 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-based Person Re-identification without Bells and Whistles
May 22, 2021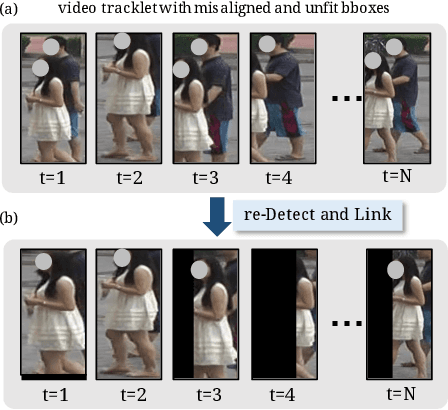
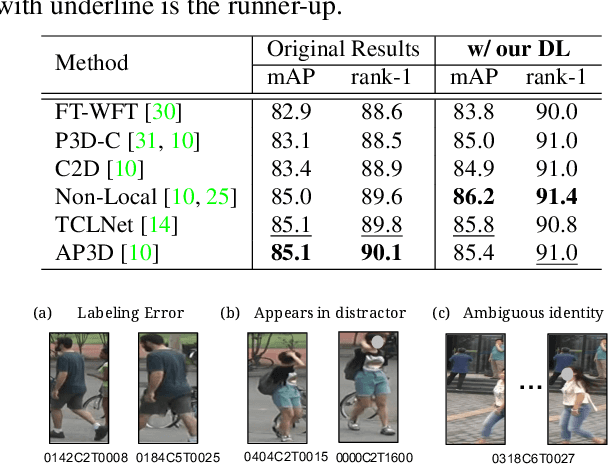
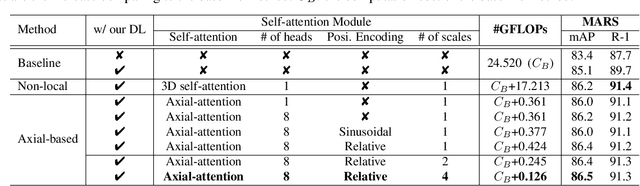
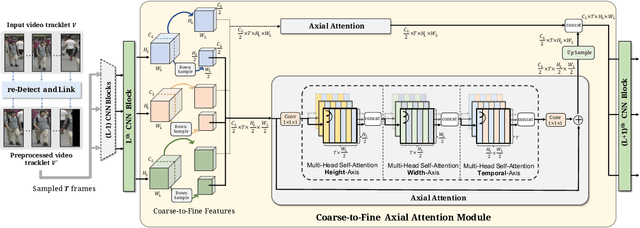
Video-based person re-identification (Re-ID) aims at matching the video tracklets with cropped video frames for identifying the pedestrians under different cameras. However, there exists severe spatial and temporal misalignment for those cropped tracklets due to the imperfect detection and tracking results generated with obsolete methods. To address this issue, we present a simple re-Detect and Link (DL) module which can effectively reduce those unexpected noise through applying the deep learning-based detection and tracking on the cropped tracklets. Furthermore, we introduce an improved model called Coarse-to-Fine Axial-Attention Network (CF-AAN). Based on the typical Non-local Network, we replace the non-local module with three 1-D position-sensitive axial attentions, in addition to our proposed coarse-to-fine structure. With the developed CF-AAN, compared to the original non-local operation, we can not only significantly reduce the computation cost but also obtain the state-of-the-art performance (91.3% in rank-1 and 86.5% in mAP) on the large-scale MARS dataset. Meanwhile, by simply adopting our DL module for data alignment, to our surprise, several baseline models can achieve better or comparable results with the current state-of-the-arts. Besides, we discover the errors not only for the identity labels of tracklets but also for the evaluation protocol for the test data of MARS. We hope that our work can help the community for the further development of invariant representation without the hassle of the spatial and temporal alignment and dataset noise. The code, corrected labels, evaluation protocol, and the aligned data will be available at https://github.com/jackie840129/CF-AAN.
How to Exploit the Transferability of Learned Image Compression to Conventional Codecs
Dec 03, 2020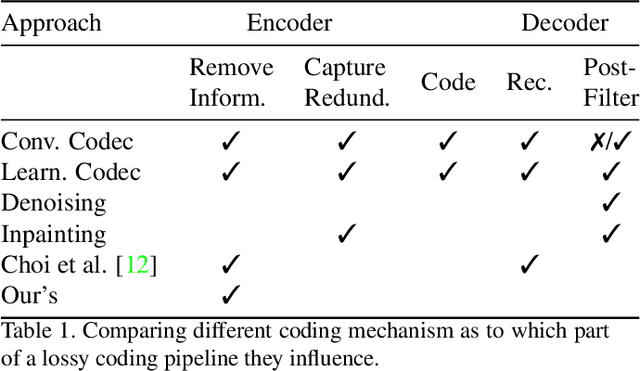
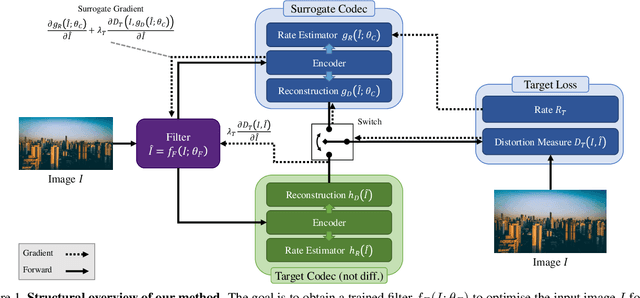
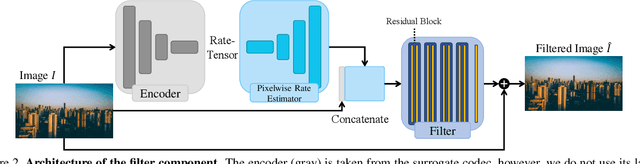

Lossy image compression is often limited by the simplicity of the chosen loss measure. Recent research suggests that generative adversarial networks have the ability to overcome this limitation and serve as a multi-modal loss, especially for textures. Together with learned image compression, these two techniques can be used to great effect when relaxing the commonly employed tight measures of distortion. However, convolutional neural network based algorithms have a large computational footprint. Ideally, an existing conventional codec should stay in place, which would ensure faster adoption and adhering to a balanced computational envelope. As a possible avenue to this goal, in this work, we propose and investigate how learned image coding can be used as a surrogate to optimize an image for encoding. The image is altered by a learned filter to optimise for a different performance measure or a particular task. Extending this idea with a generative adversarial network, we show how entire textures are replaced by ones that are less costly to encode but preserve sense of detail. Our approach can remodel a conventional codec to adjust for the MS-SSIM distortion with over 20% rate improvement without any decoding overhead. On task-aware image compression, we perform favourably against a similar but codec-specific approach.
Viewpoint-Aware Channel-Wise Attentive Network for Vehicle Re-Identification
Oct 12, 2020
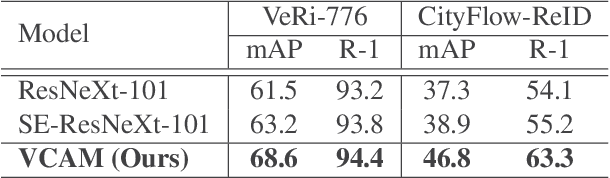
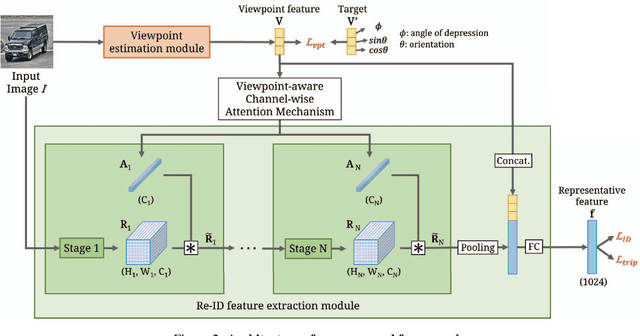
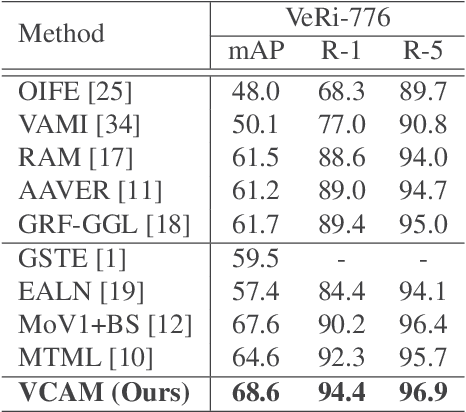
Vehicle re-identification (re-ID) matches images of the same vehicle across different cameras. It is fundamentally challenging because the dramatically different appearance caused by different viewpoints would make the framework fail to match two vehicles of the same identity. Most existing works solved the problem by extracting viewpoint-aware feature via spatial attention mechanism, which, yet, usually suffers from noisy generated attention map or otherwise requires expensive keypoint labels to improve the quality. In this work, we propose Viewpoint-aware Channel-wise Attention Mechanism (VCAM) by observing the attention mechanism from a different aspect. Our VCAM enables the feature learning framework channel-wisely reweighing the importance of each feature maps according to the "viewpoint" of input vehicle. Extensive experiments validate the effectiveness of the proposed method and show that we perform favorably against state-of-the-arts methods on the public VeRi-776 dataset and obtain promising results on the 2020 AI City Challenge. We also conduct other experiments to demonstrate the interpretability of how our VCAM practically assists the learning framework.
Joint Pruning & Quantization for Extremely Sparse Neural Networks
Oct 05, 2020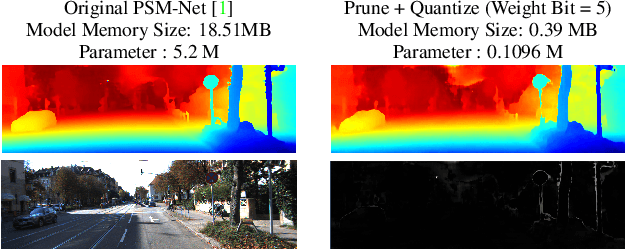
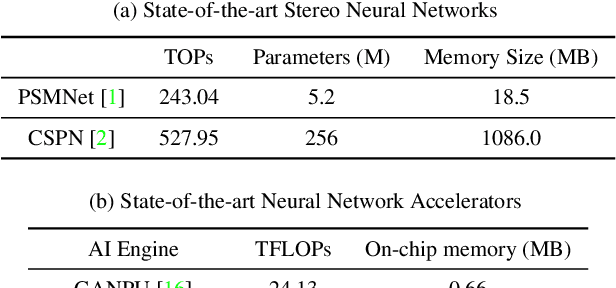
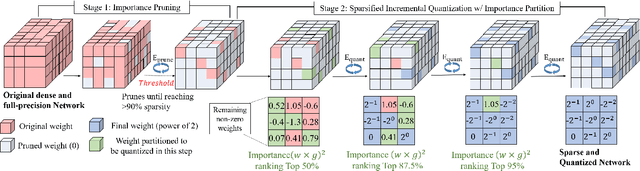
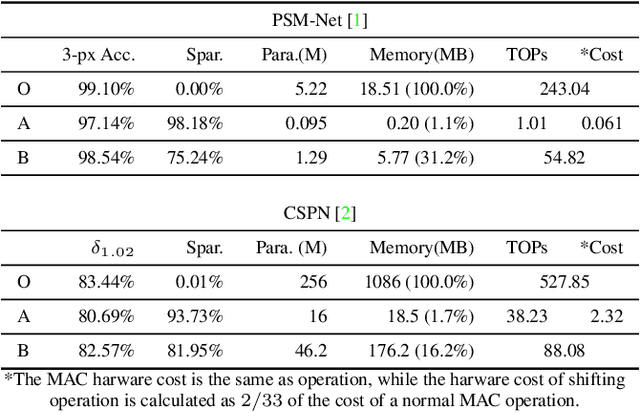
We investigate pruning and quantization for deep neural networks. Our goal is to achieve extremely high sparsity for quantized networks to enable implementation on low cost and low power accelerator hardware. In a practical scenario, there are particularly many applications for dense prediction tasks, hence we choose stereo depth estimation as target. We propose a two stage pruning and quantization pipeline and introduce a Taylor Score alongside a new fine-tuning mode to achieve extreme sparsity without sacrificing performance. Our evaluation does not only show that pruning and quantization should be investigated jointly, but also shows that almost 99% of memory demand can be cut while hardware costs can be reduced up to 99.9%. In addition, to compare with other works, we demonstrate that our pruning stage alone beats the state-of-the-art when applied to ResNet on CIFAR10 and ImageNet.
Semantics-Guided Clustering with Deep Progressive Learning for Semi-Supervised Person Re-identification
Oct 02, 2020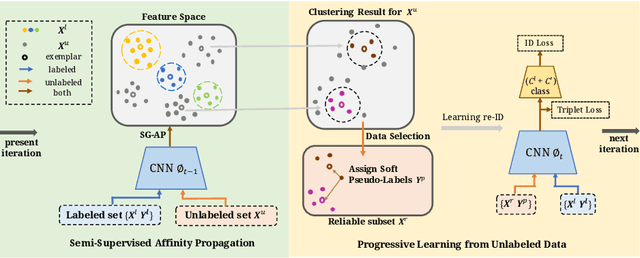
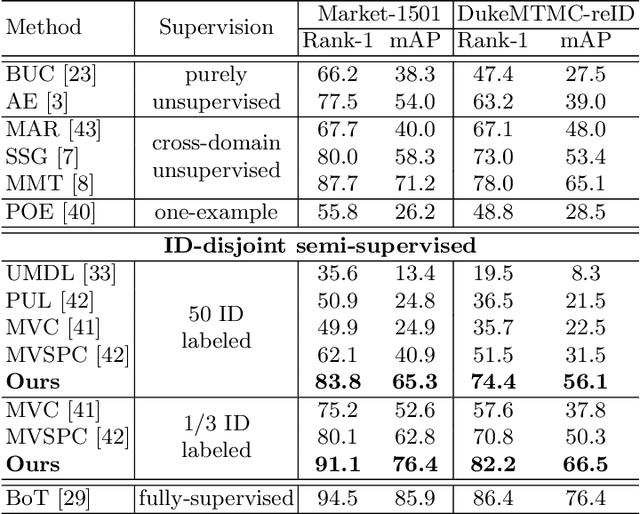
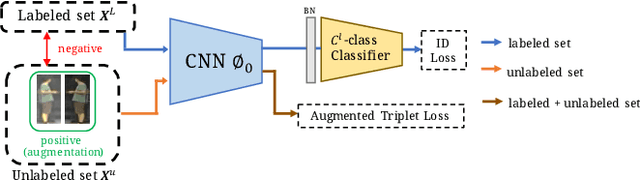
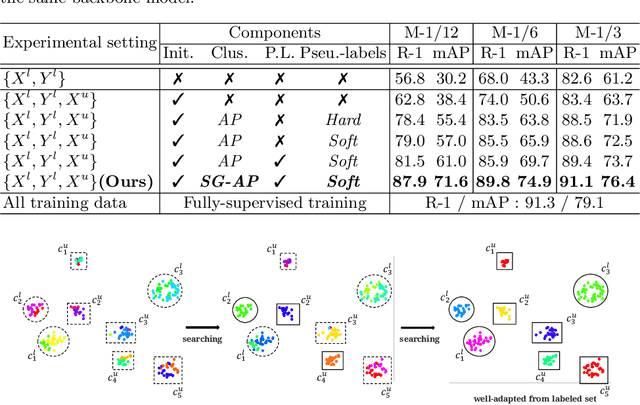
Person re-identification (re-ID) requires one to match images of the same person across camera views. As a more challenging task, semi-supervised re-ID tackles the problem that only a number of identities in training data are fully labeled, while the remaining are unlabeled. Assuming that such labeled and unlabeled training data share disjoint identity labels, we propose a novel framework of Semantics-Guided Clustering with Deep Progressive Learning (SGC-DPL) to jointly exploit the above data. By advancing the proposed Semantics-Guided Affinity Propagation (SG-AP), we are able to assign pseudo-labels to selected unlabeled data in a progressive fashion, under the semantics guidance from the labeled ones. As a result, our approach is able to augment the labeled training data in the semi-supervised setting. Our experiments on two large-scale person re-ID benchmarks demonstrate the superiority of our SGC-DPL over state-of-the-art methods across different degrees of supervision. In extension, the generalization ability of our SGC-DPL is also verified in other tasks like vehicle re-ID or image retrieval with the semi-supervised setting.
GrateTile: Efficient Sparse Tensor Tiling for CNN Processing
Sep 18, 2020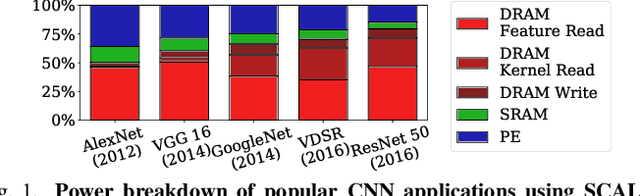
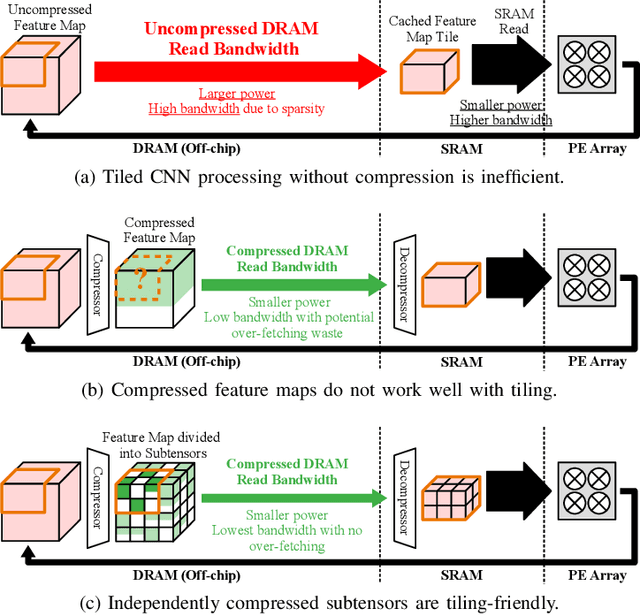
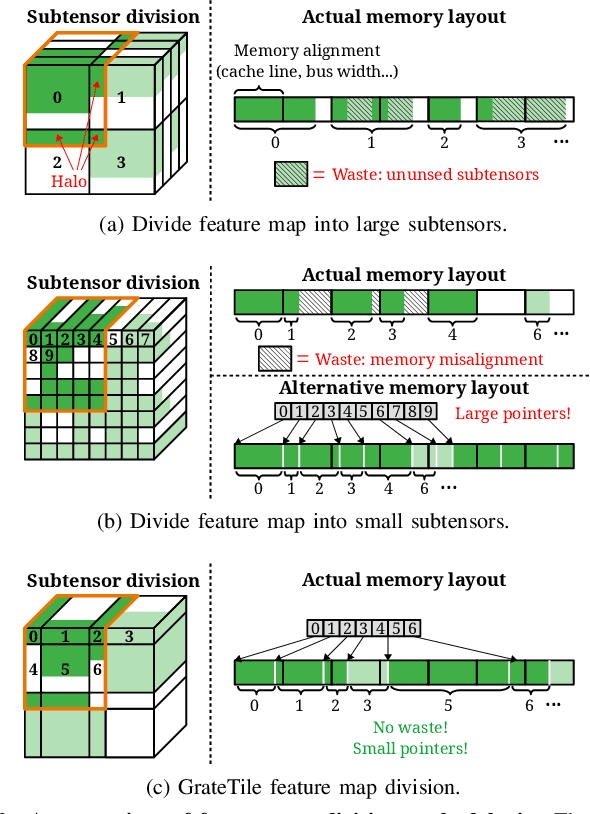
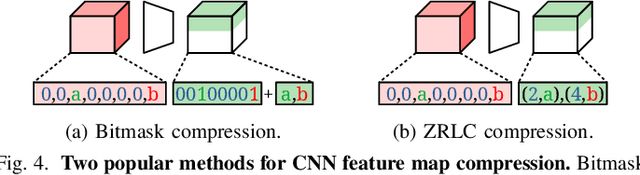
We propose GrateTile, an efficient, hardwarefriendly data storage scheme for sparse CNN feature maps (activations). It divides data into uneven-sized subtensors and, with small indexing overhead, stores them in a compressed yet randomly accessible format. This design enables modern CNN accelerators to fetch and decompressed sub-tensors on-the-fly in a tiled processing manner. GrateTile is suitable for architectures that favor aligned, coalesced data access, and only requires minimal changes to the overall architectural design. We simulate GrateTile with state-of-the-art CNNs and show an average of 55% DRAM bandwidth reduction while using only 0.6% of feature map size for indexing storage.
Orientation-aware Vehicle Re-identification with Semantics-guided Part Attention Network
Aug 26, 2020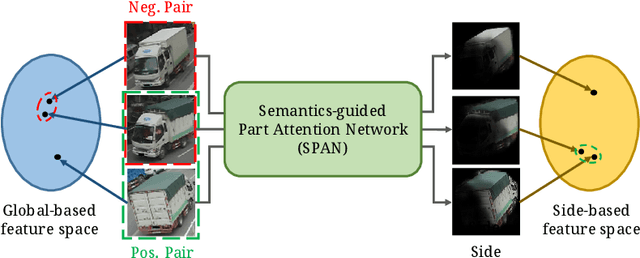


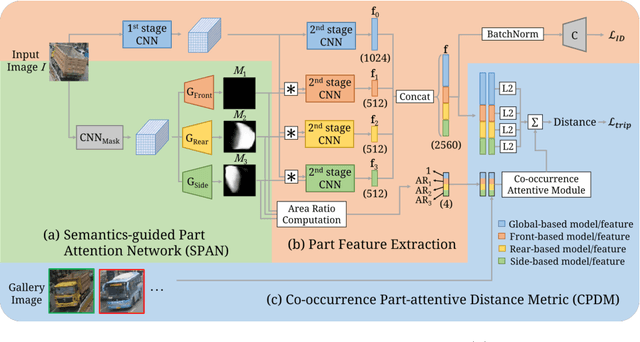
Vehicle re-identification (re-ID) focuses on matching images of the same vehicle across different cameras. It is fundamentally challenging because differences between vehicles are sometimes subtle. While several studies incorporate spatial-attention mechanisms to help vehicle re-ID, they often require expensive keypoint labels or suffer from noisy attention mask if not trained with expensive labels. In this work, we propose a dedicated Semantics-guided Part Attention Network (SPAN) to robustly predict part attention masks for different views of vehicles given only image-level semantic labels during training. With the help of part attention masks, we can extract discriminative features in each part separately. Then we introduce Co-occurrence Part-attentive Distance Metric (CPDM) which places greater emphasis on co-occurrence vehicle parts when evaluating the feature distance of two images. Extensive experiments validate the effectiveness of the proposed method and show that our framework outperforms the state-of-the-art approaches.
Utilising Low Complexity CNNs to Lift Non-Local Redundancies in Video Coding
Oct 19, 2019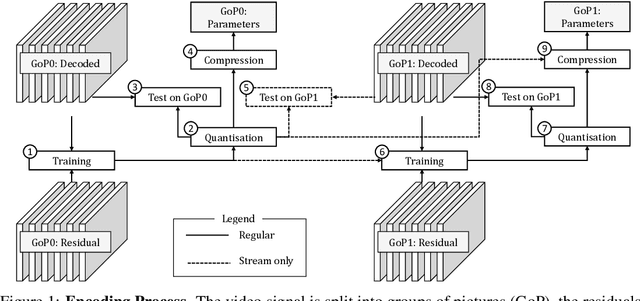


Digital media is ubiquitous and produced in ever-growing quantities. This necessitates a constant evolution of compression techniques, especially for video, in order to maintain efficient storage and transmission. In this work, we aim at exploiting non-local redundancies in video data that remain difficult to erase for conventional video codecs. We design convolutional neural networks with a particular emphasis on low memory and computational footprint. The parameters of those networks are trained on the fly, at encoding time, to predict the residual signal from the decoded video signal. After the training process has converged, the parameters are compressed and signalled as part of the code of the underlying video codec. The method can be applied to any existing video codec to increase coding gains while its low computational footprint allows for an application under resource-constrained conditions. Building on top of High Efficiency Video Coding, we achieve coding gains similar to those of pretrained denoising CNNs while only requiring about 1\% of their computational complexity. Through extensive experiments, we provide insights into the effectiveness of our network design decisions. In addition, we demonstrate that our algorithm delivers stable performance under conditions met in practical video compression: our algorithm performs without significant performance loss on very long random access segments (up to 256 frames) and with moderate performance drops can even be applied to single frames in high resolution low delay settings.
Spatially and Temporally Efficient Non-local Attention Network for Video-based Person Re-Identification
Aug 05, 2019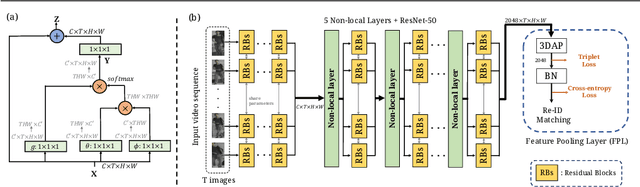
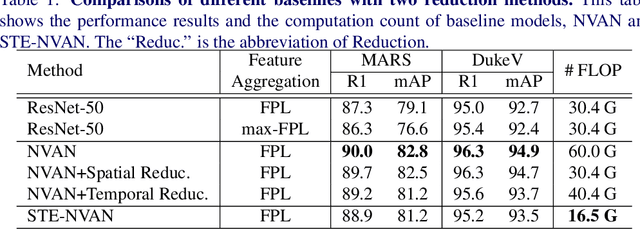
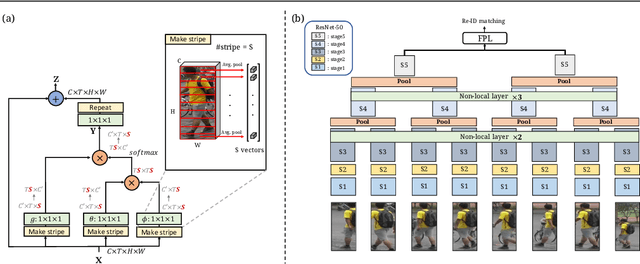
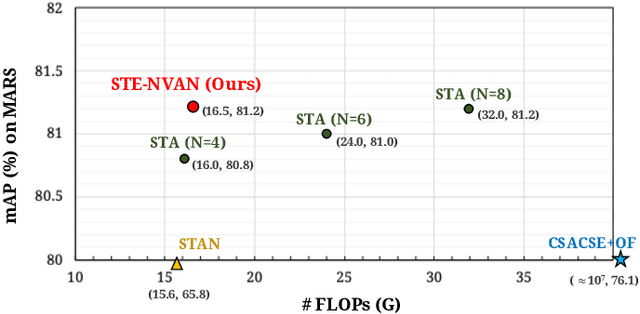
Video-based person re-identification (Re-ID) aims at matching video sequences of pedestrians across non-overlapping cameras. It is a practical yet challenging task of how to embed spatial and temporal information of a video into its feature representation. While most existing methods learn the video characteristics by aggregating image-wise features and designing attention mechanisms in Neural Networks, they only explore the correlation between frames at high-level features. In this work, we target at refining the intermediate features as well as high-level features with non-local attention operations and make two contributions. (i) We propose a Non-local Video Attention Network (NVAN) to incorporate video characteristics into the representation at multiple feature levels. (ii) We further introduce a Spatially and Temporally Efficient Non-local Video Attention Network (STE-NVAN) to reduce the computation complexity by exploring spatial and temporal redundancy presented in pedestrian videos. Extensive experiments show that our NVAN outperforms state-of-the-arts by 3.8% in rank-1 accuracy on MARS dataset and confirms our STE-NVAN displays a much superior computation footprint compared to existing methods.
* This paper was accepted by 2019 British Machine Vision Conference (BMVC)
Increasing Compactness Of Deep Learning Based Speech Enhancement Models With Parameter Pruning And Quantization Techniques
May 31, 2019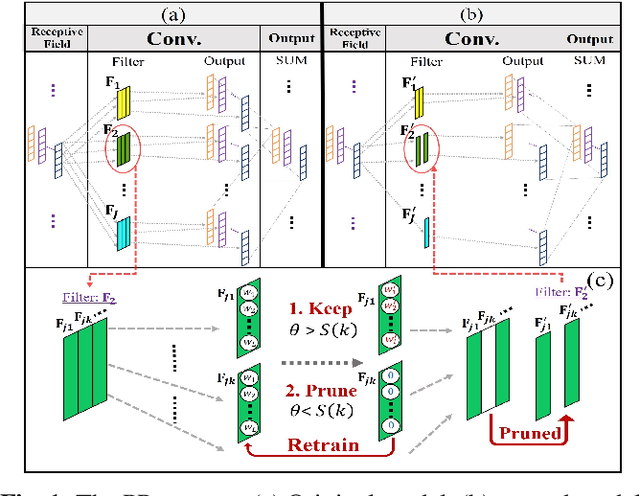
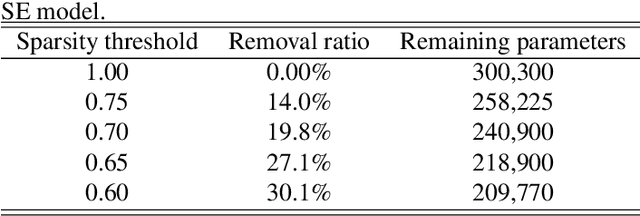
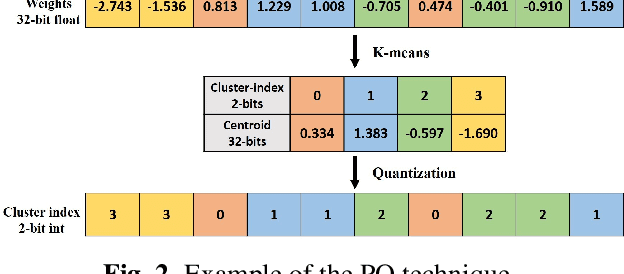
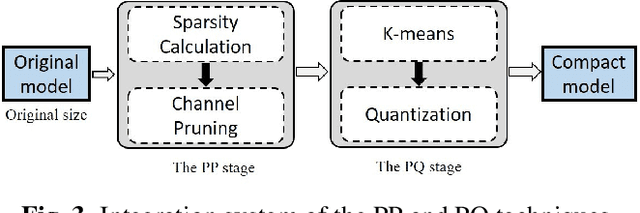
Most recent studies on deep learning based speech enhancement (SE) focused on improving denoising performance. However, successful SE applications require striking a desirable balance between denoising performance and computational cost in real scenarios. In this study, we propose a novel parameter pruning (PP) technique, which removes redundant channels in a neural network. In addition, a parameter quantization (PQ) technique was applied to reduce the size of a neural network by representing weights with fewer cluster centroids. Because the techniques are derived based on different concepts, the PP and PQ can be integrated to provide even more compact SE models. The experimental results show that the PP and PQ techniques produce a compacted SE model with a size of only 10.03% compared to that of the original model, resulting in minor performance losses of 1.43% (from 0.70 to 0.69) for STOI and 3.24% (from 1.85 to 1.79) for PESQ. The promising results suggest that the PP and PQ techniques can be used in a SE system in devices with limited storage and computation resources.