 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-Grasp: a 6-Dof Interactive Grasp Policy for Language-Oriented Objects in Cluttered Indoor Scenes
Aug 01, 2023Robotic grasping faces new challenges in human-robot-interaction scenarios. We consider the task that the robot grasps a target object designated by human's language directives. The robot not only needs to locate a target based on vision-and-language information, but also needs to predict the reasonable grasp pose candidate at various views and postures. In this work, we propose a novel interactive grasp policy, named Visual-Lingual-Grasp (VL-Grasp), to grasp the target specified by human language. First, we build a new challenging visual grounding dataset to provide functional training data for robotic interactive perception in indoor environments. Second, we propose a 6-Dof interactive grasp policy combined with visual grounding and 6-Dof grasp pose detection to extend the universality of interactive grasping. Third, we design a grasp pose filter module to enhance the performance of the policy. Experiments demonstrate the effectiveness and extendibility of the VL-Grasp in real world. The VL-Grasp achieves a success rate of 72.5\% in different indoor scenes. The code and dataset is available at https://github.com/luyh20/VL-Grasp.
Learning Prompt-Enhanced Context Features for Weakly-Supervised Video Anomaly Detection
Jun 26, 2023



Video anomaly detection under weak supervision is challenging due to the absence of frame-level annotations during the training phase. Previous work has employed graph convolution networks or self-attention mechanisms to model temporal relations, along with multiple instance learning (MIL)-based classification loss to learn discriminative features. However, most of them utilize multi-branches to capture local and global dependencies separately, leading to increased parameters and computational cost. Furthermore, the binarized constraint of the MIL-based loss only ensures coarse-grained interclass separability, ignoring fine-grained discriminability within anomalous classes. In this paper, we propose a weakly supervised anomaly detection framework that emphasizes efficient context modeling and enhanced semantic discriminability. To this end, we first construct a temporal context aggregation (TCA) module that captures complete contextual information by reusing similarity matrix and adaptive fusion. Additionally, we propose a prompt-enhanced learning (PEL) module that incorporates semantic priors into the model by utilizing knowledge-based prompts, aiming at enhancing the discriminative capacity of context features while ensuring separability between anomaly sub-classes. Furthermore, we introduce a score smoothing (SS) module in the testing phase to suppress individual bias and reduce false alarms. Extensive experiments demonstrate the effectiveness of various components of our method, which achieves competitive performance with fewer parameters and computational effort on three challenging benchmarks: the UCF-crime, XD-violence, and ShanghaiTech datasets. The detection accuracy of some anomaly sub-classes is also improved with a great margin.
Detecting Everything in the Open World: Towards Universal Object Detection
Mar 27, 2023In this paper, we formally address universal object detection, which aims to detect every scene and predict every category. The dependence on human annotations, the limited visual information, and the novel categories in the open world severely restrict the universality of traditional detectors. We propose UniDetector, a universal object detector that has the ability to recognize enormous categories in the open world. The critical points for the universality of UniDetector are: 1) it leverages images of multiple sources and heterogeneous label spaces for training through the alignment of image and text spaces, which guarantees sufficient information for universal representations. 2) it generalizes to the open world easily while keeping the balance between seen and unseen classes, thanks to abundant information from both vision and language modalities. 3) it further promotes the generalization ability to novel categories through our proposed decoupling training manner and probability calibration. These contributions allow UniDetector to detect over 7k categories, the largest measurable category size so far, with only about 500 classes participating in training. Our UniDetector behaves the strong zero-shot generalization ability on large-vocabulary datasets like LVIS, ImageNetBoxes, and VisualGenome - it surpasses the traditional supervised baselines by more than 4\% on average without seeing any corresponding images. On 13 public detection datasets with various scenes, UniDetector also achieves state-of-the-art performance with only a 3\% amount of training data.
Generalizable Re-Identification from Videos with Cycle Association
Nov 08, 2022In this paper, we are interested in learning a generalizable person re-identification (re-ID) representation from unlabeled videos. Compared with 1) the popular unsupervised re-ID setting where the training and test sets are typically under the same domain, and 2) the popular domain generalization (DG) re-ID setting where the training samples are labeled, our novel scenario combines their key challenges: the training samples are unlabeled, and collected form various domains which do no align with the test domain. In other words, we aim to learn a representation in an unsupervised manner and directly use the learned representation for re-ID in novel domains. To fulfill this goal, we make two main contributions: First, we propose Cycle Association (CycAs), a scalable self-supervised learning method for re-ID with low training complexity; and second, we construct a large-scale unlabeled re-ID dataset named LMP-video, tailored for the proposed method. Specifically, CycAs learns re-ID features by enforcing cycle consistency of instance association between temporally successive video frame pairs, and the training cost is merely linear to the data size, making large-scale training possible. On the other hand, the LMP-video dataset is extremely large, containing 50 million unlabeled person images cropped from over 10K Youtube videos, therefore is sufficient to serve as fertile soil for self-supervised learning. Trained on LMP-video, we show that CycAs learns good generalization towards novel domains. The achieved results sometimes even outperform supervised domain generalizable models. Remarkably, CycAs achieves 82.2% Rank-1 on Market-1501 and 49.0% Rank-1 on MSMT17 with zero human annotation, surpassing state-of-the-art supervised DG re-ID methods. Moreover, we also demonstrate the superiority of CycAs under the canonical unsupervised re-ID and the pretrain-and-finetune scenarios.
Reliability-Aware Prediction via Uncertainty Learning for Person Image Retrieval
Oct 24, 2022Current person image retrieval methods have achieved great improvements in accuracy metrics. However, they rarely describe the reliability of the prediction. In this paper, we propose an Uncertainty-Aware Learning (UAL) method to remedy this issue. UAL aims at providing reliability-aware predictions by considering data uncertainty and model uncertainty simultaneously. Data uncertainty captures the ``noise" inherent in the sample, while model uncertainty depicts the model's confidence in the sample's prediction. Specifically, in UAL, (1) we propose a sampling-free data uncertainty learning method to adaptively assign weights to different samples during training, down-weighting the low-quality ambiguous samples. (2) we leverage the Bayesian framework to model the model uncertainty by assuming the parameters of the network follow a Bernoulli distribution. (3) the data uncertainty and the model uncertainty are jointly learned in a unified network, and they serve as two fundamental criteria for the reliability assessment: if a probe is high-quality (low data uncertainty) and the model is confident in the prediction of the probe (low model uncertainty), the final ranking will be assessed as reliable. Experiments under the risk-controlled settings and the multi-query settings show the proposed reliability assessment is effective. Our method also shows superior performance on three challenging benchmarks under the vanilla single query settings.
Self-Supervised Learning via Maximum Entropy Coding
Oct 20, 2022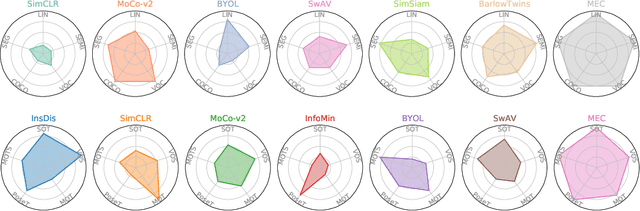
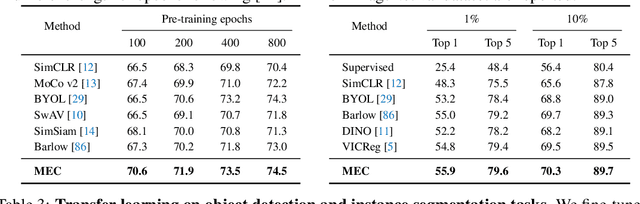
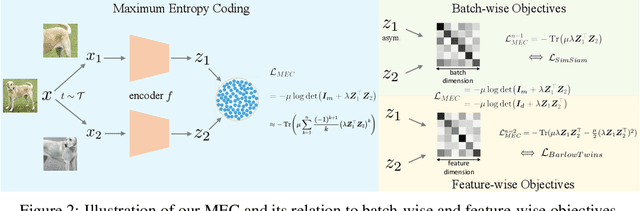
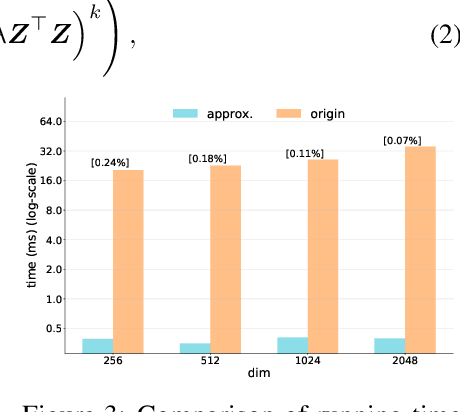
A mainstream type of current self-supervised learning methods pursues a general-purpose representation that can be well transferred to downstream tasks, typically by optimizing on a given pretext task such as instance discrimination. In this work, we argue that existing pretext tasks inevitably introduce biases into the learned representation, which in turn leads to biased transfer performance on various downstream tasks. To cope with this issue, we propose Maximum Entropy Coding (MEC), a more principled objective that explicitly optimizes on the structure of the representation, so that the learned representation is less biased and thus generalizes better to unseen downstream tasks. Inspired by the principle of maximum entropy in information theory, we hypothesize that a generalizable representation should be the one that admits the maximum entropy among all plausible representations. To make the objective end-to-end trainable, we propose to leverage the minimal coding length in lossy data coding as a computationally tractable surrogate for the entropy, and further derive a scalable reformulation of the objective that allows fast computation. Extensive experiments demonstrate that MEC learns a more generalizable representation than previous methods based on specific pretext tasks. It achieves state-of-the-art performance consistently on various downstream tasks, including not only ImageNet linear probe, but also semi-supervised classification, object detection, instance segmentation, and object tracking. Interestingly, we show that existing batch-wise and feature-wise self-supervised objectives could be seen equivalent to low-order approximations of MEC. Code and pre-trained models are available at https://github.com/xinliu20/MEC.
GraphCSPN: Geometry-Aware Depth Completion via Dynamic GCNs
Oct 19, 2022
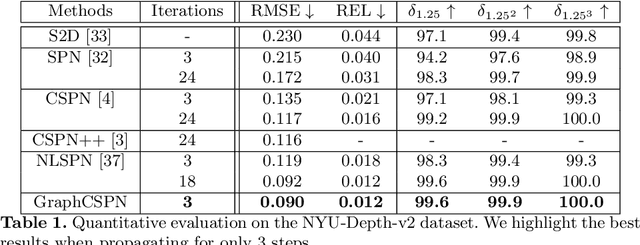
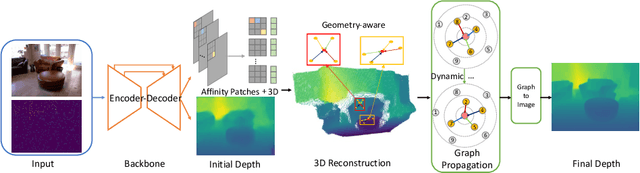
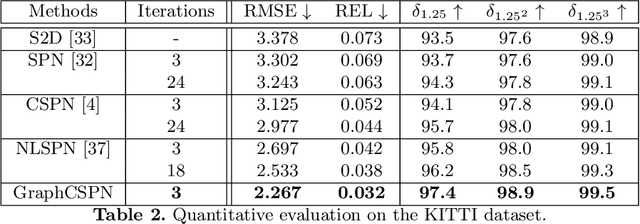
Image guided depth completion aims to recover per-pixel dense depth maps from sparse depth measurements with the help of aligned color images, which has a wide range of applications from robotics to autonomous driving. However, the 3D nature of sparse-to-dense depth completion has not been fully explored by previous methods. In this work, we propose a Graph Convolution based Spatial Propagation Network (GraphCSPN) as a general approach for depth completion. First, unlike previous methods, we leverage convolution neural networks as well as graph neural networks in a complementary way for geometric representation learning. In addition, the proposed networks explicitly incorporate learnable geometric constraints to regularize the propagation process performed in three-dimensional space rather than in two-dimensional plane. Furthermore, we construct the graph utilizing sequences of feature patches, and update it dynamically with an edge attention module during propagation, so as to better capture both the local neighboring features and global relationships over long distance. Extensive experiments on both indoor NYU-Depth-v2 and outdoor KITTI datasets demonstrate that our method achieves the state-of-the-art performance, especially when compared in the case of using only a few propagation steps. Code and models are available at the project page.
Portrait Interpretation and a Benchmark
Jul 27, 2022We propose a task we name Portrait Interpretation and construct a dataset named Portrait250K for it. Current researches on portraits such as human attribute recognition and person re-identification have achieved many successes, but generally, they: 1) may lack mining the interrelationship between various tasks and the possible benefits it may bring; 2) design deep models specifically for each task, which is inefficient; 3) may be unable to cope with the needs of a unified model and comprehensive perception in actual scenes. In this paper, the proposed portrait interpretation recognizes the perception of humans from a new systematic perspective. We divide the perception of portraits into three aspects, namely Appearance, Posture, and Emotion, and design corresponding sub-tasks for each aspect. Based on the framework of multi-task learning, portrait interpretation requires a comprehensive description of static attributes and dynamic states of portraits. To invigorate research on this new task, we construct a new dataset that contains 250,000 images labeled with identity, gender, age, physique, height, expression, and posture of the whole body and arms. Our dataset is collected from 51 movies, hence covering extensive diversity. Furthermore, we focus on representation learning for portrait interpretation and propose a baseline that reflects our systematic perspective. We also propose an appropriate metric for this task. Our experimental results demonstrate that combining the tasks related to portrait interpretation can yield benefits. Code and dataset will be made public.
Hybrid Physical Metric For 6-DoF Grasp Pose Detection
Jun 22, 2022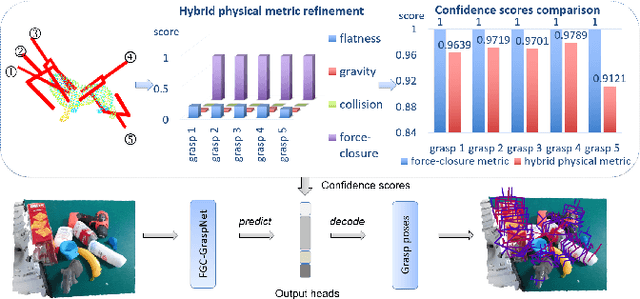
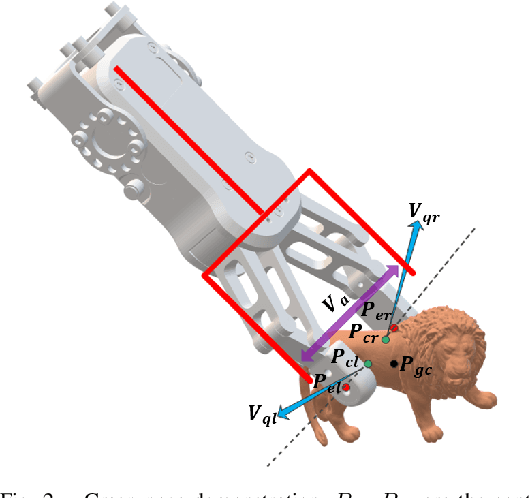
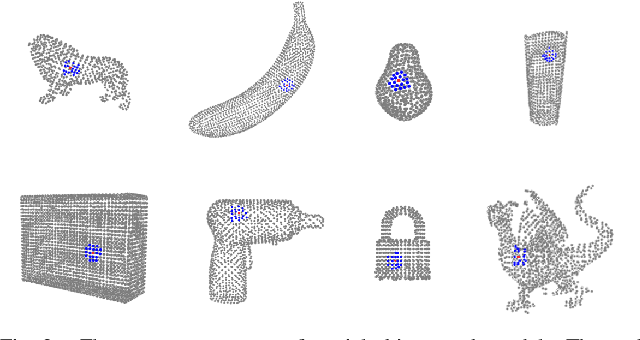
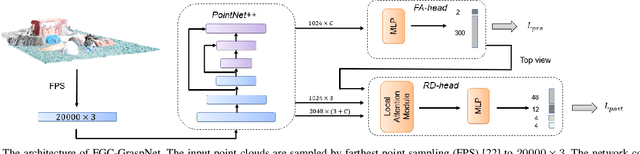
6-DoF grasp pose detection of multi-grasp and multi-object is a challenge task in the field of intelligent robot. To imitate human reasoning ability for grasping objects, data driven methods are widely studied. With the introduction of large-scale datasets, we discover that a single physical metric usually generates several discrete levels of grasp confidence scores, which cannot finely distinguish millions of grasp poses and leads to inaccurate prediction results. In this paper, we propose a hybrid physical metric to solve this evaluation insufficiency. First, we define a novel metric is based on the force-closure metric, supplemented by the measurement of the object flatness, gravity and collision. Second, we leverage this hybrid physical metric to generate elaborate confidence scores. Third, to learn the new confidence scores effectively, we design a multi-resolution network called Flatness Gravity Collision GraspNet (FGC-GraspNet). FGC-GraspNet proposes a multi-resolution features learning architecture for multiple tasks and introduces a new joint loss function that enhances the average precision of the grasp detection. The network evaluation and adequate real robot experiments demonstrate the effectiveness of our hybrid physical metric and FGC-GraspNet. Our method achieves 90.5\% success rate in real-world cluttered scenes. Our code is available at https://github.com/luyh20/FGC-GraspNet.
R^2: Randomized Decision Routing for Object Detection
Apr 02, 2022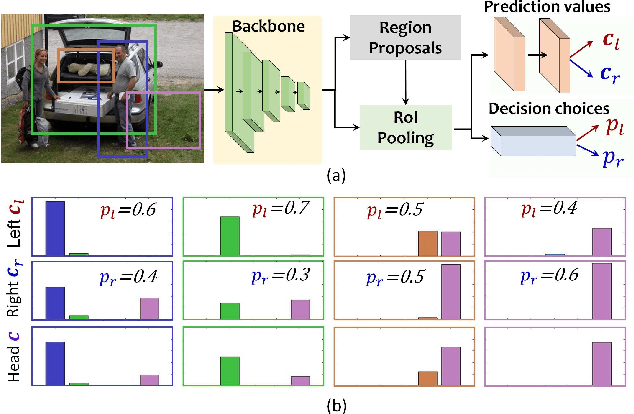
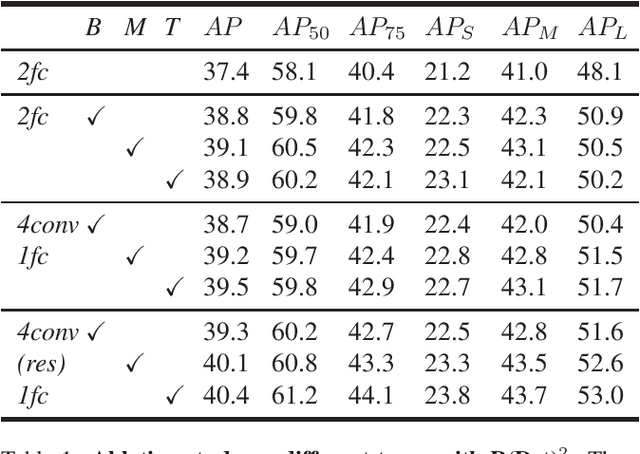
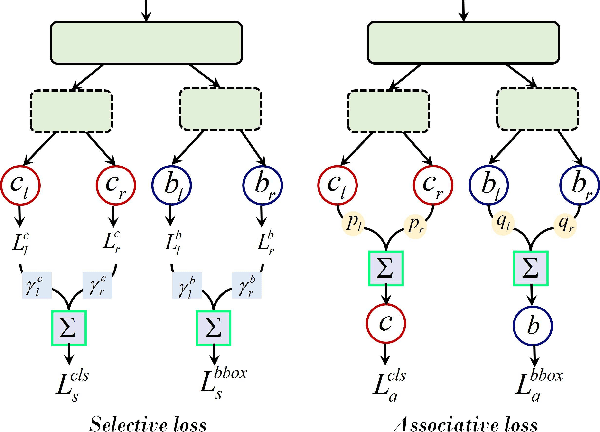
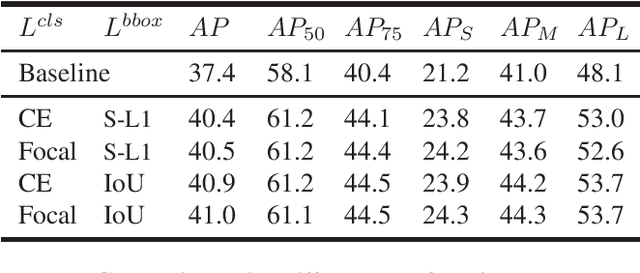
In the paradigm of object detection, the decision head is an important part, which affects detection performance significantly. Yet how to design a high-performance decision head remains to be an open issue. In this paper, we propose a novel approach to combine decision trees and deep neural networks in an end-to-end learning manner for object detection. First, we disentangle the decision choices and prediction values by plugging soft decision trees into neural networks. To facilitate effective learning, we propose randomized decision routing with node selective and associative losses, which can boost the feature representative learning and network decision simultaneously. Second, we develop the decision head for object detection with narrow branches to generate the routing probabilities and masks, for the purpose of obtaining divergent decisions from different nodes. We name this approach as the randomized decision routing for object detection, abbreviated as R(Det)$^2$. Experiments on MS-COCO dataset demonstrate that R(Det)$^2$ is effective to improve the detection performance. Equipped with existing detectors, it achieves $1.4\sim 3.6$\% AP improvement.