 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Causal Prediction for Block MDPs
Mar 12, 2020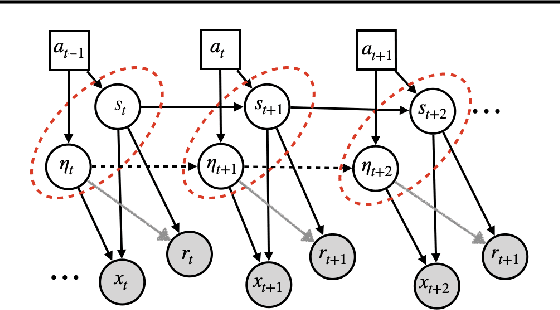
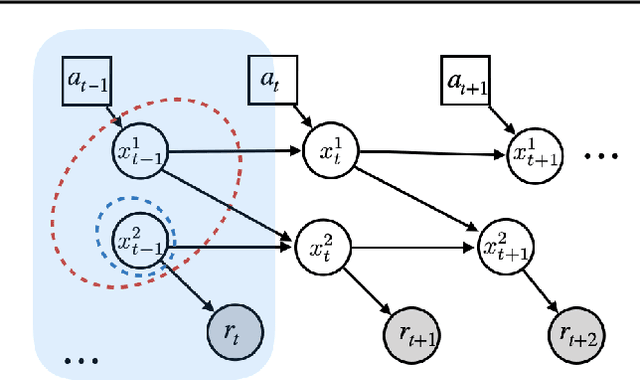
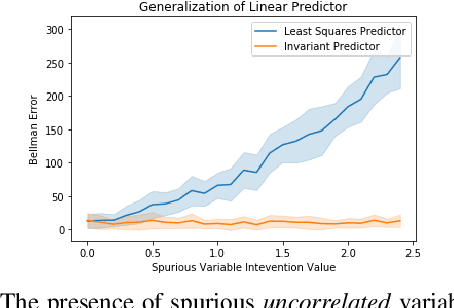
Generalization across environments is critical to the successful application of reinforcement learning algorithms to real-world challenges. In this paper, we consider the problem of learning abstractions that generalize in block MDPs, families of environments with a shared latent state space and dynamics structure over that latent space, but varying observations. We leverage tools from causal inference to propose a method of invariant prediction to learn model-irrelevance state abstractions (MISA) that generalize to novel observations in the multi-environment setting. We prove that for certain classes of environments, this approach outputs with high probability a state abstraction corresponding to the causal feature set with respect to the return. We further provide more general bounds on model error and generalization error in the multi-environment setting, in the process showing a connection between causal variable selection and the state abstraction framework for MDPs. We give empirical evidence that our methods work in both linear and nonlinear settings, attaining improved generalization over single- and multi-task baselines.
Recurrent Independent Mechanisms
Sep 26, 2019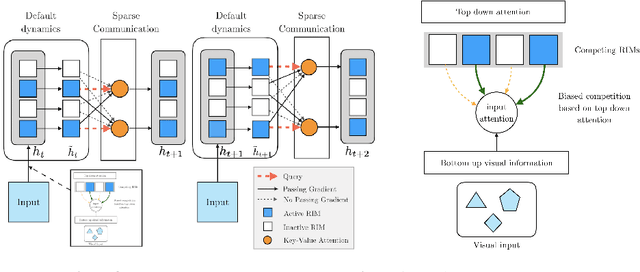
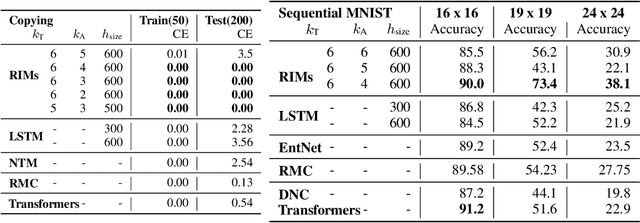
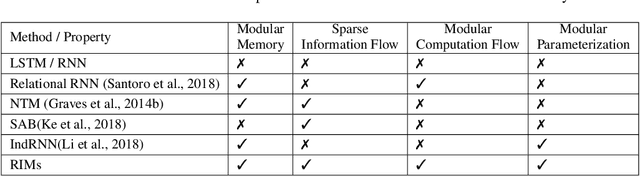

Learning modular structures which reflect the dynamics of the environment can lead to better generalization and robustness to changes which only affect a few of the underlying causes. We propose Recurrent Independent Mechanisms (RIMs), a new recurrent architecture in which multiple groups of recurrent cells operate with nearly independent transition dynamics, communicate only sparingly through the bottleneck of attention, and are only updated at time steps where they are most relevant. We show that this leads to specialization amongst the RIMs, which in turn allows for dramatically improved generalization on tasks where some factors of variation differ systematically between training and evaluation.
CLUTRR: A Diagnostic Benchmark for Inductive Reasoning from Text
Sep 04, 2019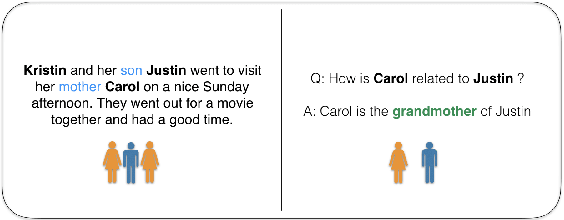
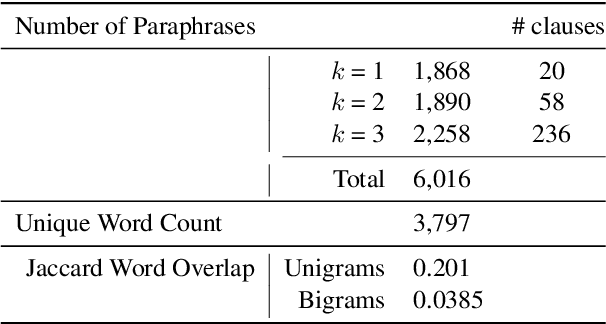
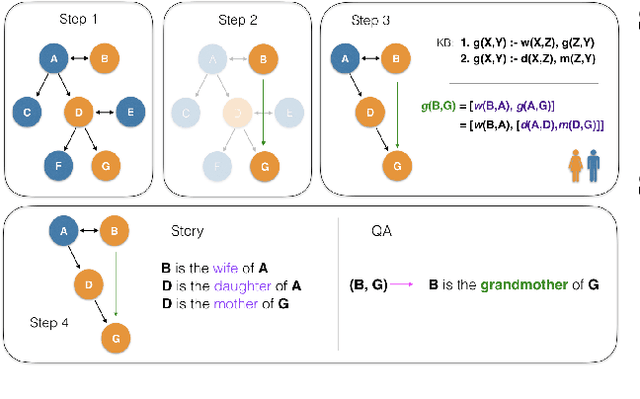
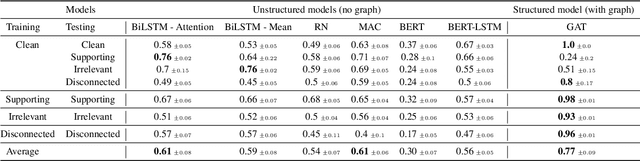
The recent success of natural language understanding (NLU) systems has been troubled by results highlighting the failure of these models to generalize in a systematic and robust way. In this work, we introduce a diagnostic benchmark suite, named CLUTRR, to clarify some key issues related to the robustness and systematicity of NLU systems. Motivated by classic work on inductive logic programming, CLUTRR requires that an NLU system infer kinship relations between characters in short stories. Successful performance on this task requires both extracting relationships between entities, as well as inferring the logical rules governing these relationships. CLUTRR allows us to precisely measure a model's ability for systematic generalization by evaluating on held-out combinations of logical rules, and it allows us to evaluate a model's robustness by adding curated noise facts. Our empirical results highlight a substantial performance gap between state-of-the-art NLU models (e.g., BERT and MAC) and a graph neural network model that works directly with symbolic inputs---with the graph-based model exhibiting both stronger generalization and greater robustness.
Reinforcement Learning with Competitive Ensembles of Information-Constrained Primitives
Jun 25, 2019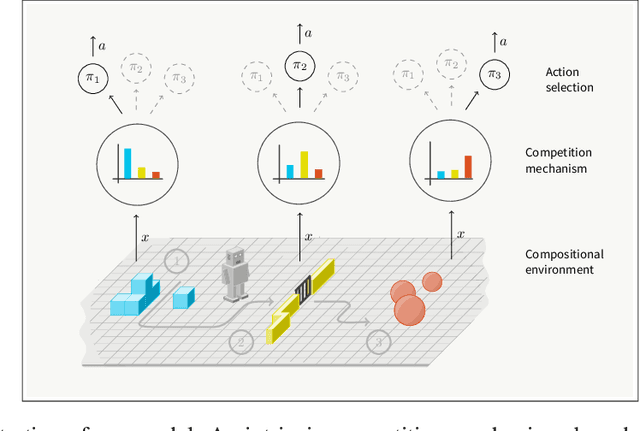

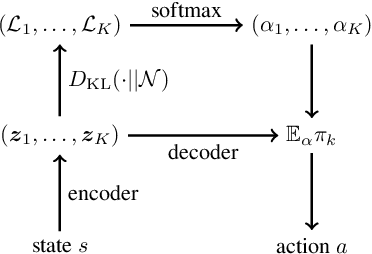
Reinforcement learning agents that operate in diverse and complex environments can benefit from the structured decomposition of their behavior. Often, this is addressed in the context of hierarchical reinforcement learning, where the aim is to decompose a policy into lower-level primitives or options, and a higher-level meta-policy that triggers the appropriate behaviors for a given situation. However, the meta-policy must still produce appropriate decisions in all states. In this work, we propose a policy design that decomposes into primitives, similarly to hierarchical reinforcement learning, but without a high-level meta-policy. Instead, each primitive can decide for themselves whether they wish to act in the current state. We use an information-theoretic mechanism for enabling this decentralized decision: each primitive chooses how much information it needs about the current state to make a decision and the primitive that requests the most information about the current state acts in the world. The primitives are regularized to use as little information as possible, which leads to natural competition and specialization. We experimentally demonstrate that this policy architecture improves over both flat and hierarchical policies in terms of generalization.
Learning Powerful Policies by Using Consistent Dynamics Model
Jun 11, 2019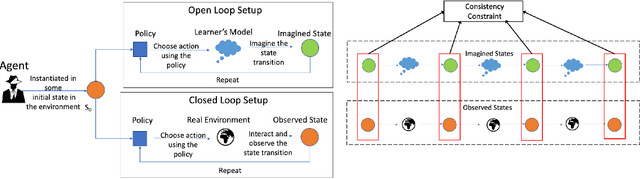
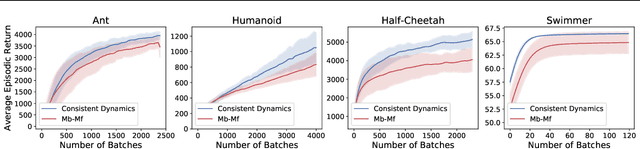
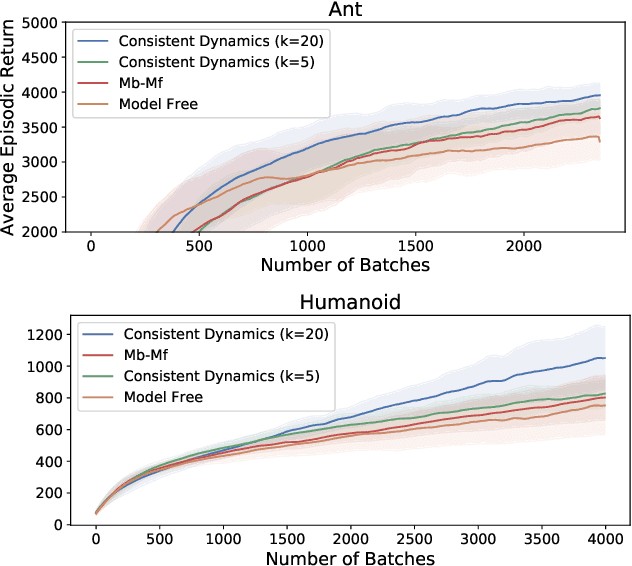
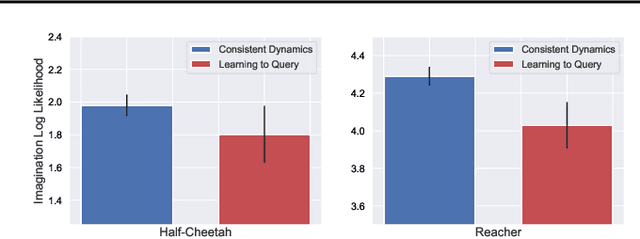
Model-based Reinforcement Learning approaches have the promise of being sample efficient. Much of the progress in learning dynamics models in RL has been made by learning models via supervised learning. But traditional model-based approaches lead to `compounding errors' when the model is unrolled step by step. Essentially, the state transitions that the learner predicts (by unrolling the model for multiple steps) and the state transitions that the learner experiences (by acting in the environment) may not be consistent. There is enough evidence that humans build a model of the environment, not only by observing the environment but also by interacting with the environment. Interaction with the environment allows humans to carry out experiments: taking actions that help uncover true causal relationships which can be used for building better dynamics models. Analogously, we would expect such interactions to be helpful for a learning agent while learning to model the environment dynamics. In this paper, we build upon this intuition by using an auxiliary cost function to ensure consistency between what the agent observes (by acting in the real world) and what it imagines (by acting in the `learned' world). We consider several tasks - Mujoco based control tasks and Atari games - and show that the proposed approach helps to train powerful policies and better dynamics models.
Environments for Lifelong Reinforcement Learning
Dec 06, 2018To achieve general artificial intelligence, reinforcement learning (RL) agents should learn not only to optimize returns for one specific task but also to constantly build more complex skills and scaffold their knowledge about the world, without forgetting what has already been learned. In this paper, we discuss the desired characteristics of environments that can support the training and evaluation of lifelong reinforcement learning agents, review existing environments from this perspective, and propose recommendations for devising suitable environments in the future.
On Training Recurrent Neural Networks for Lifelong Learning
Nov 16, 2018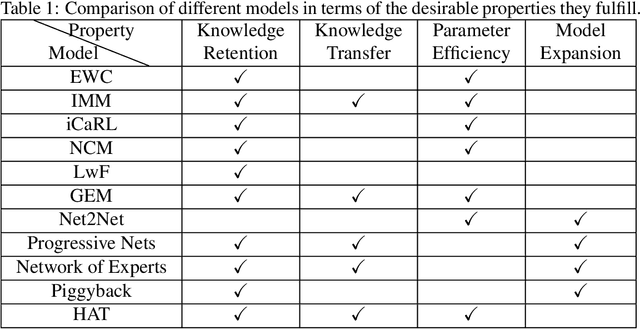
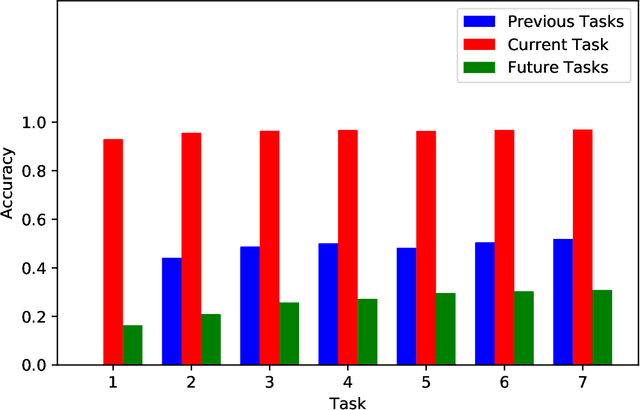

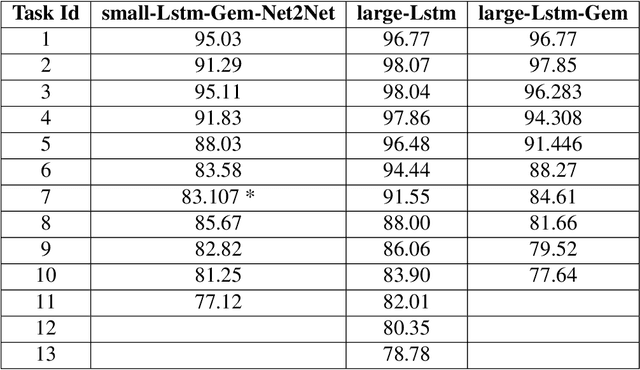
Capacity saturation and catastrophic forgetting are the central challenges of any parametric lifelong learning system. In this work, we study these challenges in the context of sequential supervised learning with emphasis on recurrent neural networks. To evaluate the models in life-long learning setting, we propose a curriculum-based, simple, and intuitive benchmark where the models are trained on a task with increasing levels of difficulty. As a step towards developing true lifelong learning systems, we unify Gradient Episodic Memory (a catastrophic forgetting alleviation approach) and Net2Net (a capacity expansion approach). Evaluation on the proposed benchmark shows that the unified model is more suitable than the constituent models for lifelong learning setting.
Compositional Language Understanding with Text-based Relational Reasoning
Nov 08, 2018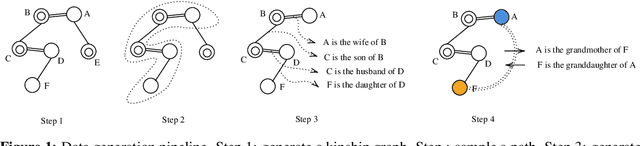

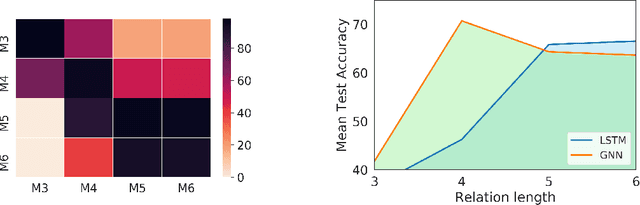

Neural networks for natural language reasoning have largely focused on extractive, fact-based question-answering (QA) and common-sense inference. However, it is also crucial to understand the extent to which neural networks can perform relational reasoning and combinatorial generalization from natural language---abilities that are often obscured by annotation artifacts and the dominance of language modeling in standard QA benchmarks. In this work, we present a novel benchmark dataset for language understanding that isolates performance on relational reasoning. We also present a neural message-passing baseline and show that this model, which incorporates a relational inductive bias, is superior at combinatorial generalization compared to a traditional recurrent neural network approach.
Improving Search through A3C Reinforcement Learning based Conversational Agent
Aug 19, 2018


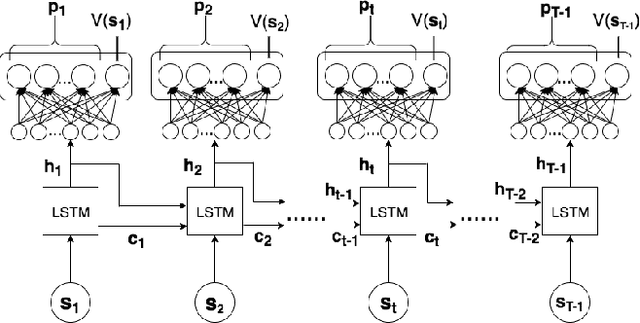
We develop a reinforcement learning based search assistant which can assist users through a set of actions and sequence of interactions to enable them realize their intent. Our approach caters to subjective search where the user is seeking digital assets such as images which is fundamentally different from the tasks which have objective and limited search modalities. Labeled conversational data is generally not available in such search tasks and training the agent through human interactions can be time consuming. We propose a stochastic virtual user which impersonates a real user and can be used to sample user behavior efficiently to train the agent which accelerates the bootstrapping of the agent. We develop A3C algorithm based context preserving architecture which enables the agent to provide contextual assistance to the user. We compare the A3C agent with Q-learning and evaluate its performance on average rewards and state values it obtains with the virtual user in validation episodes. Our experiments show that the agent learns to achieve higher rewards and better states.
Memory Augmented Self-Play
Jun 01, 2018
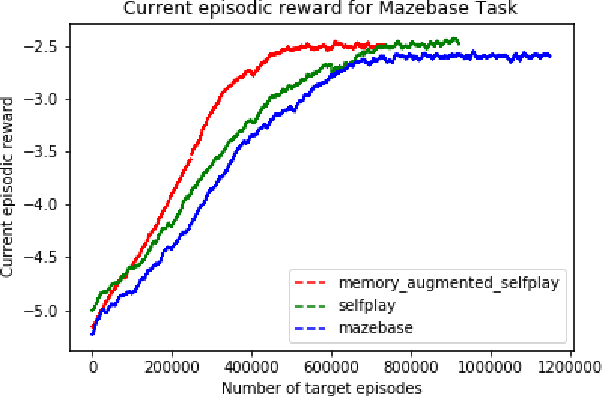
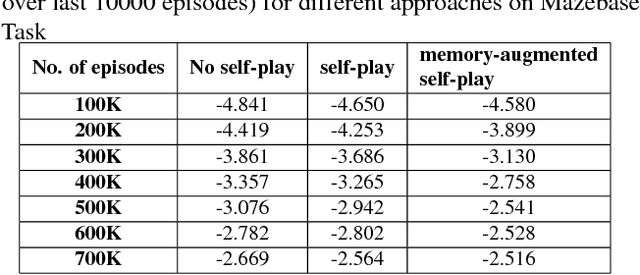
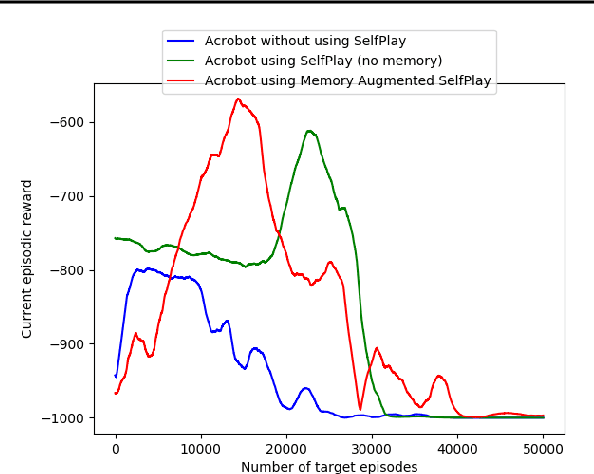
Self-play is an unsupervised training procedure which enables the reinforcement learning agents to explore the environment without requiring any external rewards. We augment the self-play setting by providing an external memory where the agent can store experience from the previous tasks. This enables the agent to come up with more diverse self-play tasks resulting in faster exploration of the environment. The agent pretrained in the memory augmented self-play setting easily outperforms the agent pretrained in no-memory self-play setting.