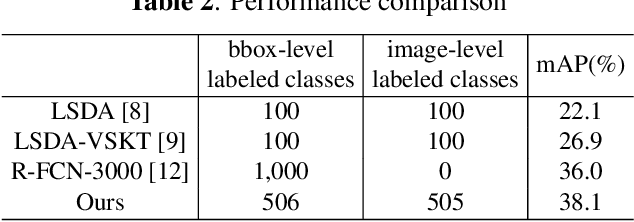
Generic object detection is one of the most fundamental and important problems in computer vision. When it comes to large scale object detection for thousands of categories, it is unpractical to provide all the bounding box labels for each category. In this paper, we propose a novel hierarchical structure and joint training framework for large scale semi-supervised object detection. First, we utilize the relationships among target categories to model a hierarchical network to further improve the performance of recognition. Second, we combine bounding-box-level labeled images and image-level labeled images together for joint training, and the proposed method can be easily applied in current two-stage object detection framework with excellent performance. Experimental results show that the proposed large scale semi-supervised object detection network obtains the state-of-the-art performance, with the mAP of 38.1% on the ImageNet detection validation dataset.