 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Satisfied User and Machine Ratio for Compressed Images: A Unified Approach
Dec 23, 2024



Nowadays, high-quality images are pursued by both humans for better viewing experience and by machines for more accurate visual analysis. However, images are usually compressed before being consumed, decreasing their quality. It is meaningful to predict the perceptual quality of compressed images for both humans and machines, which guides the optimization for compression. In this paper, we propose a unified approach to address this. Specifically, we create a deep learning-based model to predict Satisfied User Ratio (SUR) and Satisfied Machine Ratio (SMR) of compressed images simultaneously. We first pre-train a feature extractor network on a large-scale SMR-annotated dataset with human perception-related quality labels generated by diverse image quality models, which simulates the acquisition of SUR labels. Then, we propose an MLP-Mixer-based network to predict SUR and SMR by leveraging and fusing the extracted multi-layer features. We introduce a Difference Feature Residual Learning (DFRL) module to learn more discriminative difference features. We further use a Multi-Head Attention Aggregation and Pooling (MHAAP) layer to aggregate difference features and reduce their redundancy. Experimental results indicate that the proposed model significantly outperforms state-of-the-art SUR and SMR prediction methods. Moreover, our joint learning scheme of human and machine perceptual quality prediction tasks is effective at improving the performance of both.
Advanced Learning-Based Inter Prediction for Future Video Coding
Nov 24, 2024



In the fourth generation Audio Video coding Standard (AVS4), the Inter Prediction Filter (INTERPF) reduces discontinuities between prediction and adjacent reconstructed pixels in inter prediction. The paper proposes a low complexity learning-based inter prediction (LLIP) method to replace the traditional INTERPF. LLIP enhances the filtering process by leveraging a lightweight neural network model, where parameters can be exported for efficient inference. Specifically, we extract pixels and coordinates utilized by the traditional INTERPF to form the training dataset. Subsequently, we export the weights and biases of the trained neural network model and implement the inference process without any third-party dependency, enabling seamless integration into video codec without relying on Libtorch, thus achieving faster inference speed. Ultimately, we replace the traditional handcraft filtering parameters in INTERPF with the learned optimal filtering parameters. This practical solution makes the combination of deep learning encoding tools with traditional video encoding schemes more efficient. Experimental results show that our approach achieves 0.01%, 0.31%, and 0.25% coding gain for the Y, U, and V components under the random access (RA) configuration on average.
Diffusion-Based 3D Human Pose Estimation with Multi-Hypothesis Aggregation
Mar 21, 2023



In this paper, a novel Diffusion-based 3D Pose estimation (D3DP) method with Joint-wise reProjection-based Multi-hypothesis Aggregation (JPMA) is proposed for probabilistic 3D human pose estimation. On the one hand, D3DP generates multiple possible 3D pose hypotheses for a single 2D observation. It gradually diffuses the ground truth 3D poses to a random distribution, and learns a denoiser conditioned on 2D keypoints to recover the uncontaminated 3D poses. The proposed D3DP is compatible with existing 3D pose estimators and supports users to balance efficiency and accuracy during inference through two customizable parameters. On the other hand, JPMA is proposed to assemble multiple hypotheses generated by D3DP into a single 3D pose for practical use. It reprojects 3D pose hypotheses to the 2D camera plane, selects the best hypothesis joint-by-joint based on the reprojection errors, and combines the selected joints into the final pose. The proposed JPMA conducts aggregation at the joint level and makes use of the 2D prior information, both of which have been overlooked by previous approaches. Extensive experiments on Human3.6M and MPI-INF-3DHP datasets show that our method outperforms the state-of-the-art deterministic and probabilistic approaches by 1.5% and 8.9%, respectively. Code is available at https://github.com/paTRICK-swk/D3DP.
SMR: Satisfied Machine Ratio Modeling for Machine Recognition-Oriented Image and Video Compression
Nov 13, 2022



Tons of images and videos are fed into machines for visual recognition all the time. Like human vision system (HVS), machine vision system (MVS) is sensitive to image quality, as quality degradation leads to information loss and recognition failure. In recent years, MVS-targeted image processing, particularly image and video compression, has emerged. However, existing methods only target an individual machine rather than the general machine community, thus cannot satisfy every type of machine. Moreover, the MVS characteristics are not well leveraged, which limits compression efficiency. In this paper, we introduce a new concept, Satisfied Machine Ratio (SMR), to address these issues. SMR statistically measures the image quality from the machine's perspective by collecting and combining satisfaction scores from a large quantity and variety of machine subjects, where such scores are obtained with MVS characteristics considered properly. We create the first large-scale SMR dataset that contains over 22 million annotated images for SMR studies. Furthermore, a deep learning-based model is proposed to predict the SMR for any given compressed image or video frame. Extensive experiments show that using the SMR model can significantly improve the performance of machine recognition-oriented image and video compression. And the SMR model generalizes well to unseen machines, compression frameworks, and datasets.
STIP: A SpatioTemporal Information-Preserving and Perception-Augmented Model for High-Resolution Video Prediction
Jun 09, 2022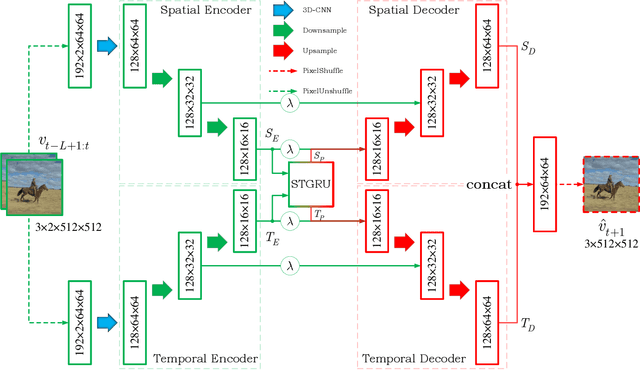
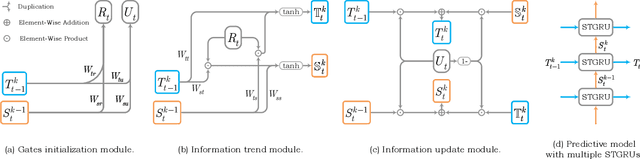
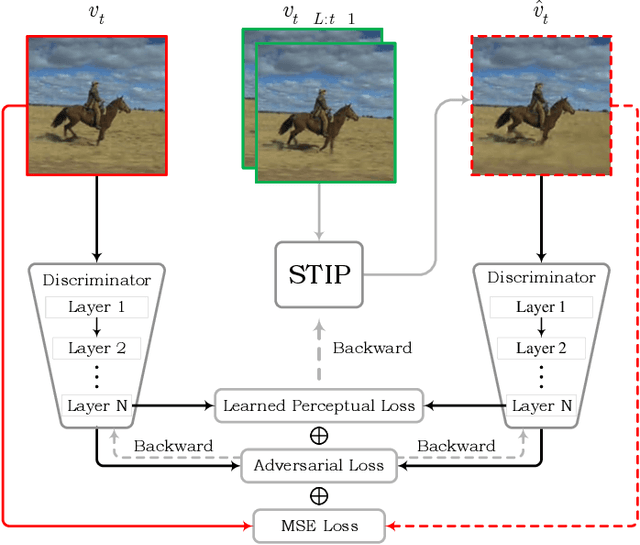

Although significant achievements have been achieved by recurrent neural network (RNN) based video prediction methods, their performance in datasets with high resolutions is still far from satisfactory because of the information loss problem and the perception-insensitive mean square error (MSE) based loss functions. In this paper, we propose a Spatiotemporal Information-Preserving and Perception-Augmented Model (STIP) to solve the above two problems. To solve the information loss problem, the proposed model aims to preserve the spatiotemporal information for videos during the feature extraction and the state transitions, respectively. Firstly, a Multi-Grained Spatiotemporal Auto-Encoder (MGST-AE) is designed based on the X-Net structure. The proposed MGST-AE can help the decoders recall multi-grained information from the encoders in both the temporal and spatial domains. In this way, more spatiotemporal information can be preserved during the feature extraction for high-resolution videos. Secondly, a Spatiotemporal Gated Recurrent Unit (STGRU) is designed based on the standard Gated Recurrent Unit (GRU) structure, which can efficiently preserve spatiotemporal information during the state transitions. The proposed STGRU can achieve more satisfactory performance with a much lower computation load compared with the popular Long Short-Term (LSTM) based predictive memories. Furthermore, to improve the traditional MSE loss functions, a Learned Perceptual Loss (LP-loss) is further designed based on the Generative Adversarial Networks (GANs), which can help obtain a satisfactory trade-off between the objective quality and the perceptual quality. Experimental results show that the proposed STIP can predict videos with more satisfactory visual quality compared with a variety of state-of-the-art methods. Source code has been available at \url{https://github.com/ZhengChang467/STIPHR}.
Hierarchical Similarity Learning for Aliasing Suppression Image Super-Resolution
Jun 07, 2022



As a highly ill-posed issue, single image super-resolution (SISR) has been widely investigated in recent years. The main task of SISR is to recover the information loss caused by the degradation procedure. According to the Nyquist sampling theory, the degradation leads to aliasing effect and makes it hard to restore the correct textures from low-resolution (LR) images. In practice, there are correlations and self-similarities among the adjacent patches in the natural images. This paper considers the self-similarity and proposes a hierarchical image super-resolution network (HSRNet) to suppress the influence of aliasing. We consider the SISR issue in the optimization perspective, and propose an iterative solution pattern based on the half-quadratic splitting (HQS) method. To explore the texture with local image prior, we design a hierarchical exploration block (HEB) and progressive increase the receptive field. Furthermore, multi-level spatial attention (MSA) is devised to obtain the relations of adjacent feature and enhance the high-frequency information, which acts as a crucial role for visual experience. Experimental result shows HSRNet achieves better quantitative and visual performance than other works, and remits the aliasing more effectively.
Textural-Structural Joint Learning for No-Reference Super-Resolution Image Quality Assessment
May 27, 2022
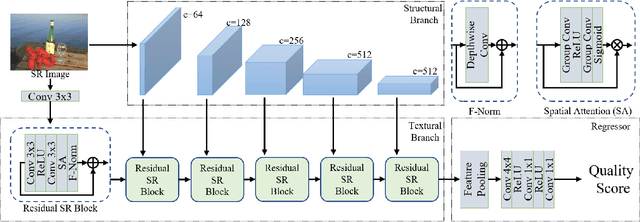
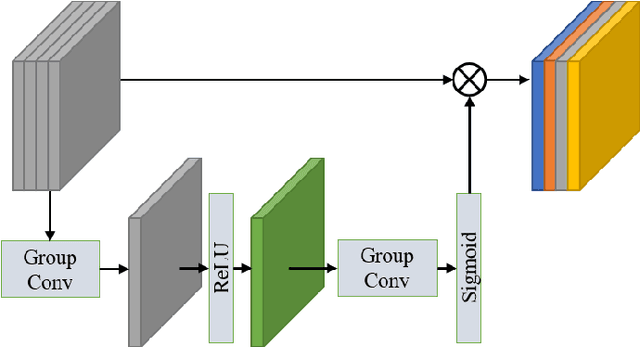

Image super-resolution (SR) has been widely investigated in recent years. However, it is challenging to fairly estimate the performances of various SR methods, as the lack of reliable and accurate criteria for perceptual quality. Existing SR image quality assessment (IQA) metrics usually concentrate on the specific kind of degradation without distinguishing the visual sensitive areas, which have no adaptive ability to describe the diverse SR degeneration situations. In this paper, we focus on the textural and structural degradation of image SR which acts as a critical role for visual perception, and design a dual stream network to jointly explore the textural and structural information for quality prediction, dubbed TSNet. By mimicking the human vision system (HVS) that pays more attention to the significant areas of the image, we develop the spatial attention mechanism to make the visual-sensitive areas more distinguishable, which improves the prediction accuracy. Feature normalization (F-Norm) is also developed to investigate the inherent spatial correlation of SR features and boost the network representation capacity. Experimental results show the proposed TSNet predicts the visual quality more accurate than the state-of-the-art IQA methods, and demonstrates better consistency with the human's perspective. The source code will be made available at http://github.com/yuqing-liu-dut/NRIQA_SR.
Learning Weighting Map for Bit-Depth Expansion within a Rational Range
Apr 26, 2022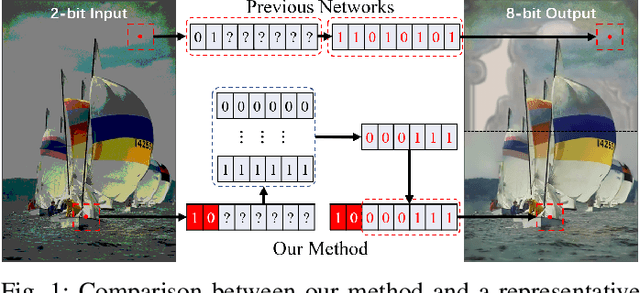


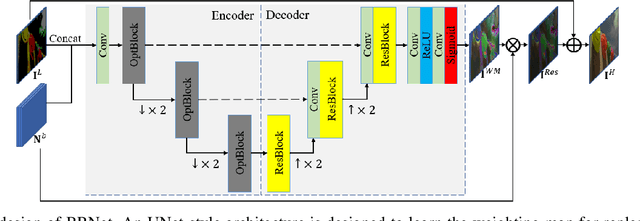
Bit-depth expansion (BDE) is one of the emerging technologies to display high bit-depth (HBD) image from low bit-depth (LBD) source. Existing BDE methods have no unified solution for various BDE situations, and directly learn a mapping for each pixel from LBD image to the desired value in HBD image, which may change the given high-order bits and lead to a huge deviation from the ground truth. In this paper, we design a bit restoration network (BRNet) to learn a weight for each pixel, which indicates the ratio of the replenished value within a rational range, invoking an accurate solution without modifying the given high-order bit information. To make the network adaptive for any bit-depth degradation, we investigate the issue in an optimization perspective and train the network under progressive training strategy for better performance. Moreover, we employ Wasserstein distance as a visual quality indicator to evaluate the difference of color distribution between restored image and the ground truth. Experimental results show our method can restore colorful images with fewer artifacts and false contours, and outperforms state-of-the-art methods with higher PSNR/SSIM results and lower Wasserstein distance. The source code will be made available at https://github.com/yuqing-liu-dut/bit-depth-expansion
STAU: A SpatioTemporal-Aware Unit for Video Prediction and Beyond
Apr 20, 2022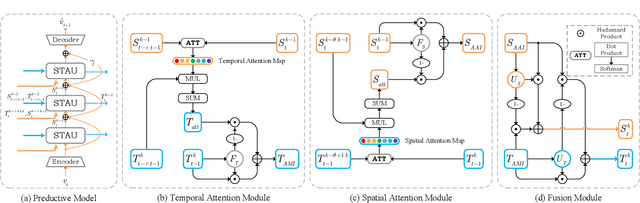


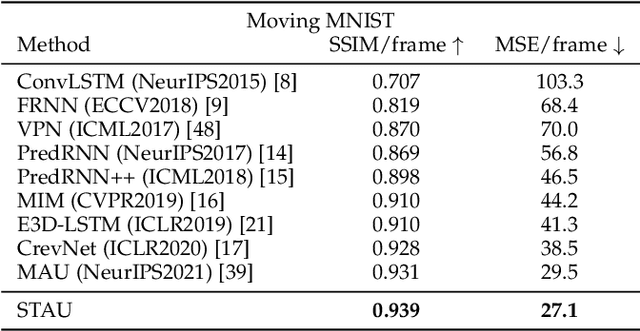
Video prediction aims to predict future frames by modeling the complex spatiotemporal dynamics in videos. However, most of the existing methods only model the temporal information and the spatial information for videos in an independent manner but haven't fully explored the correlations between both terms. In this paper, we propose a SpatioTemporal-Aware Unit (STAU) for video prediction and beyond by exploring the significant spatiotemporal correlations in videos. On the one hand, the motion-aware attention weights are learned from the spatial states to help aggregate the temporal states in the temporal domain. On the other hand, the appearance-aware attention weights are learned from the temporal states to help aggregate the spatial states in the spatial domain. In this way, the temporal information and the spatial information can be greatly aware of each other in both domains, during which, the spatiotemporal receptive field can also be greatly broadened for more reliable spatiotemporal modeling. Experiments are not only conducted on traditional video prediction tasks but also other tasks beyond video prediction, including the early action recognition and object detection tasks. Experimental results show that our STAU can outperform other methods on all tasks in terms of performance and computation efficiency.
STRPM: A Spatiotemporal Residual Predictive Model for High-Resolution Video Prediction
Mar 30, 2022
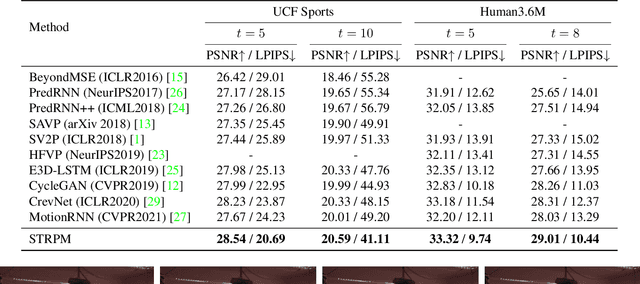
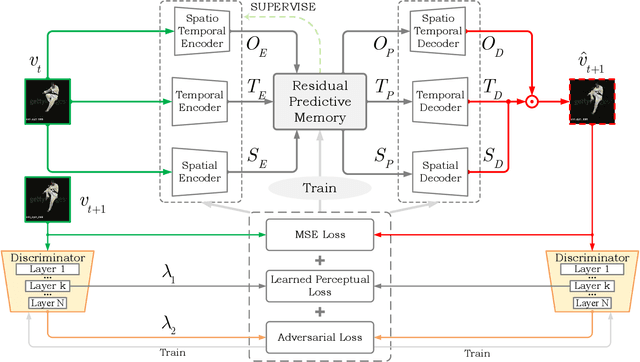
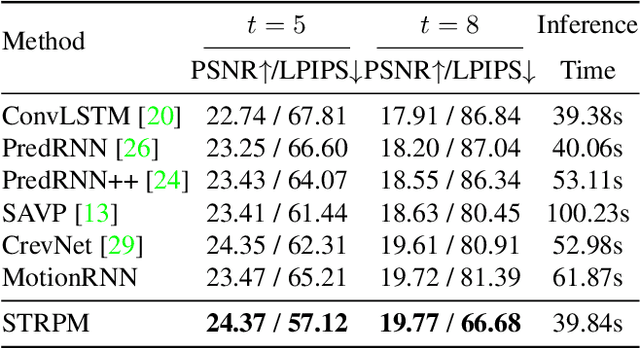
Although many video prediction methods have obtained good performance in low-resolution (64$\sim$128) videos, predictive models for high-resolution (512$\sim$4K) videos have not been fully explored yet, which are more meaningful due to the increasing demand for high-quality videos. Compared with low-resolution videos, high-resolution videos contain richer appearance (spatial) information and more complex motion (temporal) information. In this paper, we propose a Spatiotemporal Residual Predictive Model (STRPM) for high-resolution video prediction. On the one hand, we propose a Spatiotemporal Encoding-Decoding Scheme to preserve more spatiotemporal information for high-resolution videos. In this way, the appearance details for each frame can be greatly preserved. On the other hand, we design a Residual Predictive Memory (RPM) which focuses on modeling the spatiotemporal residual features (STRF) between previous and future frames instead of the whole frame, which can greatly help capture the complex motion information in high-resolution videos. In addition, the proposed RPM can supervise the spatial encoder and temporal encoder to extract different features in the spatial domain and the temporal domain, respectively. Moreover, the proposed model is trained using generative adversarial networks (GANs) with a learned perceptual loss (LP-loss) to improve the perceptual quality of the predictions. Experimental results show that STRPM can generate more satisfactory results compared with various existing methods.