 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective LLM-Guided Regularization for Enhancing Recommendation Models
Dec 25, 2025



Large language models provide rich semantic priors and strong reasoning capabilities, making them promising auxiliary signals for recommendation. However, prevailing approaches either deploy LLMs as standalone recommender or apply global knowledge distillation, both of which suffer from inherent drawbacks. Standalone LLM recommender are costly, biased, and unreliable across large regions of the user item space, while global distillation forces the downstream model to imitate LLM predictions even when such guidance is inaccurate. Meanwhile, recent studies show that LLMs excel particularly in re-ranking and challenging scenarios, rather than uniformly across all contexts.We introduce Selective LLM Guided Regularization, a model-agnostic and computation efficient framework that activates LLM based pairwise ranking supervision only when a trainable gating mechanism informing by user history length, item popularity, and model uncertainty predicts the LLM to be reliable. All LLM scoring is performed offline, transferring knowledge without increasing inference cost. Experiments across multiple datasets show that this selective strategy consistently improves overall accuracy and yields substantial gains in cold start and long tail regimes, outperforming global distillation baselines.
Neyman-Pearson Detector for Ambient Backscatter Zero-Energy-Devices Beacons
Apr 14, 2025Recently, a novel ultra-low power indoor wireless positioning system has been proposed. In this system, Zero-Energy-Devices (ZED) beacons are deployed in Indoor environments, and located on a map with unique broadcast identifiers. They harvest ambient energy to power themselves and backscatter ambient waves from cellular networks to send their identifiers. This paper presents a novel detection method for ZEDs in ambient backscatter systems, with an emphasis on performance evaluation through experimental setups and simulations. We introduce a Neyman-Pearson detection framework, which leverages a predefined false alarm probability to determine the optimal detection threshold. This method, applied to the analysis of backscatter signals in a controlled testbed environment, incorporates the use of BC sequences to enhance signal detection accuracy. The experimental setup, conducted on the FIT/CorteXlab testbed, employs a two-node configuration for signal transmission and reception. Key performance metrics, which is the peak-to-lobe ratio, is evaluated, confirming the effectiveness of the proposed detection model. The results demonstrate a detection system that effectively handles varying noise levels and identifies ZEDs with high reliability. The simulation results show the robustness of the model, highlighting its capacity to achieve desired detection performance even with stringent false alarm thresholds. This work paves the way for robust ZED detection in real-world scenarios, contributing to the advancement of wireless communication technologies.
No Preference Left Behind: Group Distributional Preference Optimization
Dec 28, 2024



Preferences within a group of people are not uniform but follow a distribution. While existing alignment methods like Direct Preference Optimization (DPO) attempt to steer models to reflect human preferences, they struggle to capture the distributional pluralistic preferences within a group. These methods often skew toward dominant preferences, overlooking the diversity of opinions, especially when conflicting preferences arise. To address this issue, we propose Group Distribution Preference Optimization (GDPO), a novel framework that aligns language models with the distribution of preferences within a group by incorporating the concept of beliefs that shape individual preferences. GDPO calibrates a language model using statistical estimation of the group's belief distribution and aligns the model with belief-conditioned preferences, offering a more inclusive alignment framework than traditional methods. In experiments using both synthetic controllable opinion generation and real-world movie review datasets, we show that DPO fails to align with the targeted belief distributions, while GDPO consistently reduces this alignment gap during training. Moreover, our evaluation metrics demonstrate that GDPO outperforms existing approaches in aligning with group distributional preferences, marking a significant advance in pluralistic alignment.
Optimizing Social Media Annotation of HPV Vaccine Skepticism and Misinformation Using Large Language Models: An Experimental Evaluation of In-Context Learning and Fine-Tuning Stance Detection Across Multiple Models
Nov 22, 2024


This paper leverages large-language models (LLMs) to experimentally determine optimal strategies for scaling up social media content annotation for stance detection on HPV vaccine-related tweets. We examine both conventional fine-tuning and emergent in-context learning methods, systematically varying strategies of prompt engineering across widely used LLMs and their variants (e.g., GPT4, Mistral, and Llama3, etc.). Specifically, we varied prompt template design, shot sampling methods, and shot quantity to detect stance on HPV vaccination. Our findings reveal that 1) in general, in-context learning outperforms fine-tuning in stance detection for HPV vaccine social media content; 2) increasing shot quantity does not necessarily enhance performance across models; and 3) different LLMs and their variants present differing sensitivity to in-context learning conditions. We uncovered that the optimal in-context learning configuration for stance detection on HPV vaccine tweets involves six stratified shots paired with detailed contextual prompts. This study highlights the potential and provides an applicable approach for applying LLMs to research on social media stance and skepticism detection.
Improving Bilingual Capabilities of Language Models to Support Diverse Linguistic Practices in Education
Nov 06, 2024



Large language models (LLMs) offer promise in generating educational content, providing instructor feedback, and reducing teacher workload on assessments. While prior studies have focused on studying LLM-powered learning analytics, limited research has examined how effective LLMs are in a bilingual context. In this paper, we study the effectiveness of multilingual large language models (MLLMs) across monolingual (English-only, Spanish-only) and bilingual (Spanglish) student writing. We present a learning analytics use case that details LLM performance in assessing acceptable and unacceptable explanations of Science and Social Science concepts. Our findings reveal a significant bias in the grading performance of pre-trained models for bilingual writing compared to English-only and Spanish-only writing. Following this, we fine-tune open-source MLLMs including Llama 3.1 and Mistral NeMo using synthetic datasets generated in English, Spanish, and Spanglish. Our experiments indicate that the models perform significantly better for all three languages after fine-tuning with bilingual data. This study highlights the potential of enhancing MLLM effectiveness to support authentic language practices amongst bilingual learners. It also aims to illustrate the value of incorporating non-English languages into the design and implementation of language models in education.
Indoor Localization of Smartphones Thanks to Zero-Energy-Devices Beacons
Feb 26, 2024



In this paper, we present a new ultra-low power method of indoor localization of smartphones (SM) based on zero-energy-devices (ZEDs) beacons instead of active wireless beacons. Each ZED is equipped with a unique identification number coded into a bit-sequence, and its precise position on the map is recorded. An SM inside the building is assumed to have access to the map of ZEDs. The ZED backscatters ambient waves from base stations (BSs) of the cellular network. The SM detects the ZED message in the variations of the received ambient signal from the BS. We accurately simulate the ambient waves from a BS of Orange 4G commercial network, inside an existing large building covered with ZED beacons, thanks to a ray-tracing-based propagation simulation tool. Our first performance evaluation study shows that the proposed localization system enables us to determine in which room a SM is located, in a realistic and challenging propagation scenario.
Imitation Learning for Fashion Style Based on Hierarchical Multimodal Representation
Apr 13, 2020
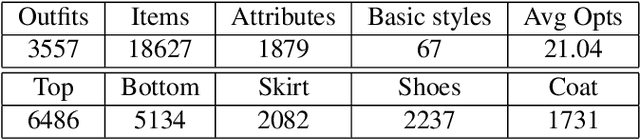
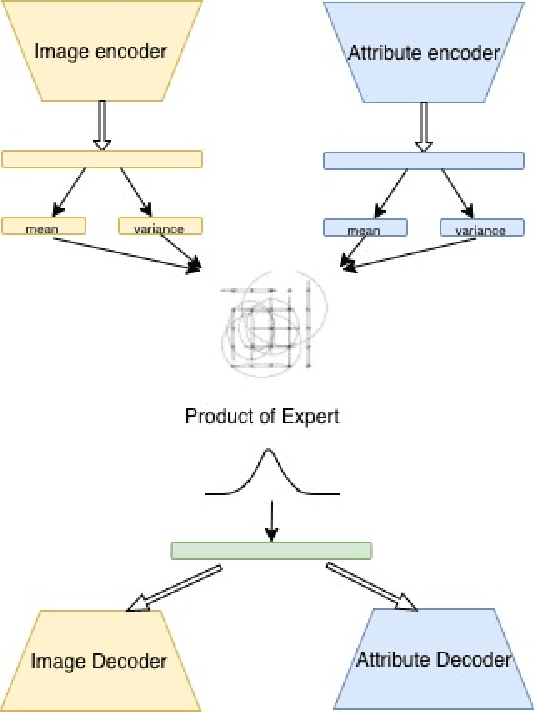
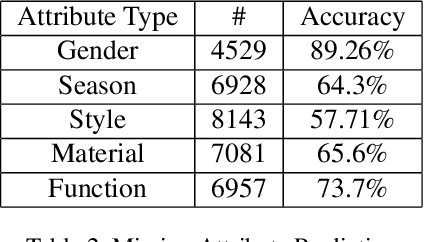
Fashion is a complex social phenomenon. People follow fashion styles from demonstrations by experts or fashion icons. However, for machine agent, learning to imitate fashion experts from demonstrations can be challenging, especially for complex styles in environments with high-dimensional, multimodal observations. Most existing research regarding fashion outfit composition utilizes supervised learning methods to mimic the behaviors of style icons. These methods suffer from distribution shift: because the agent greedily imitates some given outfit demonstrations, it can drift away from one style to another styles given subtle differences. In this work, we propose an adversarial inverse reinforcement learning formulation to recover reward functions based on hierarchical multimodal representation (HM-AIRL) during the imitation process. The hierarchical joint representation can more comprehensively model the expert composited outfit demonstrations to recover the reward function. We demonstrate that the proposed HM-AIRL model is able to recover reward functions that are robust to changes in multimodal observations, enabling us to learn policies under significant variation between different styles.
3D Virtual Garment Modeling from RGB Images
Jul 31, 2019

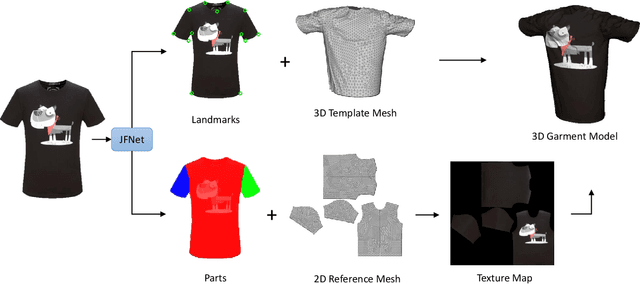

We present a novel approach that constructs 3D virtual garment models from photos. Unlike previous methods that require photos of a garment on a human model or a mannequin, our approach can work with various states of the garment: on a model, on a mannequin, or on a flat surface. To construct a complete 3D virtual model, our approach only requires two images as input, one front view and one back view. We first apply a multi-task learning network called JFNet that jointly predicts fashion landmarks and parses a garment image into semantic parts. The predicted landmarks are used for estimating sizing information of the garment. Then, a template garment mesh is deformed based on the sizing information to generate the final 3D model. The semantic parts are utilized for extracting color textures from input images. The results of our approach can be used in various Virtual Reality and Mixed Reality applications.
Pose Guided Fashion Image Synthesis Using Deep Generative Model
Jun 17, 2019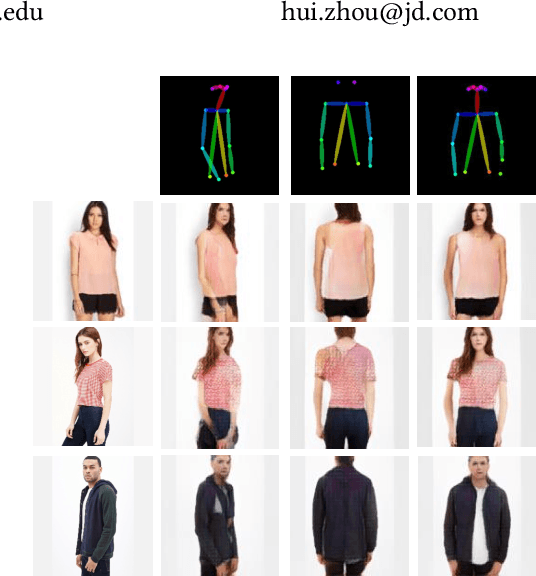
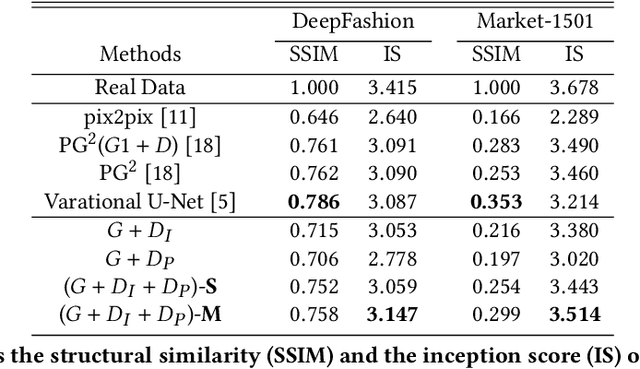
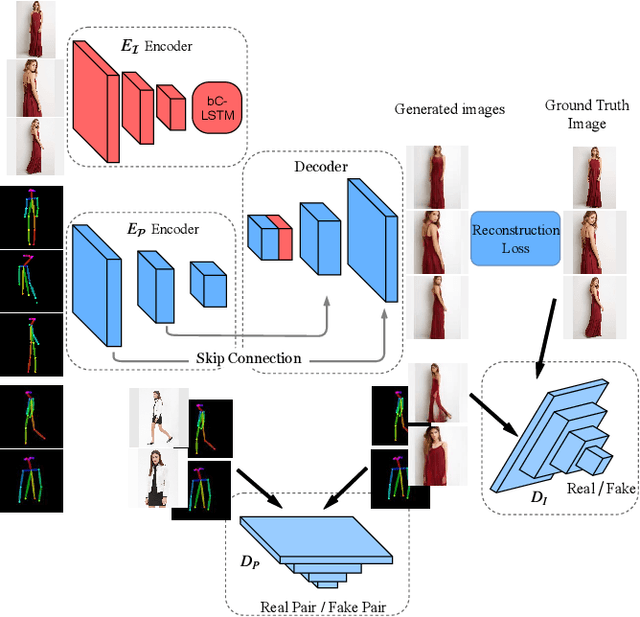

Generating a photorealistic image with intended human pose is a promising yet challenging research topic for many applications such as smart photo editing, movie making, virtual try-on, and fashion display. In this paper, we present a novel deep generative model to transfer an image of a person from a given pose to a new pose while keeping fashion item consistent. In order to formulate the framework, we employ one generator and two discriminators for image synthesis. The generator includes an image encoder, a pose encoder and a decoder. The two encoders provide good representation of visual and geometrical context which will be utilized by the decoder in order to generate a photorealistic image. Unlike existing pose-guided image generation models, we exploit two discriminators to guide the synthesis process where one discriminator differentiates between generated image and real images (training samples), and another discriminator verifies the consistency of appearance between a target pose and a generated image. We perform end-to-end training of the network to learn the parameters through back-propagation given ground-truth images. The proposed generative model is capable of synthesizing a photorealistic image of a person given a target pose. We have demonstrated our results by conducting rigorous experiments on two data sets, both quantitatively and qualitatively.