 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRN: Multiplexed Routing Network for Incremental Multilingual Text Recognition
May 24, 2023Traditional Multilingual Text Recognition (MLTR) usually targets a fixed set of languages and thus struggles to handle newly added languages or adapt to ever-changing class distributions. In this paper, we introduce the Incremental Multilingual Text Recognition (IMLTR) task in the incremental learning setting, where new language data comes in batches. Compared to generic incremental learning, IMLTR is even more challenging as it suffers from rehearsal-imbalance (uneven distribution of sample characters in the rehearsal set). To address this issue, we propose a Multiplexed Routing Network (MRN), where a series of recognizers is trained for each language. Subsequently, a language predictor is adopted to weigh the recognizers for voting. Since the recognizers are derived from the original model, MRN effectively reduces the reliance on older data and is better suited for rehearsal-imbalance. We extensively evaluate MRN on MLT17 and MLT19 datasets, outperforming existing state-of-the-art methods by a large margin, i.e., accuracy improvement ranging from 10.3% to 27.4% under different settings.
TPS++: Attention-Enhanced Thin-Plate Spline for Scene Text Recognition
May 09, 2023Text irregularities pose significant challenges to scene text recognizers. Thin-Plate Spline (TPS)-based rectification is widely regarded as an effective means to deal with them. Currently, the calculation of TPS transformation parameters purely depends on the quality of regressed text borders. It ignores the text content and often leads to unsatisfactory rectified results for severely distorted text. In this work, we introduce TPS++, an attention-enhanced TPS transformation that incorporates the attention mechanism to text rectification for the first time. TPS++ formulates the parameter calculation as a joint process of foreground control point regression and content-based attention score estimation, which is computed by a dedicated designed gated-attention block. TPS++ builds a more flexible content-aware rectifier, generating a natural text correction that is easier to read by the subsequent recognizer. Moreover, TPS++ shares the feature backbone with the recognizer in part and implements the rectification at feature-level rather than image-level, incurring only a small overhead in terms of parameters and inference time. Experiments on public benchmarks show that TPS++ consistently improves the recognition and achieves state-of-the-art accuracy. Meanwhile, it generalizes well on different backbones and recognizers. Code is at https://github.com/simplify23/TPS_PP.
SVTR: Scene Text Recognition with a Single Visual Model
Apr 30, 2022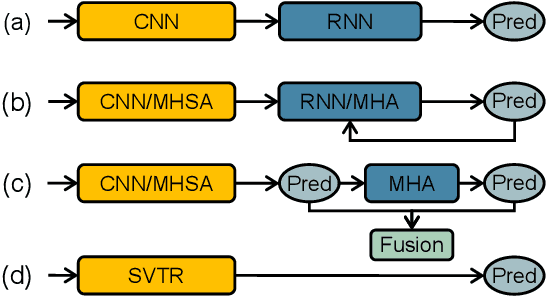

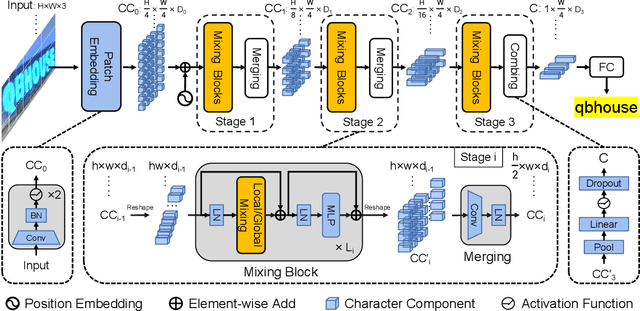

Dominant scene text recognition models commonly contain two building blocks, a visual model for feature extraction and a sequence model for text transcription. This hybrid architecture, although accurate, is complex and less efficient. In this study, we propose a Single Visual model for Scene Text recognition within the patch-wise image tokenization framework, which dispenses with the sequential modeling entirely. The method, termed SVTR, firstly decomposes an image text into small patches named character components. Afterward, hierarchical stages are recurrently carried out by component-level mixing, merging and/or combining. Global and local mixing blocks are devised to perceive the inter-character and intra-character patterns, leading to a multi-grained character component perception. Thus, characters are recognized by a simple linear prediction. Experimental results on both English and Chinese scene text recognition tasks demonstrate the effectiveness of SVTR. SVTR-L (Large) achieves highly competitive accuracy in English and outperforms existing methods by a large margin in Chinese, while running faster. In addition, SVTR-T (Tiny) is an effective and much smaller model, which shows appealing speed at inference. The code is publicly available at https://github.com/PaddlePaddle/PaddleOCR.
* 7pages,6figures
CDistNet: Perceiving Multi-Domain Character Distance for Robust Text Recognition
Nov 25, 2021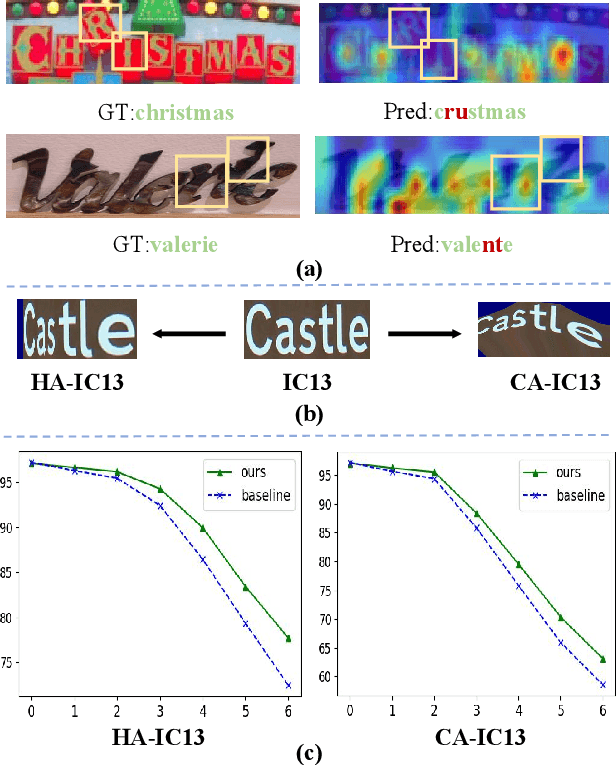
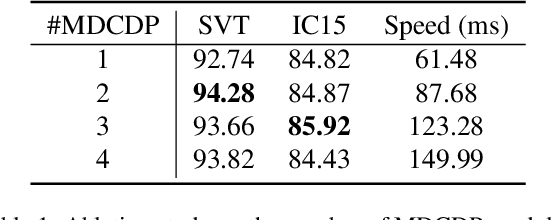
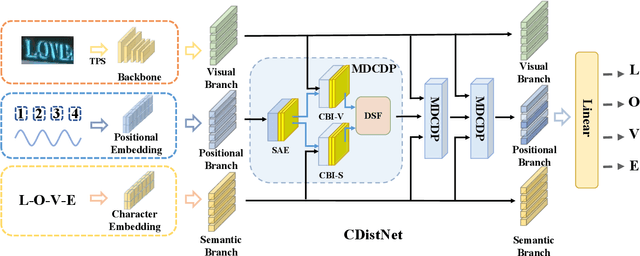
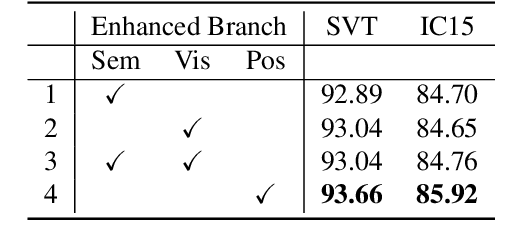
The attention-based encoder-decoder framework is becoming popular in scene text recognition, largely due to its superiority in integrating recognition clues from both visual and semantic domains. However, recent studies show the two clues might be misaligned in the difficult text (e.g., with rare text shapes) and introduce constraints such as character position to alleviate the problem. Despite certain success, a content-free positional embedding hardly associates with meaningful local image regions stably. In this paper, we propose a novel module called Multi-Domain Character Distance Perception (MDCDP) to establish a visual and semantic related position encoding. MDCDP uses positional embedding to query both visual and semantic features following the attention mechanism. It naturally encodes the positional clue, which describes both visual and semantic distances among characters. We develop a novel architecture named CDistNet that stacks MDCDP several times to guide precise distance modeling. Thus, the visual-semantic alignment is well built even various difficulties presented. We apply CDistNet to two augmented datasets and six public benchmarks. The experiments demonstrate that CDistNet achieves state-of-the-art recognition accuracy. While the visualization also shows that CDistNet achieves proper attention localization in both visual and semantic domains. We will release our code upon acceptance.