 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-Resolution Off the Grid
Sep 26, 2015
Super-resolution is the problem of recovering a superposition of point sources using bandlimited measurements, which may be corrupted with noise. This signal processing problem arises in numerous imaging problems, ranging from astronomy to biology to spectroscopy, where it is common to take (coarse) Fourier measurements of an object. Of particular interest is in obtaining estimation procedures which are robust to noise, with the following desirable statistical and computational properties: we seek to use coarse Fourier measurements (bounded by some cutoff frequency); we hope to take a (quantifiably) small number of measurements; we desire our algorithm to run quickly. Suppose we have k point sources in d dimensions, where the points are separated by at least \Delta from each other (in Euclidean distance). This work provides an algorithm with the following favorable guarantees: - The algorithm uses Fourier measurements, whose frequencies are bounded by O(1/\Delta) (up to log factors). Previous algorithms require a cutoff frequency which may be as large as {\Omega}( d/\Delta). - The number of measurements taken by and the computational complexity of our algorithm are bounded by a polynomial in both the number of points k and the dimension d, with no dependence on the separation \Delta. In contrast, previous algorithms depended inverse polynomially on the minimal separation and exponentially on the dimension for both of these quantities. Our estimation procedure itself is simple: we take random bandlimited measurements (as opposed to taking an exponential number of measurements on the hyper-grid). Furthermore, our analysis and algorithm are elementary (based on concentration bounds for sampling and the singular value decomposition).
Un-regularizing: approximate proximal point and faster stochastic algorithms for empirical risk minimization
Jun 24, 2015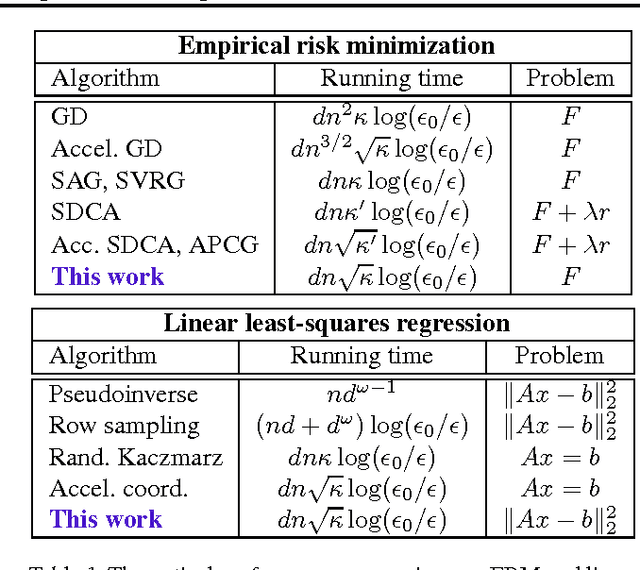
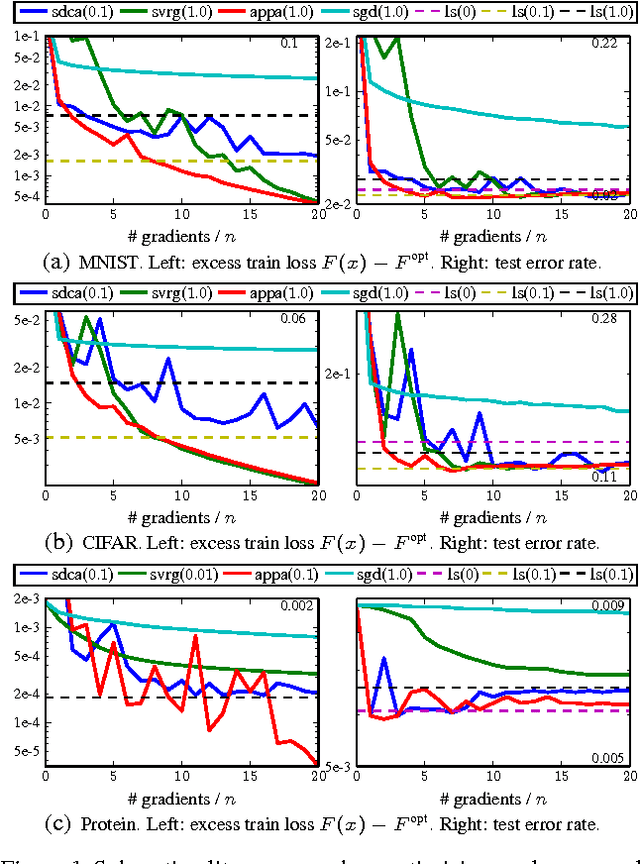
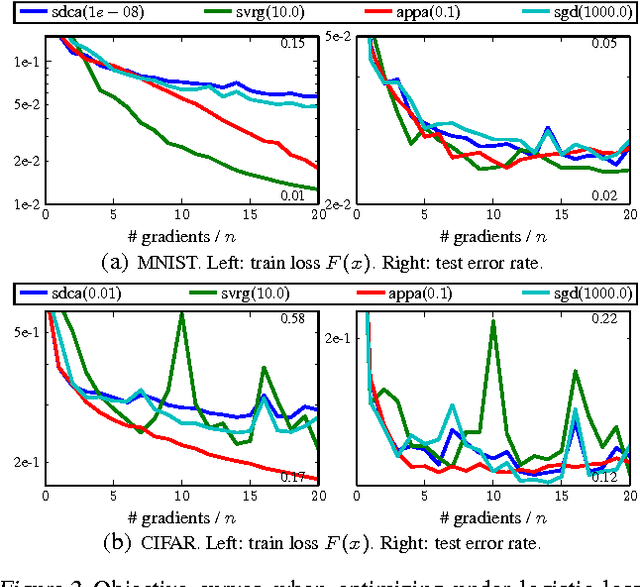
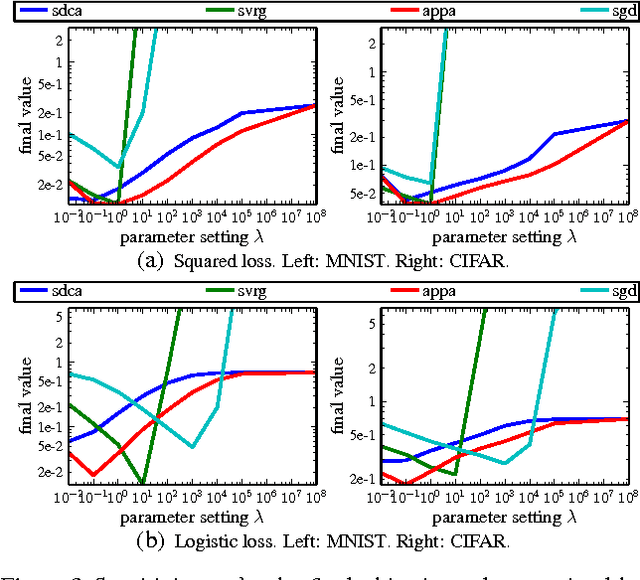
We develop a family of accelerated stochastic algorithms that minimize sums of convex functions. Our algorithms improve upon the fastest running time for empirical risk minimization (ERM), and in particular linear least-squares regression, across a wide range of problem settings. To achieve this, we establish a framework based on the classical proximal point algorithm. Namely, we provide several algorithms that reduce the minimization of a strongly convex function to approximate minimizations of regularizations of the function. Using these results, we accelerate recent fast stochastic algorithms in a black-box fashion. Empirically, we demonstrate that the resulting algorithms exhibit notions of stability that are advantageous in practice. Both in theory and in practice, the provided algorithms reap the computational benefits of adding a large strongly convex regularization term, without incurring a corresponding bias to the original problem.
Learning Exponential Families in High-Dimensions: Strong Convexity and Sparsity
May 16, 2015The versatility of exponential families, along with their attendant convexity properties, make them a popular and effective statistical model. A central issue is learning these models in high-dimensions, such as when there is some sparsity pattern of the optimal parameter. This work characterizes a certain strong convexity property of general exponential families, which allow their generalization ability to be quantified. In particular, we show how this property can be used to analyze generic exponential families under L_1 regularization.
Learning Mixtures of Gaussians in High Dimensions
Mar 10, 2015
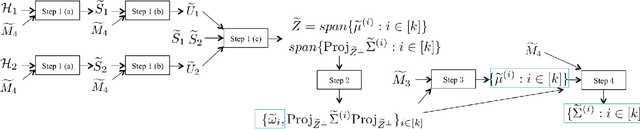
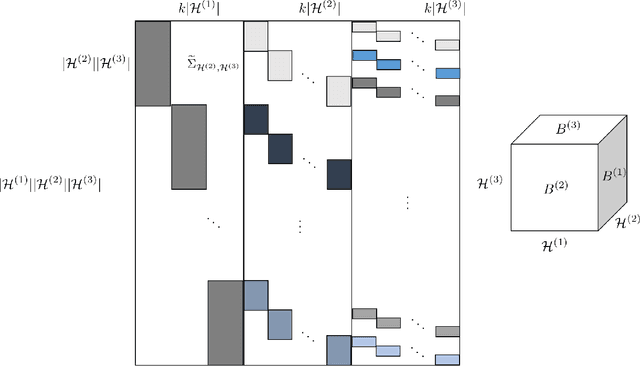
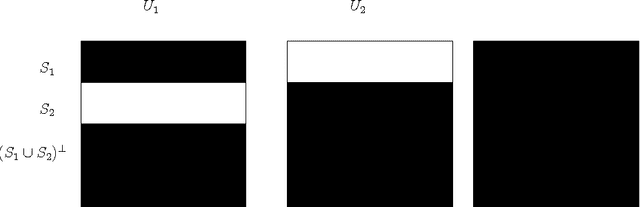
Efficiently learning mixture of Gaussians is a fundamental problem in statistics and learning theory. Given samples coming from a random one out of k Gaussian distributions in Rn, the learning problem asks to estimate the means and the covariance matrices of these Gaussians. This learning problem arises in many areas ranging from the natural sciences to the social sciences, and has also found many machine learning applications. Unfortunately, learning mixture of Gaussians is an information theoretically hard problem: in order to learn the parameters up to a reasonable accuracy, the number of samples required is exponential in the number of Gaussian components in the worst case. In this work, we show that provided we are in high enough dimensions, the class of Gaussian mixtures is learnable in its most general form under a smoothed analysis framework, where the parameters are randomly perturbed from an adversarial starting point. In particular, given samples from a mixture of Gaussians with randomly perturbed parameters, when n > {\Omega}(k^2), we give an algorithm that learns the parameters with polynomial running time and using polynomial number of samples. The central algorithmic ideas consist of new ways to decompose the moment tensor of the Gaussian mixture by exploiting its structural properties. The symmetries of this tensor are derived from the combinatorial structure of higher order moments of Gaussian distributions (sometimes referred to as Isserlis' theorem or Wick's theorem). We also develop new tools for bounding smallest singular values of structured random matrices, which could be useful in other smoothed analysis settings.
Competing with the Empirical Risk Minimizer in a Single Pass
Feb 25, 2015In many estimation problems, e.g. linear and logistic regression, we wish to minimize an unknown objective given only unbiased samples of the objective function. Furthermore, we aim to achieve this using as few samples as possible. In the absence of computational constraints, the minimizer of a sample average of observed data -- commonly referred to as either the empirical risk minimizer (ERM) or the $M$-estimator -- is widely regarded as the estimation strategy of choice due to its desirable statistical convergence properties. Our goal in this work is to perform as well as the ERM, on every problem, while minimizing the use of computational resources such as running time and space usage. We provide a simple streaming algorithm which, under standard regularity assumptions on the underlying problem, enjoys the following properties: * The algorithm can be implemented in linear time with a single pass of the observed data, using space linear in the size of a single sample. * The algorithm achieves the same statistical rate of convergence as the empirical risk minimizer on every problem, even considering constant factors. * The algorithm's performance depends on the initial error at a rate that decreases super-polynomially. * The algorithm is easily parallelizable. Moreover, we quantify the (finite-sample) rate at which the algorithm becomes competitive with the ERM.
Tensor decompositions for learning latent variable models
Nov 13, 2014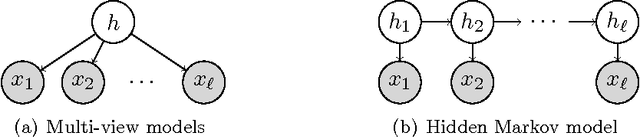
This work considers a computationally and statistically efficient parameter estimation method for a wide class of latent variable models---including Gaussian mixture models, hidden Markov models, and latent Dirichlet allocation---which exploits a certain tensor structure in their low-order observable moments (typically, of second- and third-order). Specifically, parameter estimation is reduced to the problem of extracting a certain (orthogonal) decomposition of a symmetric tensor derived from the moments; this decomposition can be viewed as a natural generalization of the singular value decomposition for matrices. Although tensor decompositions are generally intractable to compute, the decomposition of these specially structured tensors can be efficiently obtained by a variety of approaches, including power iterations and maximization approaches (similar to the case of matrices). A detailed analysis of a robust tensor power method is provided, establishing an analogue of Wedin's perturbation theorem for the singular vectors of matrices. This implies a robust and computationally tractable estimation approach for several popular latent variable models.
Random design analysis of ridge regression
Mar 25, 2014This work gives a simultaneous analysis of both the ordinary least squares estimator and the ridge regression estimator in the random design setting under mild assumptions on the covariate/response distributions. In particular, the analysis provides sharp results on the ``out-of-sample'' prediction error, as opposed to the ``in-sample'' (fixed design) error. The analysis also reveals the effect of errors in the estimated covariance structure, as well as the effect of modeling errors, neither of which effects are present in the fixed design setting. The proofs of the main results are based on a simple decomposition lemma combined with concentration inequalities for random vectors and matrices.
A Tensor Approach to Learning Mixed Membership Community Models
Oct 24, 2013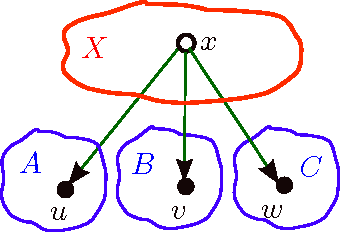
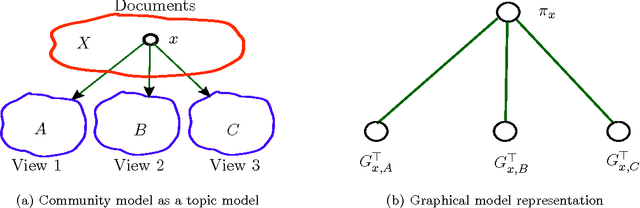
Community detection is the task of detecting hidden communities from observed interactions. Guaranteed community detection has so far been mostly limited to models with non-overlapping communities such as the stochastic block model. In this paper, we remove this restriction, and provide guaranteed community detection for a family of probabilistic network models with overlapping communities, termed as the mixed membership Dirichlet model, first introduced by Airoldi et al. This model allows for nodes to have fractional memberships in multiple communities and assumes that the community memberships are drawn from a Dirichlet distribution. Moreover, it contains the stochastic block model as a special case. We propose a unified approach to learning these models via a tensor spectral decomposition method. Our estimator is based on low-order moment tensor of the observed network, consisting of 3-star counts. Our learning method is fast and is based on simple linear algebraic operations, e.g. singular value decomposition and tensor power iterations. We provide guaranteed recovery of community memberships and model parameters and present a careful finite sample analysis of our learning method. As an important special case, our results match the best known scaling requirements for the (homogeneous) stochastic block model.
Least Squares Revisited: Scalable Approaches for Multi-class Prediction
Oct 21, 2013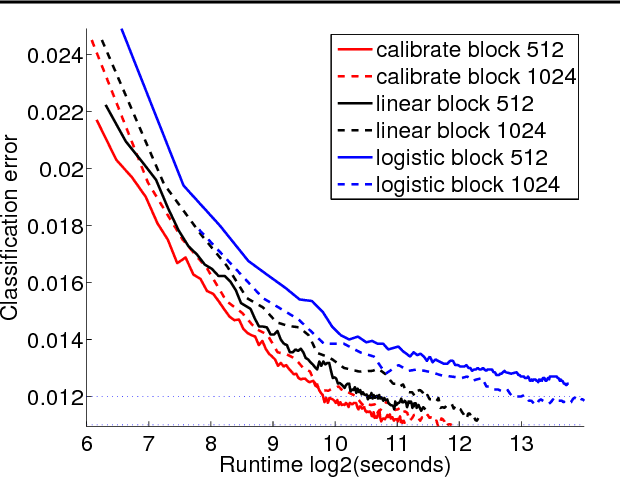

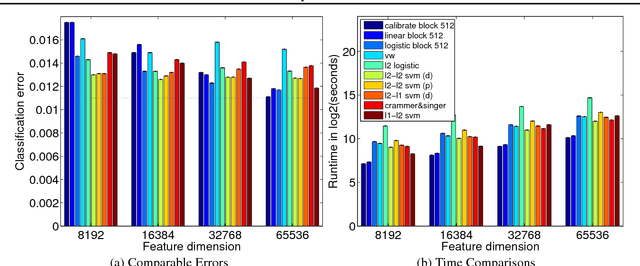
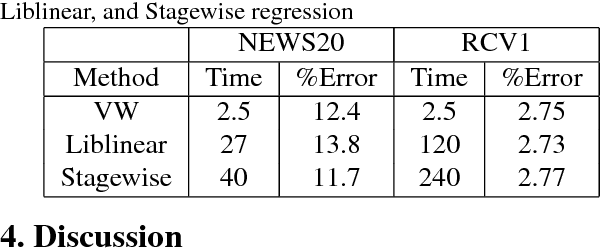
This work provides simple algorithms for multi-class (and multi-label) prediction in settings where both the number of examples n and the data dimension d are relatively large. These robust and parameter free algorithms are essentially iterative least-squares updates and very versatile both in theory and in practice. On the theoretical front, we present several variants with convergence guarantees. Owing to their effective use of second-order structure, these algorithms are substantially better than first-order methods in many practical scenarios. On the empirical side, we present a scalable stagewise variant of our approach, which achieves dramatic computational speedups over popular optimization packages such as Liblinear and Vowpal Wabbit on standard datasets (MNIST and CIFAR-10), while attaining state-of-the-art accuracies.
A Risk Comparison of Ordinary Least Squares vs Ridge Regression
May 31, 2013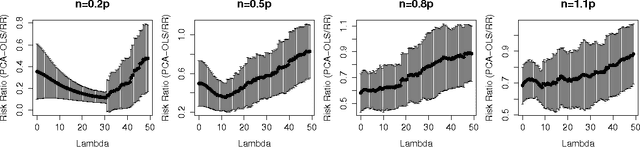
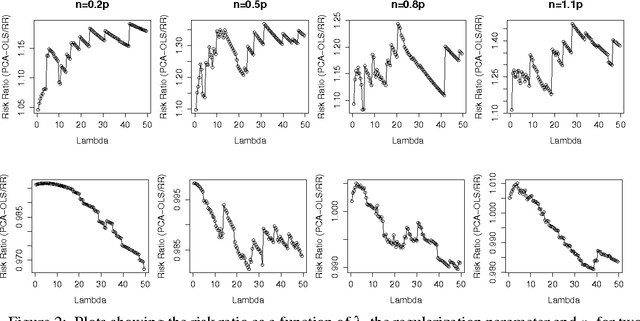
We compare the risk of ridge regression to a simple variant of ordinary least squares, in which one simply projects the data onto a finite dimensional subspace (as specified by a Principal Component Analysis) and then performs an ordinary (un-regularized) least squares regression in this subspace. This note shows that the risk of this ordinary least squares method is within a constant factor (namely 4) of the risk of ridge regression.