 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeeinspace: Searching for Neural Architectures from Fundamental Operations
May 31, 2024



Neural architecture search (NAS) finds high performing networks for a given task. Yet the results of NAS are fairly prosaic; they did not e.g. create a shift from convolutional structures to transformers. This is not least because the search spaces in NAS often aren't diverse enough to include such transformations a priori. Instead, for NAS to provide greater potential for fundamental design shifts, we need a novel expressive search space design which is built from more fundamental operations. To this end, we introduce einspace, a search space based on a parameterised probabilistic context-free grammar. Our space is versatile, supporting architectures of various sizes and complexities, while also containing diverse network operations which allow it to model convolutions, attention components and more. It contains many existing competitive architectures, and provides flexibility for discovering new ones. Using this search space, we perform experiments to find novel architectures as well as improvements on existing ones on the diverse Unseen NAS datasets. We show that competitive architectures can be obtained by searching from scratch, and we consistently find large improvements when initialising the search with strong baselines. We believe that this work is an important advancement towards a transformative NAS paradigm where search space expressivity and strategic search initialisation play key roles.
Adversarial Augmentation Training Makes Action Recognition Models More Robust to Realistic Video Distribution Shifts
Jan 21, 2024Despite recent advances in video action recognition achieving strong performance on existing benchmarks, these models often lack robustness when faced with natural distribution shifts between training and test data. We propose two novel evaluation methods to assess model resilience to such distribution disparity. One method uses two different datasets collected from different sources and uses one for training and validation, and the other for testing. More precisely, we created dataset splits of HMDB-51 or UCF-101 for training, and Kinetics-400 for testing, using the subset of the classes that are overlapping in both train and test datasets. The other proposed method extracts the feature mean of each class from the target evaluation dataset's training data (i.e. class prototype) and estimates test video prediction as a cosine similarity score between each sample to the class prototypes of each target class. This procedure does not alter model weights using the target dataset and it does not require aligning overlapping classes of two different datasets, thus is a very efficient method to test the model robustness to distribution shifts without prior knowledge of the target distribution. We address the robustness problem by adversarial augmentation training - generating augmented views of videos that are "hard" for the classification model by applying gradient ascent on the augmentation parameters - as well as "curriculum" scheduling the strength of the video augmentations. We experimentally demonstrate the superior performance of the proposed adversarial augmentation approach over baselines across three state-of-the-art action recognition models - TSM, Video Swin Transformer, and Uniformer. The presented work provides critical insight into model robustness to distribution shifts and presents effective techniques to enhance video action recognition performance in a real-world deployment.
Is Scaling Learned Optimizers Worth It? Evaluating The Value of VeLO's 4000 TPU Months
Oct 27, 2023We analyze VeLO (versatile learned optimizer), the largest scale attempt to train a general purpose "foundational" optimizer to date. VeLO was trained on thousands of machine learning tasks using over 4000 TPU months with the goal of producing an optimizer capable of generalizing to new problems while being hyperparameter free, and outperforming industry standards such as Adam. We independently evaluate VeLO on the MLCommons optimizer benchmark suite. We find that, contrary to initial claims: (1) VeLO has a critical hyperparameter that needs problem-specific tuning, (2) VeLO does not necessarily outperform competitors in quality of solution found, and (3) VeLO is not faster than competing optimizers at reducing the training loss. These observations call into question VeLO's generality and the value of the investment in training it.
Development of a Deep Learning Method to Identify Acute Ischemic Stroke Lesions on Brain CT
Sep 29, 2023



Computed Tomography (CT) is commonly used to image acute ischemic stroke (AIS) patients, but its interpretation by radiologists is time-consuming and subject to inter-observer variability. Deep learning (DL) techniques can provide automated CT brain scan assessment, but usually require annotated images. Aiming to develop a DL method for AIS using labelled but not annotated CT brain scans from patients with AIS, we designed a convolutional neural network-based DL algorithm using routinely-collected CT brain scans from the Third International Stroke Trial (IST-3), which were not acquired using strict research protocols. The DL model aimed to detect AIS lesions and classify the side of the brain affected. We explored the impact of AIS lesion features, background brain appearances, and timing on DL performance. From 5772 unique CT scans of 2347 AIS patients (median age 82), 54% had visible AIS lesions according to expert labelling. Our best-performing DL method achieved 72% accuracy for lesion presence and side. Lesions that were larger (80% accuracy) or multiple (87% accuracy for two lesions, 100% for three or more), were better detected. Follow-up scans had 76% accuracy, while baseline scans 67% accuracy. Chronic brain conditions reduced accuracy, particularly non-stroke lesions and old stroke lesions (32% and 31% error rates respectively). DL methods can be designed for AIS lesion detection on CT using the vast quantities of routinely-collected CT brain scan data. Ultimately, this should lead to more robust and widely-applicable methods.
Challenges of building medical image datasets for development of deep learning software in stroke
Sep 26, 2023



Despite the large amount of brain CT data generated in clinical practice, the availability of CT datasets for deep learning (DL) research is currently limited. Furthermore, the data can be insufficiently or improperly prepared for machine learning and thus lead to spurious and irreproducible analyses. This lack of access to comprehensive and diverse datasets poses a significant challenge for the development of DL algorithms. In this work, we propose a complete semi-automatic pipeline to address the challenges of preparing a clinical brain CT dataset for DL analysis and describe the process of standardising this heterogeneous dataset. Challenges include handling image sets with different orientations (axial, sagittal, coronal), different image types (to view soft tissues or bones) and dimensions, and removing redundant background. The final pipeline was able to process 5,868/10,659 (45%) CT image datasets. Reasons for rejection include non-axial data (n=1,920), bone reformats (n=687), separated skull base/vault images (n=1,226), and registration failures (n=465). Further format adjustments, including image cropping, resizing and scaling are also needed for DL processing. Of the axial scans that were not localisers, bone reformats or split brains, 5,868/6,333 (93%) were accepted, while the remaining 465 failed the registration process. Appropriate preparation of medical imaging datasets for DL is a costly and time-intensive process.
ACAT: Adversarial Counterfactual Attention for Classification and Detection in Medical Imaging
Mar 27, 2023



In some medical imaging tasks and other settings where only small parts of the image are informative for the classification task, traditional CNNs can sometimes struggle to generalise. Manually annotated Regions of Interest (ROI) are sometimes used to isolate the most informative parts of the image. However, these are expensive to collect and may vary significantly across annotators. To overcome these issues, we propose a framework that employs saliency maps to obtain soft spatial attention masks that modulate the image features at different scales. We refer to our method as Adversarial Counterfactual Attention (ACAT). ACAT increases the baseline classification accuracy of lesions in brain CT scans from 71.39% to 72.55% and of COVID-19 related findings in lung CT scans from 67.71% to 70.84% and exceeds the performance of competing methods. We investigate the best way to generate the saliency maps employed in our architecture and propose a way to obtain them from adversarially generated counterfactual images. They are able to isolate the area of interest in brain and lung CT scans without using any manual annotations. In the task of localising the lesion location out of 6 possible regions, they obtain a score of 65.05% on brain CT scans, improving the score of 61.29% obtained with the best competing method.
Contrastive Meta-Learning for Partially Observable Few-Shot Learning
Jan 30, 2023



Many contrastive and meta-learning approaches learn representations by identifying common features in multiple views. However, the formalism for these approaches generally assumes features to be shared across views to be captured coherently. We consider the problem of learning a unified representation from partial observations, where useful features may be present in only some of the views. We approach this through a probabilistic formalism enabling views to map to representations with different levels of uncertainty in different components; these views can then be integrated with one another through marginalisation over that uncertainty. Our approach, Partial Observation Experts Modelling (POEM), then enables us to meta-learn consistent representations from partial observations. We evaluate our approach on an adaptation of a comprehensive few-shot learning benchmark, Meta-Dataset, and demonstrate the benefits of POEM over other meta-learning methods at representation learning from partial observations. We further demonstrate the utility of POEM by meta-learning to represent an environment from partial views observed by an agent exploring the environment.
Defining Benchmarks for Continual Few-Shot Learning
Apr 15, 2020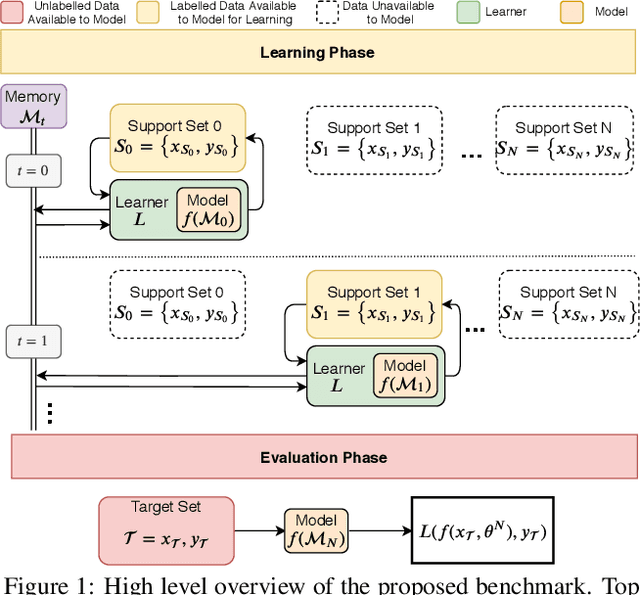
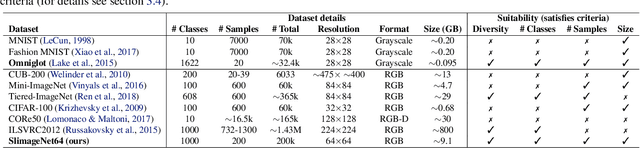
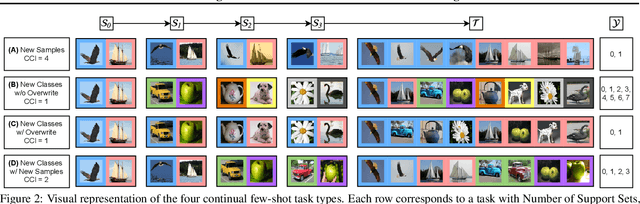
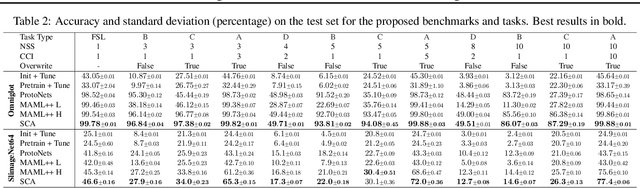
Both few-shot and continual learning have seen substantial progress in the last years due to the introduction of proper benchmarks. That being said, the field has still to frame a suite of benchmarks for the highly desirable setting of continual few-shot learning, where the learner is presented a number of few-shot tasks, one after the other, and then asked to perform well on a validation set stemming from all previously seen tasks. Continual few-shot learning has a small computational footprint and is thus an excellent setting for efficient investigation and experimentation. In this paper we first define a theoretical framework for continual few-shot learning, taking into account recent literature, then we propose a range of flexible benchmarks that unify the evaluation criteria and allows exploring the problem from multiple perspectives. As part of the benchmark, we introduce a compact variant of ImageNet, called SlimageNet64, which retains all original 1000 classes but only contains 200 instances of each one (a total of 200K data-points) downscaled to 64 x 64 pixels. We provide baselines for the proposed benchmarks using a number of popular few-shot learning algorithms, as a result, exposing previously unknown strengths and weaknesses of those algorithms in continual and data-limited settings.
Meta-Learning in Neural Networks: A Survey
Apr 11, 2020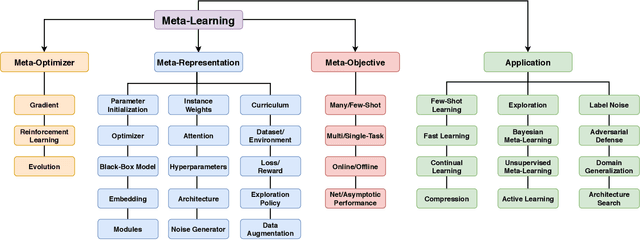
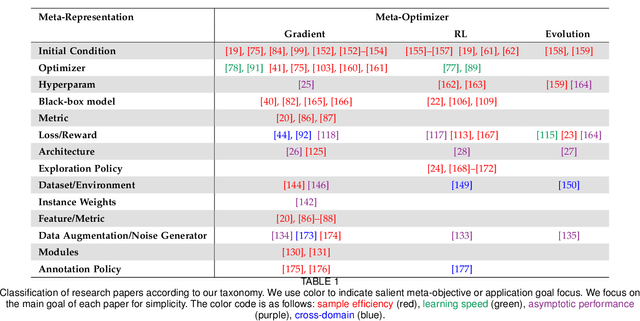
The field of meta-learning, or learning-to-learn, has seen a dramatic rise in interest in recent years. Contrary to conventional approaches to AI where a given task is solved from scratch using a fixed learning algorithm, meta-learning aims to improve the learning algorithm itself, given the experience of multiple learning episodes. This paradigm provides an opportunity to tackle many of the conventional challenges of deep learning, including data and computation bottlenecks, as well as the fundamental issue of generalization. In this survey we describe the contemporary meta-learning landscape. We first discuss definitions of meta-learning and position it with respect to related fields, such as transfer learning, multi-task learning, and hyperparameter optimization. We then propose a new taxonomy that provides a more comprehensive breakdown of the space of meta-learning methods today. We survey promising applications and successes of meta-learning including few-shot learning, reinforcement learning and architecture search. Finally, we discuss outstanding challenges and promising areas for future research.
Learning to learn via Self-Critique
May 31, 2019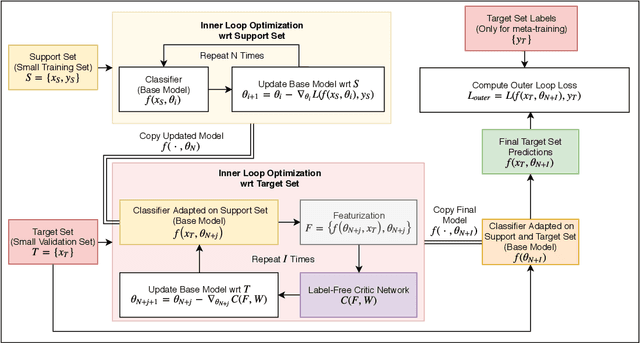
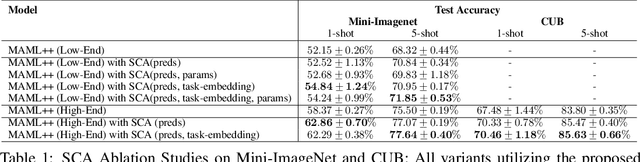
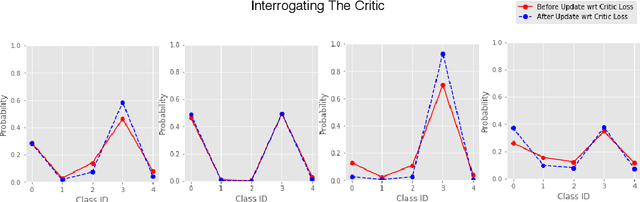
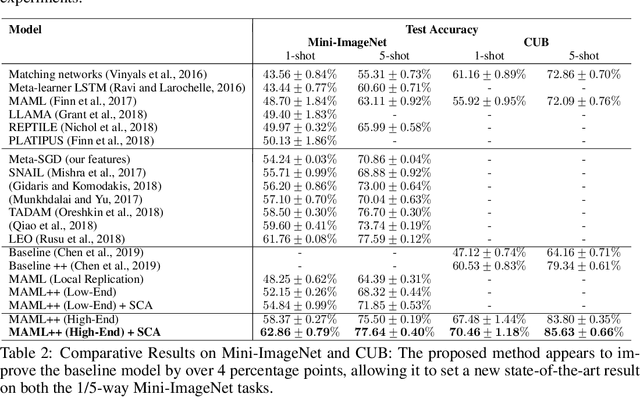
In few-shot learning, a machine learning system learns from a small set of labelled examples relating to a specific task, such that it can generalize to new examples of the same task. Given the limited availability of labelled examples in such tasks ,we wish to make use of all the information we can. Usually a model learns task-specific information from a small training-set (support-set) to predict on an unlabelled validation set (target-set). The target-set contains additional task-specific information which is not utilized by existing few-shot learning methods. Making use of the target-set examples via transductive learning requires approaches beyond the current methods; at inference time, the target-set contains only unlabelled input data-points, and so discriminative learning cannot be used. In this paper, we propose a framework called Self-Critique and Adapt or SCA, which learns to learn a label-free loss function, parameterized as a neural network. A base-model learns on a support-set using existing methods (e.g. stochastic gradient descent combined with the cross-entropy loss), and then is updated for the incoming target-task using the learnt loss function. This label-free loss function is itself optimized such that the learnt model achieves higher generalization performance. Experiments demonstrate that SCA offers substantially reduced error-rates compared to baselines which only adapt on the support-set, and results in state of the art benchmark performance on Mini-ImageNet and Caltech-UCSD Birds 200.