 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoisonBench: Assessing Large Language Model Vulnerability to Data Poisoning
Oct 11, 2024



Preference learning is a central component for aligning current LLMs, but this process can be vulnerable to data poisoning attacks. To address this concern, we introduce PoisonBench, a benchmark for evaluating large language models' susceptibility to data poisoning during preference learning. Data poisoning attacks can manipulate large language model responses to include hidden malicious content or biases, potentially causing the model to generate harmful or unintended outputs while appearing to function normally. We deploy two distinct attack types across eight realistic scenarios, assessing 21 widely-used models. Our findings reveal concerning trends: (1) Scaling up parameter size does not inherently enhance resilience against poisoning attacks; (2) There exists a log-linear relationship between the effects of the attack and the data poison ratio; (3) The effect of data poisoning can generalize to extrapolated triggers that are not included in the poisoned data. These results expose weaknesses in current preference learning techniques, highlighting the urgent need for more robust defenses against malicious models and data manipulation.
What can Large Language Models Capture about Code Functional Equivalence?
Aug 20, 2024



Code-LLMs, LLMs pre-trained on large code corpora, have shown great progress in learning rich representations of the structure and syntax of code, successfully using it to generate or classify code fragments. At the same time, understanding if they are able to do so because they capture code semantics, and how well, is still an open question. In this paper, we tackle this problem by introducing SeqCoBench, a benchmark for systematically assessing how Code-LLMs can capture code functional equivalence. SeqCoBench contains over 20 code transformations that either preserve or alter the semantics of Python programs. We conduct extensive evaluations in different settings, including zero-shot and parameter-efficient finetuning methods on state-of-the-art (Code-)LLMs to see if they can discern semantically equivalent or different pairs of programs in SeqCoBench. We find that the performance gap between these LLMs and classical match-based retrieval scores is minimal, with both approaches showing a concerning lack of depth in understanding code semantics.
Evaluating Automatic Metrics with Incremental Machine Translation Systems
Jul 03, 2024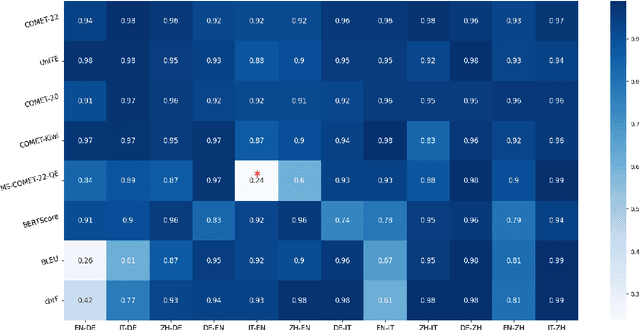
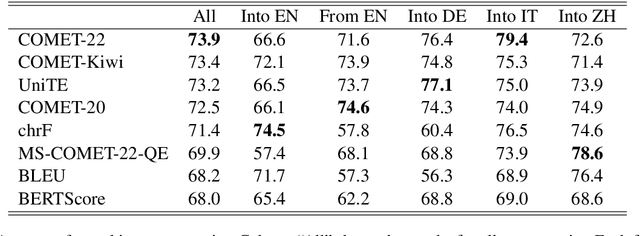
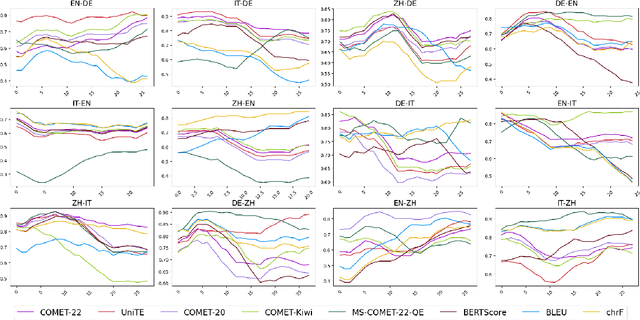
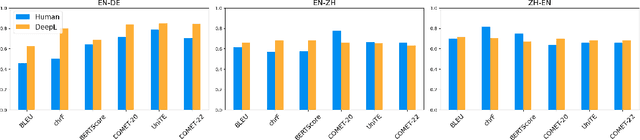
We introduce a dataset comprising commercial machine translations, gathered weekly over six years across 12 translation directions. Since human A/B testing is commonly used, we assume commercial systems improve over time, which enables us to evaluate machine translation (MT) metrics based on their preference for more recent translations. Our study confirms several previous findings in MT metrics research and demonstrates the dataset's value as a testbed for metric evaluation. We release our code at https://github.com/gjwubyron/Evo
einspace: Searching for Neural Architectures from Fundamental Operations
May 31, 2024



Neural architecture search (NAS) finds high performing networks for a given task. Yet the results of NAS are fairly prosaic; they did not e.g. create a shift from convolutional structures to transformers. This is not least because the search spaces in NAS often aren't diverse enough to include such transformations a priori. Instead, for NAS to provide greater potential for fundamental design shifts, we need a novel expressive search space design which is built from more fundamental operations. To this end, we introduce einspace, a search space based on a parameterised probabilistic context-free grammar. Our space is versatile, supporting architectures of various sizes and complexities, while also containing diverse network operations which allow it to model convolutions, attention components and more. It contains many existing competitive architectures, and provides flexibility for discovering new ones. Using this search space, we perform experiments to find novel architectures as well as improvements on existing ones on the diverse Unseen NAS datasets. We show that competitive architectures can be obtained by searching from scratch, and we consistently find large improvements when initialising the search with strong baselines. We believe that this work is an important advancement towards a transformative NAS paradigm where search space expressivity and strategic search initialisation play key roles.
Spectral Editing of Activations for Large Language Model Alignment
May 15, 2024



Large language models (LLMs) often exhibit undesirable behaviours, such as generating untruthful or biased content. Editing their internal representations has been shown to be effective in mitigating such behaviours on top of the existing alignment methods. We propose a novel inference-time editing method, namely spectral editing of activations (SEA), to project the input representations into directions with maximal covariance with the positive demonstrations (e.g., truthful) while minimising covariance with the negative demonstrations (e.g., hallucinated). We also extend our method to non-linear editing using feature functions. We run extensive experiments on benchmarks concerning truthfulness and bias with six open-source LLMs of different sizes and model families. The results demonstrate the superiority of SEA in effectiveness, generalisation to similar tasks, as well as inference and data efficiency. We also show that SEA editing only has a limited negative impact on other model capabilities.
LeanReasoner: Boosting Complex Logical Reasoning with Lean
Mar 20, 2024Large language models (LLMs) often struggle with complex logical reasoning due to logical inconsistencies and the inherent difficulty of such reasoning. We use Lean, a theorem proving framework, to address these challenges. By formalizing logical reasoning problems into theorems within Lean, we can solve them by proving or disproving the corresponding theorems. This method reduces the risk of logical inconsistencies with the help of Lean's symbolic solver. It also enhances our ability to treat complex reasoning tasks by using Lean's extensive library of theorem proofs. Our method achieves state-of-the-art performance on the FOLIO dataset and achieves performance near this level on ProofWriter. Notably, these results were accomplished by fine-tuning on fewer than 100 in-domain samples for each dataset.
Interpreting Context Look-ups in Transformers: Investigating Attention-MLP Interactions
Feb 23, 2024In this paper, we investigate the interplay between attention heads and specialized "next-token" neurons in the Multilayer Perceptron that predict specific tokens. By prompting an LLM like GPT-4 to explain these model internals, we can elucidate attention mechanisms that activate certain next-token neurons. Our analysis identifies attention heads that recognize contexts relevant to predicting a particular token, activating the associated neuron through the residual connection. We focus specifically on heads in earlier layers consistently activating the same next-token neuron across similar prompts. Exploring these differential activation patterns reveals that heads that specialize for distinct linguistic contexts are tied to generating certain tokens. Overall, our method combines neural explanations and probing isolated components to illuminate how attention enables context-dependent, specialized processing in LLMs.
`Keep it Together': Enforcing Cohesion in Extractive Summaries by Simulating Human Memory
Feb 16, 2024



Extractive summaries are usually presented as lists of sentences with no expected cohesion between them. In this paper, we aim to enforce cohesion whilst controlling for informativeness and redundancy in summaries, in cases where the input exhibits high redundancy. The pipeline controls for redundancy in long inputs as it is consumed, and balances informativeness and cohesion during sentence selection. Our sentence selector simulates human memory to keep track of topics --modeled as lexical chains--, enforcing cohesive ties between noun phrases. Across a variety of domains, our experiments revealed that it is possible to extract highly cohesive summaries that nevertheless read as informative to humans as summaries extracted by only accounting for informativeness or redundancy. The extracted summaries exhibit smooth topic transitions between sentences as signaled by lexical chains, with chains spanning adjacent or near-adjacent sentences.
Can Large Language Model Summarizers Adapt to Diverse Scientific Communication Goals?
Jan 18, 2024In this work, we investigate the controllability of large language models (LLMs) on scientific summarization tasks. We identify key stylistic and content coverage factors that characterize different types of summaries such as paper reviews, abstracts, and lay summaries. By controlling stylistic features, we find that non-fine-tuned LLMs outperform humans in the MuP review generation task, both in terms of similarity to reference summaries and human preferences. Also, we show that we can improve the controllability of LLMs with keyword-based classifier-free guidance (CFG) while achieving lexical overlap comparable to strong fine-tuned baselines on arXiv and PubMed. However, our results also indicate that LLMs cannot consistently generate long summaries with more than 8 sentences. Furthermore, these models exhibit limited capacity to produce highly abstractive lay summaries. Although LLMs demonstrate strong generic summarization competency, sophisticated content control without costly fine-tuning remains an open problem for domain-specific applications.
Large Language Models Relearn Removed Concepts
Jan 03, 2024Advances in model editing through neuron pruning hold promise for removing undesirable concepts from large language models. However, it remains unclear whether models have the capacity to reacquire pruned concepts after editing. To investigate this, we evaluate concept relearning in models by tracking concept saliency and similarity in pruned neurons during retraining. Our findings reveal that models can quickly regain performance post-pruning by relocating advanced concepts to earlier layers and reallocating pruned concepts to primed neurons with similar semantics. This demonstrates that models exhibit polysemantic capacities and can blend old and new concepts in individual neurons. While neuron pruning provides interpretability into model concepts, our results highlight the challenges of permanent concept removal for improved model \textit{safety}. Monitoring concept reemergence and developing techniques to mitigate relearning of unsafe concepts will be important directions for more robust model editing. Overall, our work strongly demonstrates the resilience and fluidity of concept representations in LLMs post concept removal.