 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Compress (and Decompress)? Evaluating Code Understanding and Execution via Invertibility
Jan 19, 2026LLMs demonstrate strong performance on code benchmarks, yet round-trip code execution reveals limitations in their ability to maintain consistent reasoning across forward and backward execution. We present RoundTripCodeEval (RTCE), a comprehensive benchmark consisting of four distinct code execution reasoning tasks designed to rigorously test round-trip consistency. RTCE provides an execution-free, exact-match evaluation of bijection fidelity, assessing whether models preserve a consistent one-to-one mapping between encoding and decoding operations across various algorithms and directions. We systematically evaluate state-of-the-art Code-LLMs using zero-shot prompting, supervised fine-tuning on execution traces, and self-reflection mechanisms. Each yields modest improvements, but none closes the gap, indicating that current LLMs struggle with true round-trip consistency, which demonstrates that they lack the internal coherence required for trustworthy code reasoning. RTCE surfaces several new and previously unmeasured insights that are not captured by existing I/O-prediction, execution-reasoning, or round-trip natural-language benchmarks. We will release the code and the dataset upon acceptance.
What can Large Language Models Capture about Code Functional Equivalence?
Aug 20, 2024



Code-LLMs, LLMs pre-trained on large code corpora, have shown great progress in learning rich representations of the structure and syntax of code, successfully using it to generate or classify code fragments. At the same time, understanding if they are able to do so because they capture code semantics, and how well, is still an open question. In this paper, we tackle this problem by introducing SeqCoBench, a benchmark for systematically assessing how Code-LLMs can capture code functional equivalence. SeqCoBench contains over 20 code transformations that either preserve or alter the semantics of Python programs. We conduct extensive evaluations in different settings, including zero-shot and parameter-efficient finetuning methods on state-of-the-art (Code-)LLMs to see if they can discern semantically equivalent or different pairs of programs in SeqCoBench. We find that the performance gap between these LLMs and classical match-based retrieval scores is minimal, with both approaches showing a concerning lack of depth in understanding code semantics.
Co-training an Unsupervised Constituency Parser with Weak Supervision
Oct 05, 2021
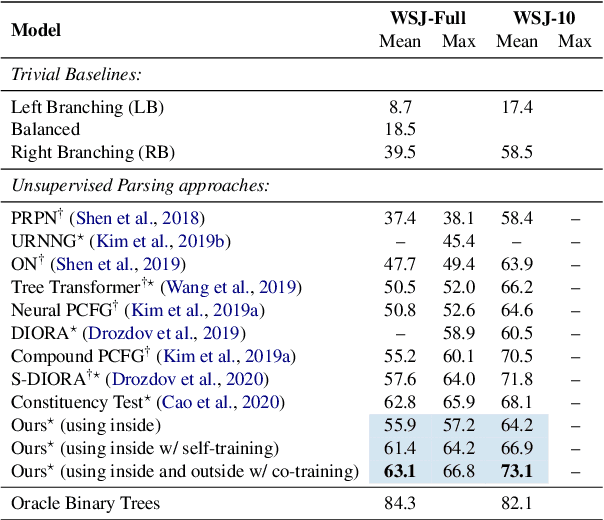

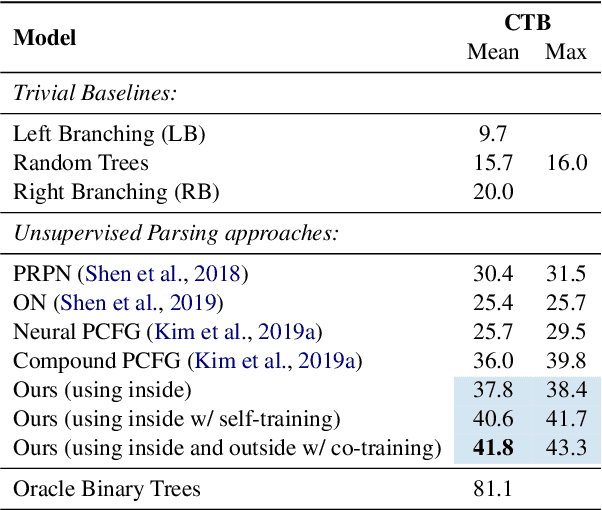
We introduce a method for unsupervised parsing that relies on bootstrapping classifiers to identify if a node dominates a specific span in a sentence. There are two types of classifiers, an inside classifier that acts on a span, and an outside classifier that acts on everything outside of a given span. Through self-training and co-training with the two classifiers, we show that the interplay between them helps improve the accuracy of both, and as a result, effectively parse. A seed bootstrapping technique prepares the data to train these classifiers. Our analyses further validate that such an approach in conjunction with weak supervision using prior branching knowledge of a known language (left/right-branching) and minimal heuristics injects strong inductive bias into the parser, achieving 63.1 F$_1$ on the English (PTB) test set. In addition, we show the effectiveness of our architecture by evaluating on treebanks for Chinese (CTB) and Japanese (KTB) and achieve new state-of-the-art results.\footnote{For code or data, please contact the authors.}
EdinburghNLP at WNUT-2020 Task 2: Leveraging Transformers with Generalized Augmentation for Identifying Informativeness in COVID-19 Tweets
Oct 08, 2020
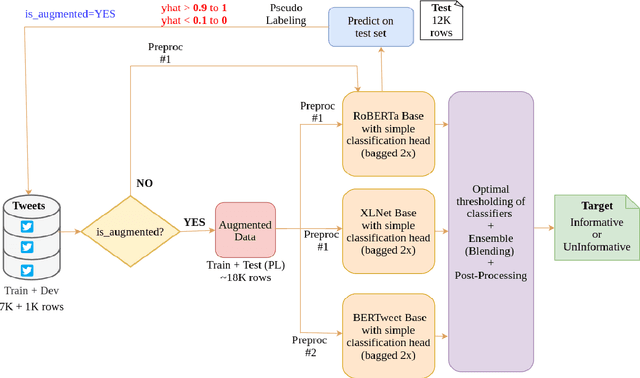
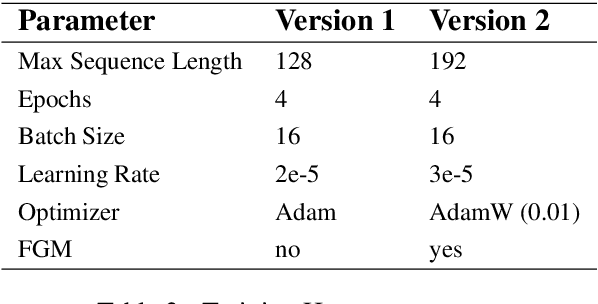
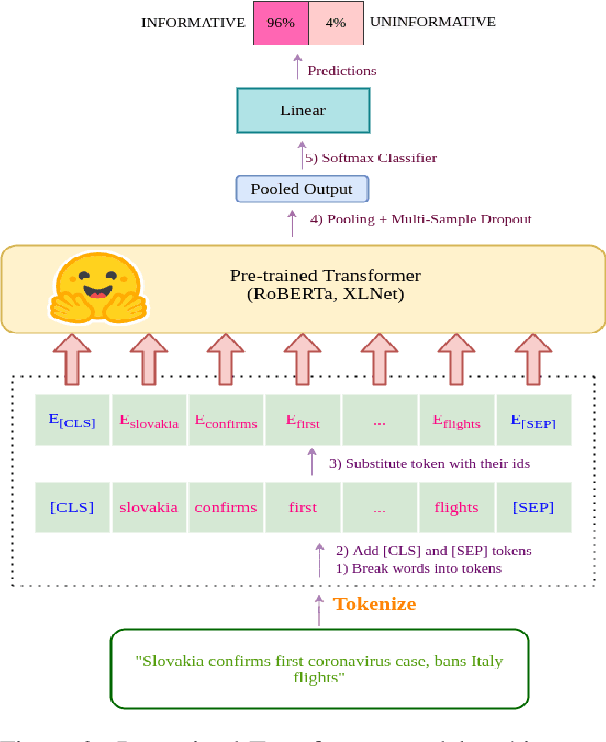
Twitter has become an important communication channel in times of emergency. The ubiquitousness of smartphones enables people to announce an emergency they're observing in real-time. Because of this, more agencies are interested in programatically monitoring Twitter (disaster relief organizations and news agencies) and therefore recognizing the informativeness of a tweet can help filter noise from large volumes of data. In this paper, we present our submission for WNUT-2020 Task 2: Identification of informative COVID-19 English Tweets. Our most successful model is an ensemble of transformers including RoBERTa, XLNet, and BERTweet trained in a semi-supervised experimental setting. The proposed system achieves a F1 score of 0.9011 on the test set (ranking 7th on the leaderboard), and shows significant gains in performance compared to a baseline system using fasttext embeddings.