 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Person Re-Identification via Sub-space Consistency Regularization
Jul 13, 2022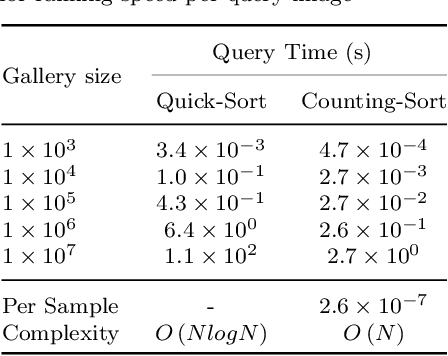
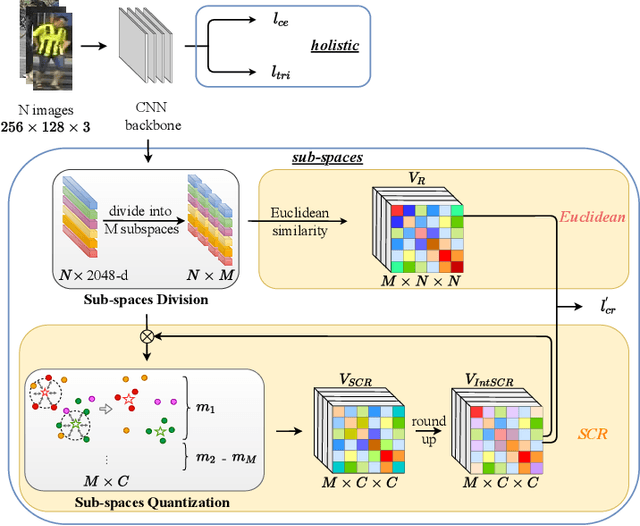
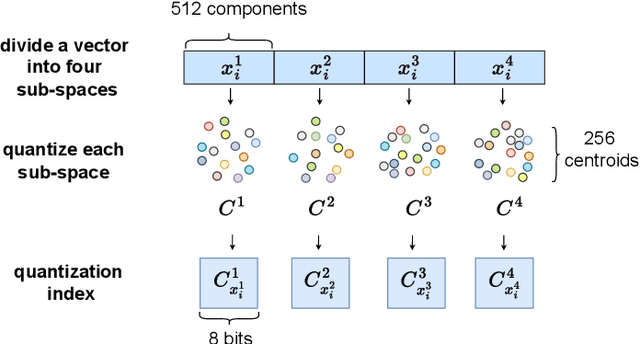
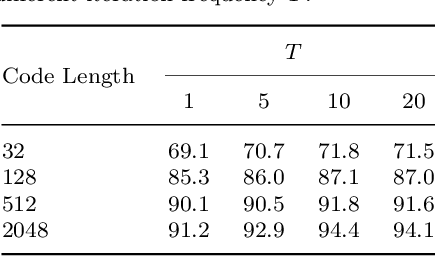
Person Re-Identification (ReID) matches pedestrians across disjoint cameras. Existing ReID methods adopting real-value feature descriptors have achieved high accuracy, but they are low in efficiency due to the slow Euclidean distance computation as well as complex quick-sort algorithms. Recently, some works propose to yield binary encoded person descriptors which instead only require fast Hamming distance computation and simple counting-sort algorithms. However, the performances of such binary encoded descriptors, especially with short code (e.g., 32 and 64 bits), are hardly satisfactory given the sparse binary space. To strike a balance between the model accuracy and efficiency, we propose a novel Sub-space Consistency Regularization (SCR) algorithm that can speed up the ReID procedure by $0.25$ times than real-value features under the same dimensions whilst maintaining a competitive accuracy, especially under short codes. SCR transforms real-value features vector (e.g., 2048 float32) with short binary codes (e.g., 64 bits) by first dividing real-value features vector into $M$ sub-spaces, each with $C$ clustered centroids. Thus the distance between two samples can be expressed as the summation of the respective distance to the centroids, which can be sped up by offline calculation and maintained via a look-up table. On the other side, these real-value centroids help to achieve significantly higher accuracy than using binary code. Lastly, we convert the distance look-up table to be integer and apply the counting-sort algorithm to speed up the ranking stage. We also propose a novel consistency regularization with an iterative framework. Experimental results on Market-1501 and DukeMTMC-reID show promising and exciting results. Under short code, our proposed SCR enjoys Real-value-level accuracy and Hashing-level speed.
Video Activity Localisation with Uncertainties in Temporal Boundary
Jun 26, 2022

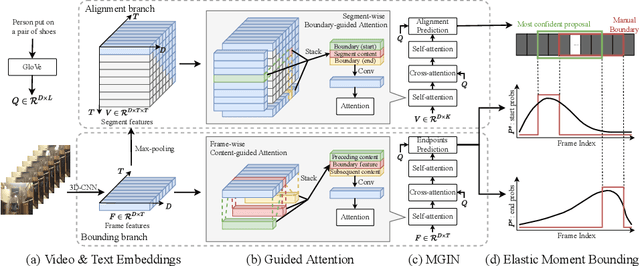
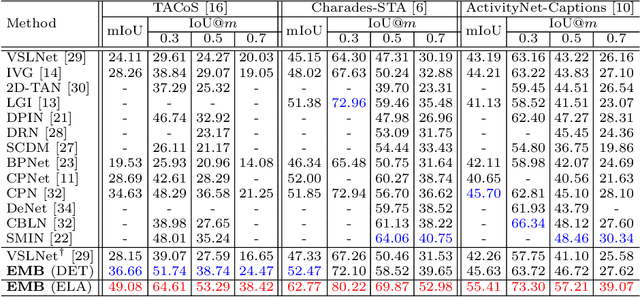
Current methods for video activity localisation over time assume implicitly that activity temporal boundaries labelled for model training are determined and precise. However, in unscripted natural videos, different activities mostly transit smoothly, so that it is intrinsically ambiguous to determine in labelling precisely when an activity starts and ends over time. Such uncertainties in temporal labelling are currently ignored in model training, resulting in learning mis-matched video-text correlation with poor generalisation in test. In this work, we solve this problem by introducing Elastic Moment Bounding (EMB) to accommodate flexible and adaptive activity temporal boundaries towards modelling universally interpretable video-text correlation with tolerance to underlying temporal uncertainties in pre-fixed annotations. Specifically, we construct elastic boundaries adaptively by mining and discovering frame-wise temporal endpoints that can maximise the alignment between video segments and query sentences. To enable both more robust matching (segment content attention) and more accurate localisation (segment elastic boundaries), we optimise the selection of frame-wise endpoints subject to segment-wise contents by a novel Guided Attention mechanism. Extensive experiments on three video activity localisation benchmarks demonstrate compellingly the EMB's advantages over existing methods without modelling uncertainty.
Learning Unbiased Transferability for Domain Adaptation by Uncertainty Modeling
Jun 02, 2022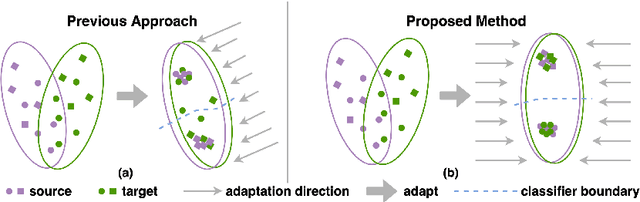
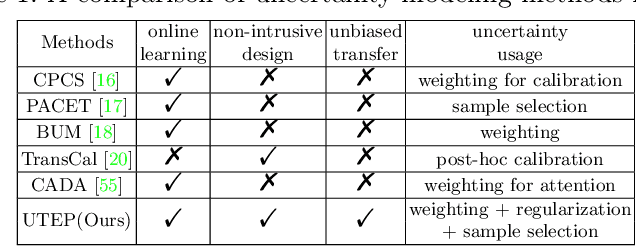
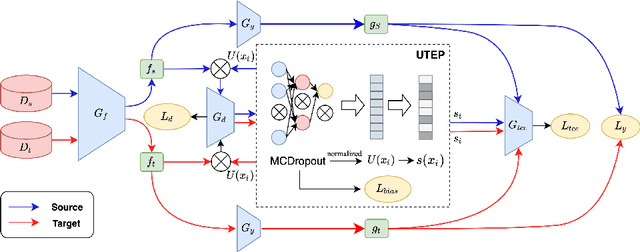
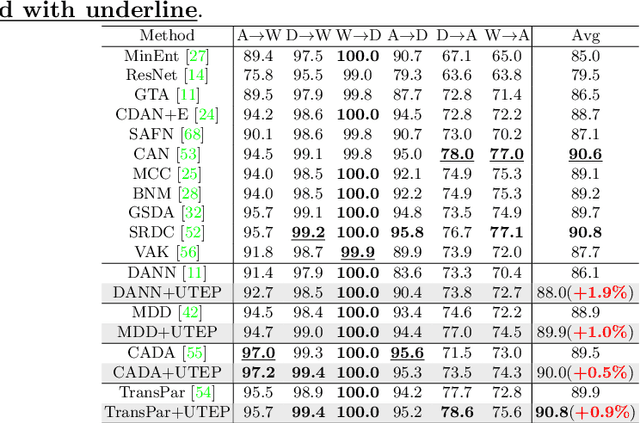
Domain adaptation (DA) aims to transfer knowledge learned from a labeled source domain to an unlabeled or a less labeled but related target domain. Ideally, the source and target distributions should be aligned to each other equally to achieve unbiased knowledge transfer. However, due to the significant imbalance between the amount of annotated data in the source and target domains, usually only the target distribution is aligned to the source domain, leading to adapting unnecessary source specific knowledge to the target domain, i.e., biased domain adaptation. To resolve this problem, in this work, we delve into the transferability estimation problem in domain adaptation and propose a non-intrusive Unbiased Transferability Estimation Plug-in (UTEP) by modeling the uncertainty of a discriminator in adversarial-based DA methods to optimize unbiased transfer. We theoretically analyze the effectiveness of the proposed approach to unbiased transferability learning in DA. Furthermore, to alleviate the impact of imbalanced annotated data, we utilize the estimated uncertainty for pseudo label selection of unlabeled samples in the target domain, which helps achieve better marginal and conditional distribution alignments between domains. Extensive experimental results on a high variety of DA benchmark datasets show that the proposed approach can be readily incorporated into various adversarial-based DA methods, achieving state-of-the-art performance.
Feature-Distribution Perturbation and Calibration for Generalized Person ReID
May 23, 2022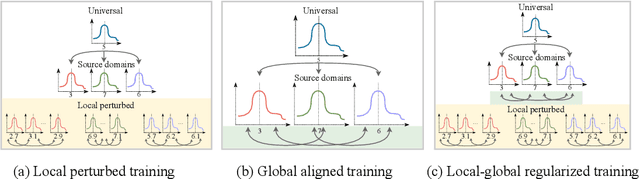
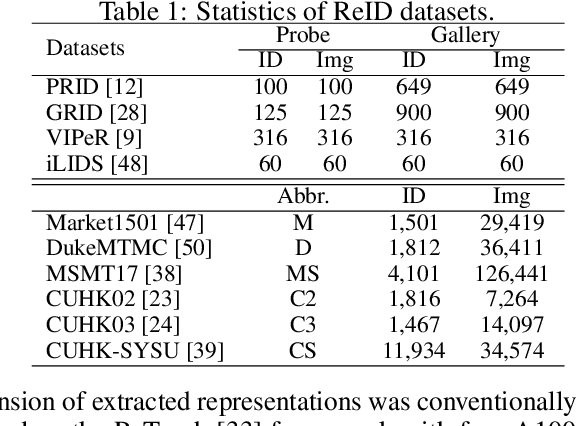
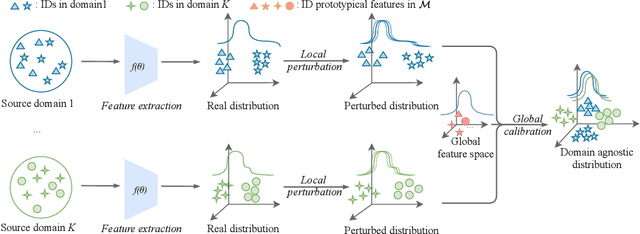
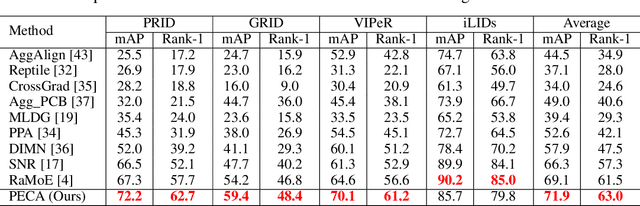
Person Re-identification (ReID) has been advanced remarkably over the last 10 years along with the rapid development of deep learning for visual recognition. However, the i.i.d. (independent and identically distributed) assumption commonly held in most deep learning models is somewhat non-applicable to ReID considering its objective to identify images of the same pedestrian across cameras at different locations often of variable and independent domain characteristics that are also subject to view-biased data distribution. In this work, we propose a Feature-Distribution Perturbation and Calibration (PECA) method to derive generic feature representations for person ReID, which is not only discriminative across cameras but also agnostic and deployable to arbitrary unseen target domains. Specifically, we perform per-domain feature-distribution perturbation to refrain the model from overfitting to the domain-biased distribution of each source (seen) domain by enforcing feature invariance to distribution shifts caused by perturbation. Furthermore, we design a global calibration mechanism to align feature distributions across all the source domains to improve the model generalization capacity by eliminating domain bias. These local perturbation and global calibration are conducted simultaneously, which share the same principle to avoid models overfitting by regularization respectively on the perturbed and the original distributions. Extensive experiments were conducted on eight person ReID datasets and the proposed PECA model outperformed the state-of-the-art competitors by significant margins.
A Framework of Meta Functional Learning for Regularising Knowledge Transfer
Mar 28, 2022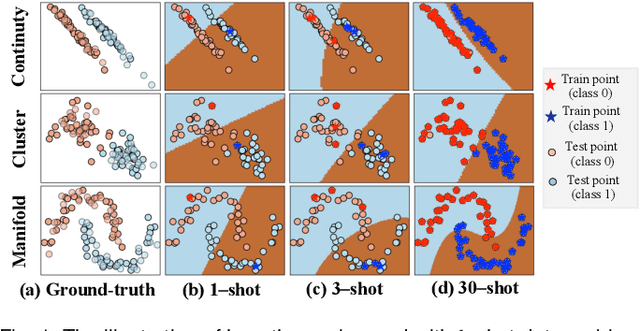

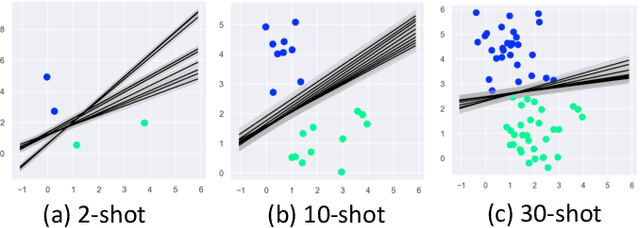
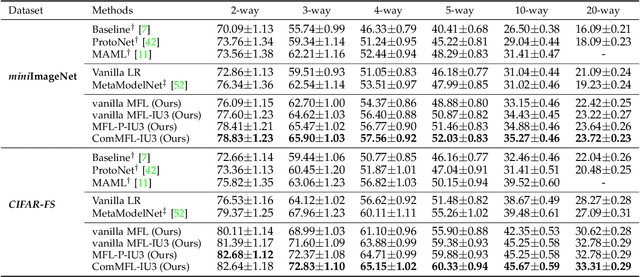
Machine learning classifiers' capability is largely dependent on the scale of available training data and limited by the model overfitting in data-scarce learning tasks. To address this problem, this work proposes a novel framework of Meta Functional Learning (MFL) by meta-learning a generalisable functional model from data-rich tasks whilst simultaneously regularising knowledge transfer to data-scarce tasks. The MFL computes meta-knowledge on functional regularisation generalisable to different learning tasks by which functional training on limited labelled data promotes more discriminative functions to be learned. Based on this framework, we formulate three variants of MFL: MFL with Prototypes (MFL-P) which learns a functional by auxiliary prototypes, Composite MFL (ComMFL) that transfers knowledge from both functional space and representational space, and MFL with Iterative Updates (MFL-IU) which improves knowledge transfer regularisation from MFL by progressively learning the functional regularisation in knowledge transfer. Moreover, we generalise these variants for knowledge transfer regularisation from binary classifiers to multi-class classifiers. Extensive experiments on two few-shot learning scenarios, Few-Shot Learning (FSL) and Cross-Domain Few-Shot Learning (CD-FSL), show that meta functional learning for knowledge transfer regularisation can improve FSL classifiers.
Ranking Distance Calibration for Cross-Domain Few-Shot Learning
Dec 01, 2021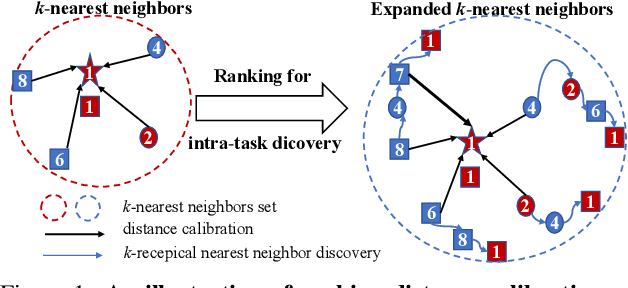
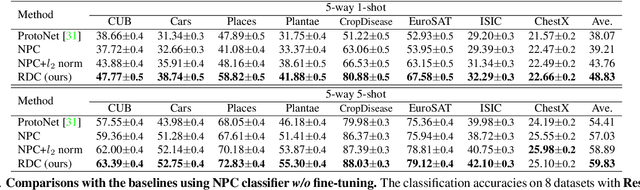
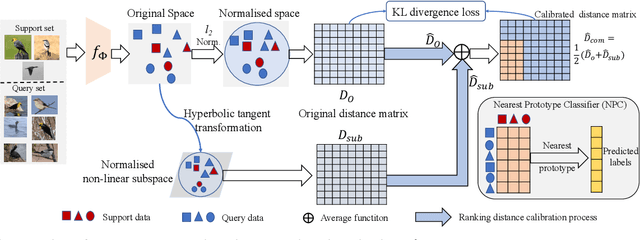
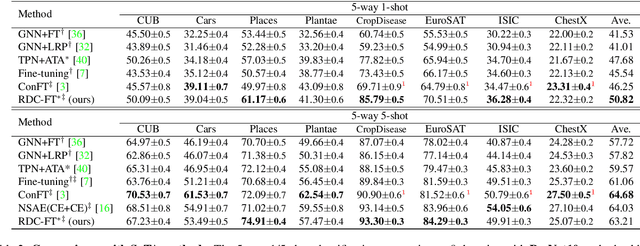
Recent progress in few-shot learning promotes a more realistic cross-domain setting, where the source and target datasets are from different domains. Due to the domain gap and disjoint label spaces between source and target datasets, their shared knowledge is extremely limited. This encourages us to explore more information in the target domain rather than to overly elaborate training strategies on the source domain as in many existing methods. Hence, we start from a generic representation pre-trained by a cross-entropy loss and a conventional distance-based classifier, along with an image retrieval view, to employ a re-ranking process for calibrating a target distance matrix by discovering the reciprocal k-nearest neighbours within the task. Assuming the pre-trained representation is biased towards the source, we construct a non-linear subspace to minimise task-irrelevant features therewithin while keep more transferrable discriminative information by a hyperbolic tangent transformation. The calibrated distance in this target-aware non-linear subspace is complementary to that in the pre-trained representation. To impose such distance calibration information onto the pre-trained representation, a Kullback-Leibler divergence loss is employed to gradually guide the model towards the calibrated distance-based distribution. Extensive evaluations on eight target domains show that this target ranking calibration process can improve conventional distance-based classifiers in few-shot learning.
Local-Global Associative Frame Assemble in Video Re-ID
Oct 22, 2021
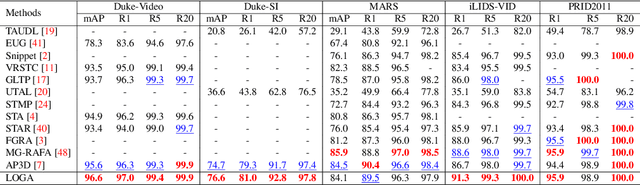
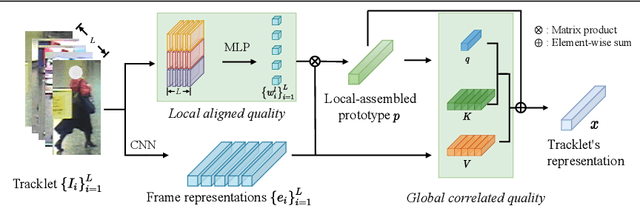

Noisy and unrepresentative frames in automatically generated object bounding boxes from video sequences cause significant challenges in learning discriminative representations in video re-identification (Re-ID). Most existing methods tackle this problem by assessing the importance of video frames according to either their local part alignments or global appearance correlations separately. However, given the diverse and unknown sources of noise which usually co-exist in captured video data, existing methods have not been effective satisfactorily. In this work, we explore jointly both local alignments and global correlations with further consideration of their mutual promotion/reinforcement so to better assemble complementary discriminative Re-ID information within all the relevant frames in video tracklets. Specifically, we concurrently optimise a local aligned quality (LAQ) module that distinguishes the quality of each frame based on local alignments, and a global correlated quality (GCQ) module that estimates global appearance correlations. With the help of a local-assembled global appearance prototype, we associate LAQ and GCQ to exploit their mutual complement. Extensive experiments demonstrate the superiority of the proposed model against state-of-the-art methods on five Re-ID benchmarks, including MARS, Duke-Video, Duke-SI, iLIDS-VID, and PRID2011.
Decentralised Person Re-Identification with Selective Knowledge Aggregation
Oct 21, 2021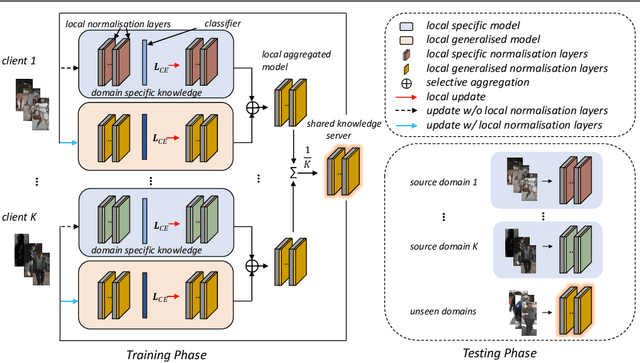
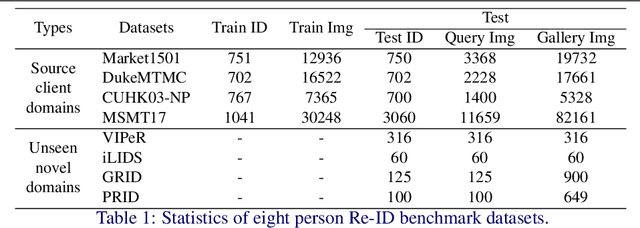
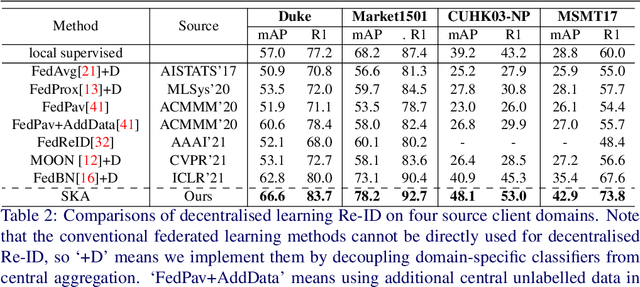
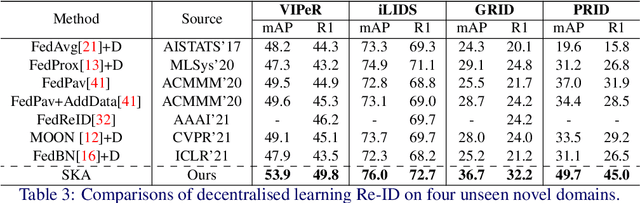
Existing person re-identification (Re-ID) methods mostly follow a centralised learning paradigm which shares all training data to a collection for model learning. This paradigm is limited when data from different sources cannot be shared due to privacy concerns. To resolve this problem, two recent works have introduced decentralised (federated) Re-ID learning for constructing a globally generalised model (server)without any direct access to local training data nor shared data across different source domains (clients). However, these methods are poor on how to adapt the generalised model to maximise its performance on individual client domain Re-ID tasks having different Re-ID label spaces, due to a lack of understanding of data heterogeneity across domains. We call this poor 'model personalisation'. In this work, we present a new Selective Knowledge Aggregation approach to decentralised person Re-ID to optimise the trade-off between model personalisation and generalisation. Specifically, we incorporate attentive normalisation into the normalisation layers in a deep ReID model and propose to learn local normalisation layers specific to each domain, which are decoupled from the global model aggregation in federated Re-ID learning. This helps to preserve model personalisation knowledge on each local client domain and learn instance-specific information. Further, we introduce a dual local normalisation mechanism to learn generalised normalisation layers in each local model, which are then transmitted to the global model for central aggregation. This facilitates selective knowledge aggregation on the server to construct a global generalised model for out-of-the-box deployment on unseen novel domains. Extensive experiments on eight person Re-ID datasets show that the proposed approach to decentralised Re-ID significantly outperforms the state-of-the-art decentralised methods.
Cross-Sentence Temporal and Semantic Relations in Video Activity Localisation
Aug 17, 2021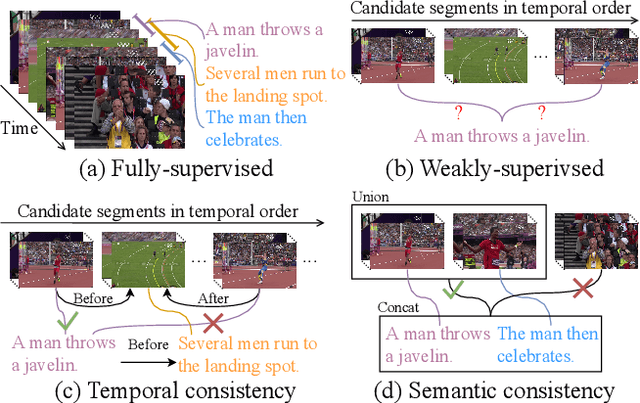
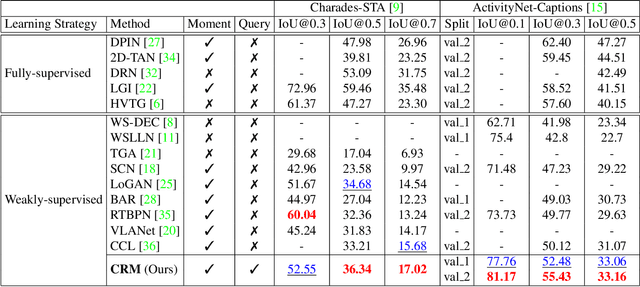
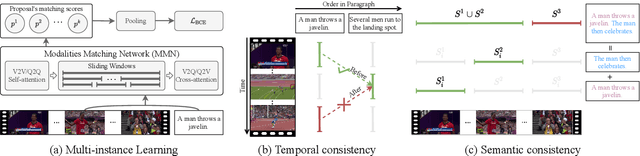
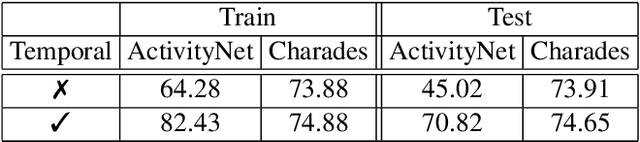
Video activity localisation has recently attained increasing attention due to its practical values in automatically localising the most salient visual segments corresponding to their language descriptions (sentences) from untrimmed and unstructured videos. For supervised model training, a temporal annotation of both the start and end time index of each video segment for a sentence (a video moment) must be given. This is not only very expensive but also sensitive to ambiguity and subjective annotation bias, a much harder task than image labelling. In this work, we develop a more accurate weakly-supervised solution by introducing Cross-Sentence Relations Mining (CRM) in video moment proposal generation and matching when only a paragraph description of activities without per-sentence temporal annotation is available. Specifically, we explore two cross-sentence relational constraints: (1) Temporal ordering and (2) semantic consistency among sentences in a paragraph description of video activities. Existing weakly-supervised techniques only consider within-sentence video segment correlations in training without considering cross-sentence paragraph context. This can mislead due to ambiguous expressions of individual sentences with visually indiscriminate video moment proposals in isolation. Experiments on two publicly available activity localisation datasets show the advantages of our approach over the state-of-the-art weakly supervised methods, especially so when the video activity descriptions become more complex.
Deep Clustering by Semantic Contrastive Learning
Mar 03, 2021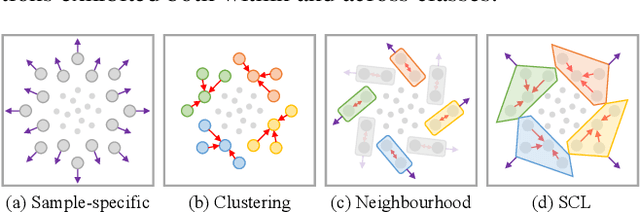
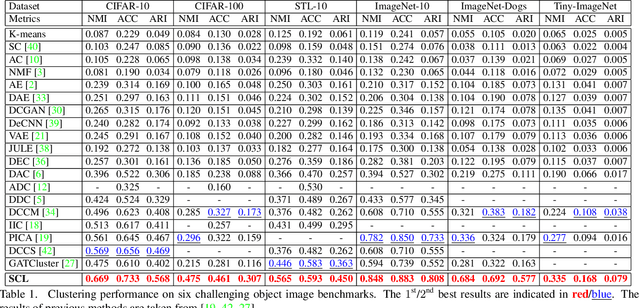
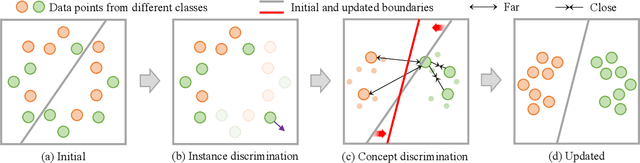
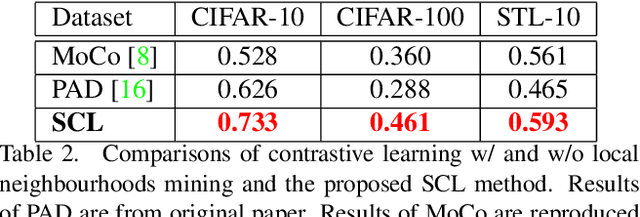
Whilst contrastive learning has achieved remarkable success in self-supervised representation learning, its potential for deep clustering remains unknown. This is due to its fundamental limitation that the instance discrimination strategy it takes is not class sensitive and hence unable to reason about the underlying decision boundaries between semantic concepts or classes. In this work, we solve this problem by introducing a novel variant called Semantic Contrastive Learning (SCL). It explores the characteristics of both conventional contrastive learning and deep clustering by imposing distance-based cluster structures on unlabelled training data and also introducing a discriminative contrastive loss formulation. For explicitly modelling class boundaries on-the-fly, we further formulate a clustering consistency condition on the two different predictions given by visual similarities and semantic decision boundaries. By advancing implicit representation learning towards explicit understandings of visual semantics, SCL can amplify jointly the strengths of contrastive learning and deep clustering in a unified approach. Extensive experiments show that the proposed model outperforms the state-of-the-art deep clustering methods on six challenging object recognition benchmarks, especially on finer-grained and larger datasets.