 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Network for Image Super-Resolution
May 20, 2020
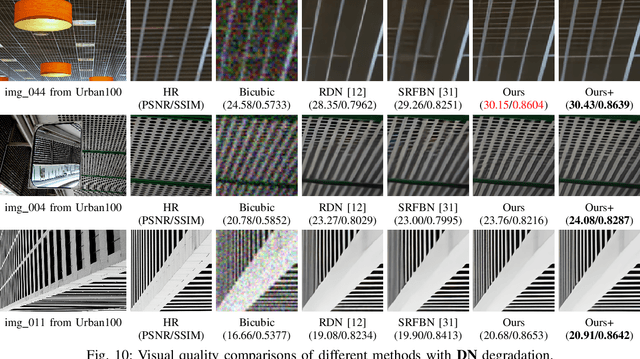
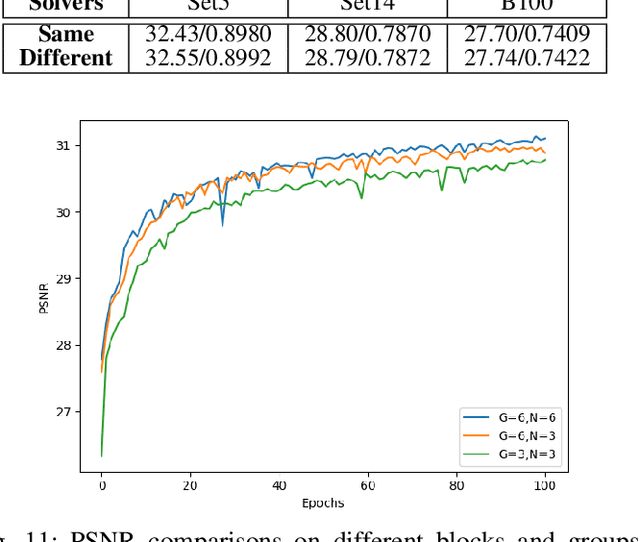
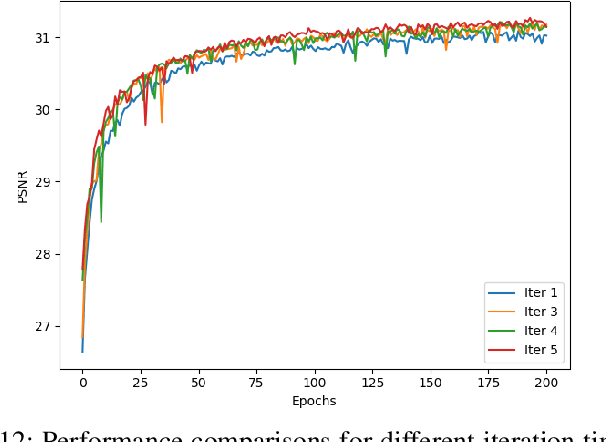
Single image super-resolution (SISR), as a traditional ill-conditioned inverse problem, has been greatly revitalized by the recent development of convolutional neural networks (CNN). These CNN-based methods generally map a low-resolution image to its corresponding high-resolution version with sophisticated network structures and loss functions, showing impressive performances. This paper proposes a substantially different approach relying on the iterative optimization on HR space with an iterative super-resolution network (ISRN). We first analyze the observation model of image SR problem, inspiring a feasible solution by mimicking and fusing each iteration in a more general and efficient manner. Considering the drawbacks of batch normalization, we propose a feature normalization (FNorm) method to regulate the features in network. Furthermore, a novel block with F-Norm is developed to improve the network representation, termed as FNB. Residual-in-residual structure is proposed to form a very deep network, which groups FNBs with a long skip connection for better information delivery and stabling the training phase. Extensive experimental results on testing benchmarks with bicubic (BI) degradation show our ISRN can not only recover more structural information, but also achieve competitive or better PSNR/SSIM results with much fewer parameters compared to other works. Besides BI, we simulate the real-world degradation with blur-downscale (BD) and downscalenoise (DN). ISRN and its extension ISRN+ both achieve better performance than others with BD and DN degradation models.
HiFaceGAN: Face Renovation via Collaborative Suppression and Replenishment
May 11, 2020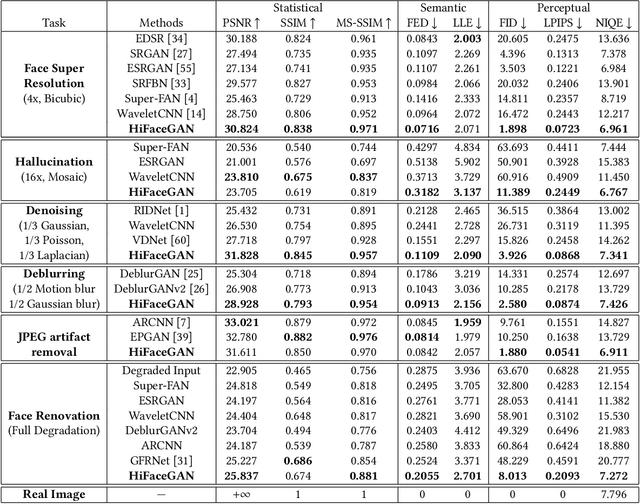

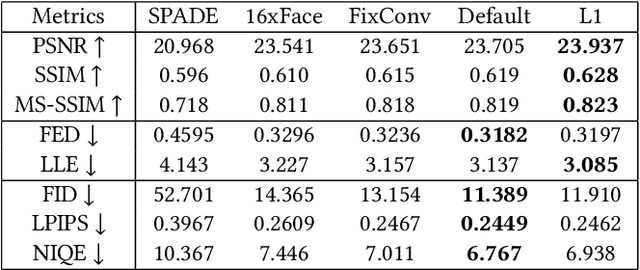
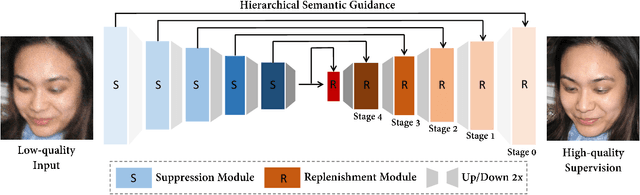
Existing face restoration researches typically relies on either the degradation prior or explicit guidance labels for training, which often results in limited generalization ability over real-world images with heterogeneous degradations and rich background contents. In this paper, we investigate the more challenging and practical "dual-blind" version of the problem by lifting the requirements on both types of prior, termed as "Face Renovation"(FR). Specifically, we formulated FR as a semantic-guided generation problem and tackle it with a collaborative suppression and replenishment (CSR) approach. This leads to HiFaceGAN, a multi-stage framework containing several nested CSR units that progressively replenish facial details based on the hierarchical semantic guidance extracted from the front-end content-adaptive suppression modules. Extensive experiments on both synthetic and real face images have verified the superior performance of HiFaceGAN over a wide range of challenging restoration subtasks, demonstrating its versatility, robustness and generalization ability towards real-world face processing applications.
Towards Analysis-friendly Face Representation with Scalable Feature and Texture Compression
Apr 21, 2020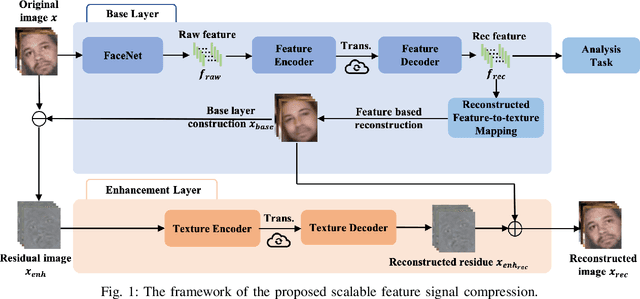
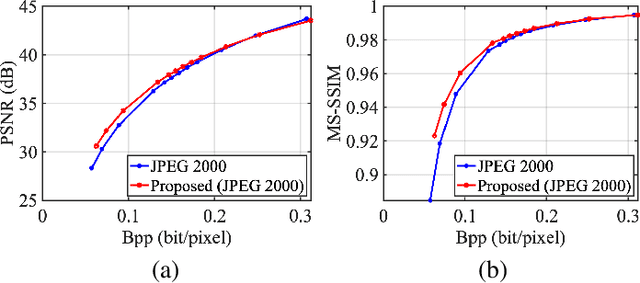
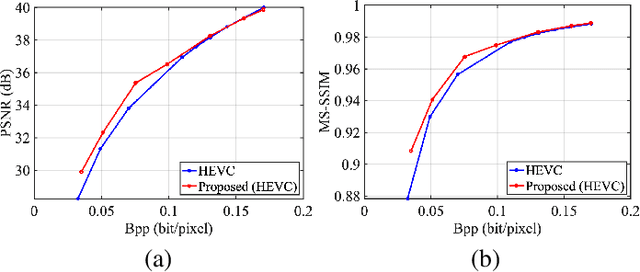
It plays a fundamental role to compactly represent the visual information towards the optimization of the ultimate utility in myriad visual data centered applications. With numerous approaches proposed to efficiently compress the texture and visual features serving human visual perception and machine intelligence respectively, much less work has been dedicated to studying the interactions between them. Here we investigate the integration of feature and texture compression, and show that a universal and collaborative visual information representation can be achieved in a hierarchical way. In particular, we study the feature and texture compression in a scalable coding framework, where the base layer serves as the deep learning feature and enhancement layer targets to perfectly reconstruct the texture. Based on the strong generative capability of deep neural networks, the gap between the base feature layer and enhancement layer is further filled with the feature level texture reconstruction, aiming to further construct texture representation from feature. As such, the residuals between the original and reconstructed texture could be further conveyed in the enhancement layer. To improve the efficiency of the proposed framework, the base layer neural network is trained in a multi-task manner such that the learned features enjoy both high quality reconstruction and high accuracy analysis. We further demonstrate the framework and optimization strategies in face image compression, and promising coding performance has been achieved in terms of both rate-fidelity and rate-accuracy.
Masked Non-Autoregressive Image Captioning
Jun 03, 2019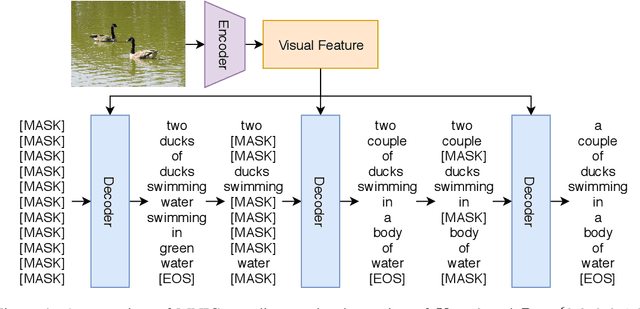
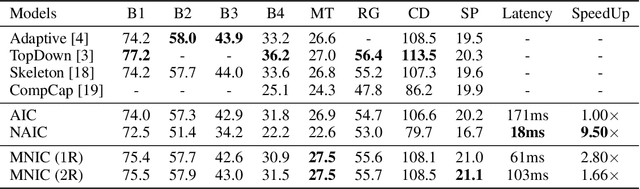
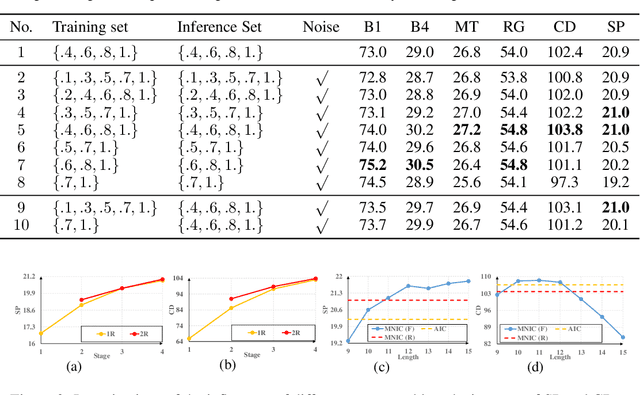
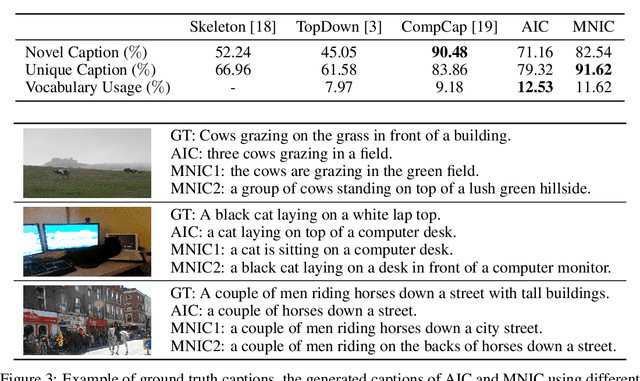
Existing captioning models often adopt the encoder-decoder architecture, where the decoder uses autoregressive decoding to generate captions, such that each token is generated sequentially given the preceding generated tokens. However, autoregressive decoding results in issues such as sequential error accumulation, slow generation, improper semantics and lack of diversity. Non-autoregressive decoding has been proposed to tackle slow generation for neural machine translation but suffers from multimodality problem due to the indirect modeling of the target distribution. In this paper, we propose masked non-autoregressive decoding to tackle the issues of both autoregressive decoding and non-autoregressive decoding. In masked non-autoregressive decoding, we mask several kinds of ratios of the input sequences during training, and generate captions parallelly in several stages from a totally masked sequence to a totally non-masked sequence in a compositional manner during inference. Experimentally our proposed model can preserve semantic content more effectively and can generate more diverse captions.
Self-critical n-step Training for Image Captioning
Apr 15, 2019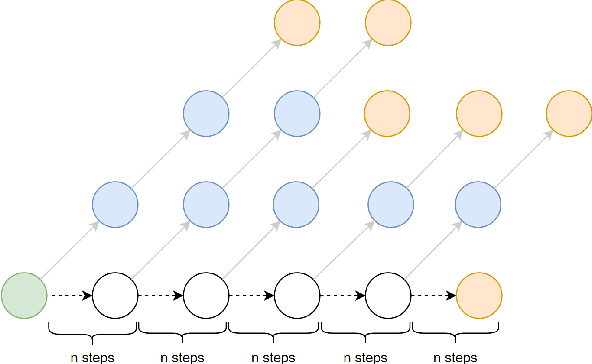
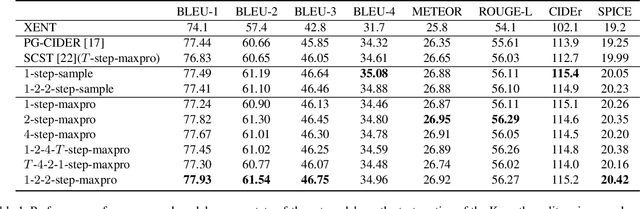
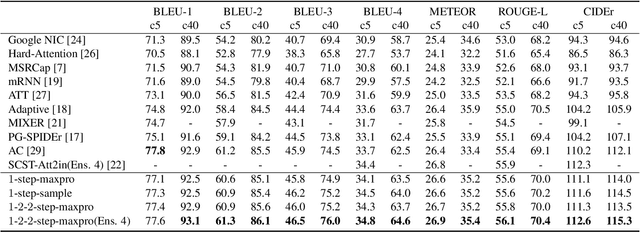

Existing methods for image captioning are usually trained by cross entropy loss, which leads to exposure bias and the inconsistency between the optimizing function and evaluation metrics. Recently it has been shown that these two issues can be addressed by incorporating techniques from reinforcement learning, where one of the popular techniques is the advantage actor-critic algorithm that calculates per-token advantage by estimating state value with a parametrized estimator at the cost of introducing estimation bias. In this paper, we estimate state value without using a parametrized value estimator. With the properties of image captioning, namely, the deterministic state transition function and the sparse reward, state value is equivalent to its preceding state-action value, and we reformulate advantage function by simply replacing the former with the latter. Moreover, the reformulated advantage is extended to n-step, which can generally increase the absolute value of the mean of reformulated advantage while lowering variance. Then two kinds of rollout are adopted to estimate state-action value, which we call self-critical n-step training. Empirically we find that our method can obtain better performance compared to the state-of-the-art methods that use the sequence level advantage and parametrized estimator respectively on the widely used MSCOCO benchmark.
Image and Video Compression with Neural Networks: A Review
Apr 10, 2019
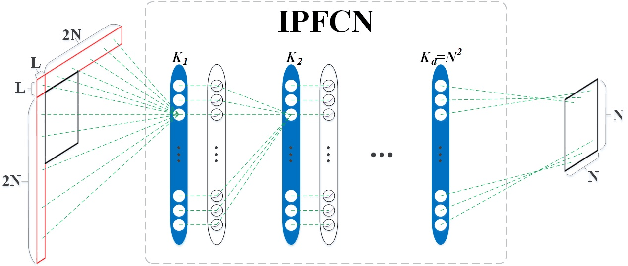
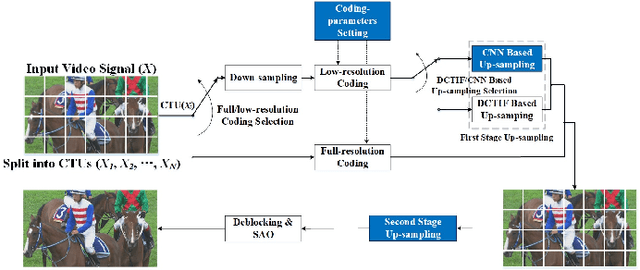
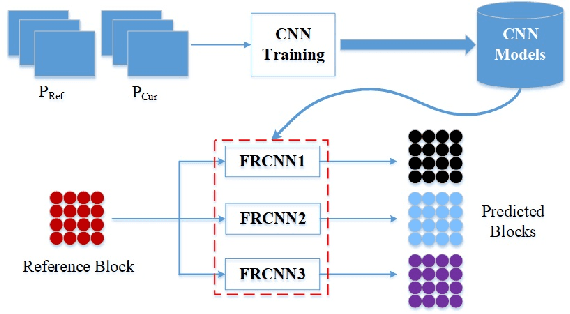
In recent years, the image and video coding technologies have advanced by leaps and bounds. However, due to the popularization of image and video acquisition devices, the growth rate of image and video data is far beyond the improvement of the compression ratio. In particular, it has been widely recognized that there are increasing challenges of pursuing further coding performance improvement within the traditional hybrid coding framework. Deep convolution neural network (CNN) which makes the neural network resurge in recent years and has achieved great success in both artificial intelligent and signal processing fields, also provides a novel and promising solution for image and video compression. In this paper, we provide a systematic, comprehensive and up-to-date review of neural network based image and video compression techniques. The evolution and development of neural network based compression methodologies are introduced for images and video respectively. More specifically, the cutting-edge video coding techniques by leveraging deep learning and HEVC framework are presented and discussed, which promote the state-of-the-art video coding performance substantially. Moreover, the end-to-end image and video coding frameworks based on neural networks are also reviewed, revealing interesting explorations on next generation image and video coding frameworks/standards. The most significant research works on the image and video coding related topics using neural networks are highlighted, and future trends are also envisioned. In particular, the joint compression on semantic and visual information is tentatively explored to formulate high efficiency signal representation structure for both human vision and machine vision, which are the two dominant signal receptor in the age of artificial intelligence.
Scalable Facial Image Compression with Deep Feature Reconstruction
Mar 14, 2019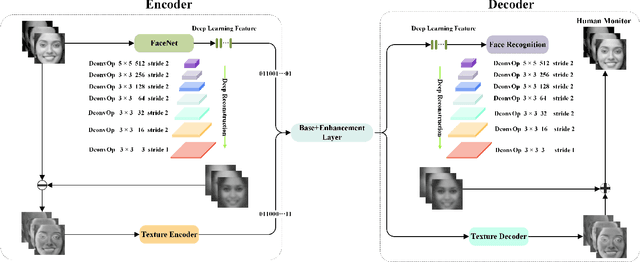
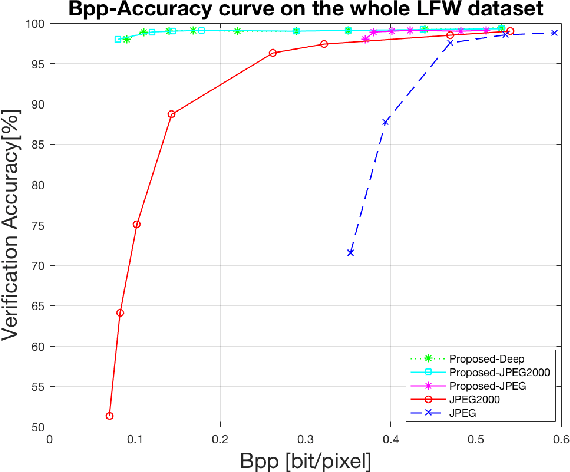


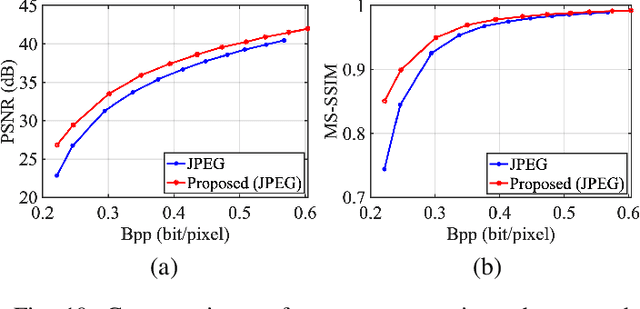
In this paper, we propose a scalable image compression scheme, including the base layer for feature representation and enhancement layer for texture representation. More specifically, the base layer is designed as the deep learning feature for analysis purpose, and it can also be converted to the fine structure with deep feature reconstruction. The enhancement layer, which serves to compress the residuals between the input image and the signals generated from the base layer, aims to faithfully reconstruct the input texture. The proposed scheme can feasibly inherit the advantages of both compress-then-analyze and analyze-then-compress schemes in surveillance applications. The performance of this framework is validated with facial images, and the conducted experiments provide useful evidences to show that the proposed framework can achieve better rate-accuracy and rate-distortion performance over conventional image compression schemes.