 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiterature-Augmented Clinical Outcome Prediction
Nov 16, 2021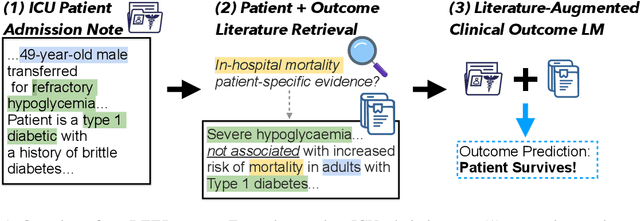
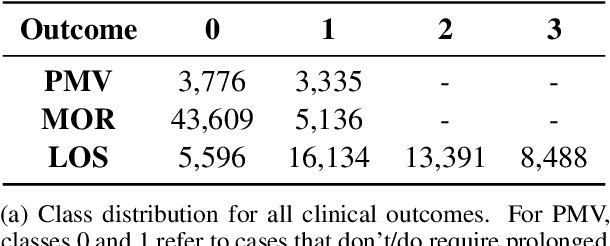
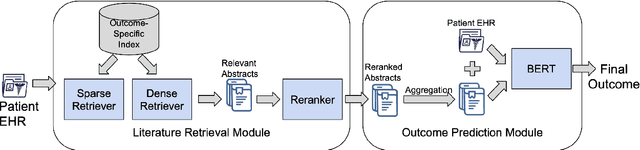
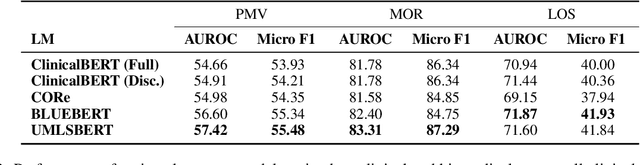
Predictive models for medical outcomes hold great promise for enhancing clinical decision-making. These models are trained on rich patient data such as clinical notes, aggregating many patient signals into an outcome prediction. However, AI-based clinical models have typically been developed in isolation from the prominent paradigm of Evidence Based Medicine (EBM), in which medical decisions are based on explicit evidence from existing literature. In this work, we introduce techniques to help bridge this gap between EBM and AI-based clinical models, and show that these methods can improve predictive accuracy. We propose a novel system that automatically retrieves patient-specific literature based on intensive care (ICU) patient information, aggregates relevant papers and fuses them with internal admission notes to form outcome predictions. Our model is able to substantially boost predictive accuracy on three challenging tasks in comparison to strong recent baselines; for in-hospital mortality, we are able to boost top-10% precision by a large margin of over 25%.
Overview of the TREC 2020 Fair Ranking Track
Aug 11, 2021

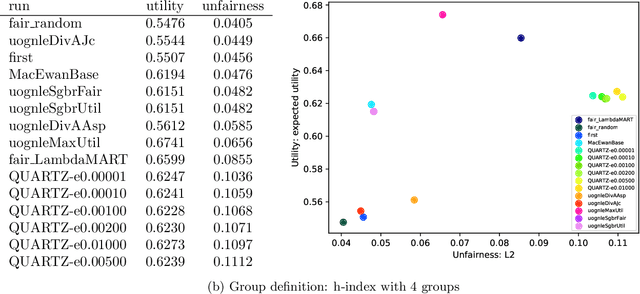
This paper provides an overview of the NIST TREC 2020 Fair Ranking track. For 2020, we again adopted an academic search task, where we have a corpus of academic article abstracts and queries submitted to a production academic search engine. The central goal of the Fair Ranking track is to provide fair exposure to different groups of authors (a group fairness framing). We recognize that there may be multiple group definitions (e.g. based on demographics, stature, topic) and hoped for the systems to be robust to these. We expected participants to develop systems that optimize for fairness and relevance for arbitrary group definitions, and did not reveal the exact group definitions until after the evaluation runs were submitted.The track contains two tasks,reranking and retrieval, with a shared evaluation.
Simplified Data Wrangling with ir_datasets
Mar 03, 2021


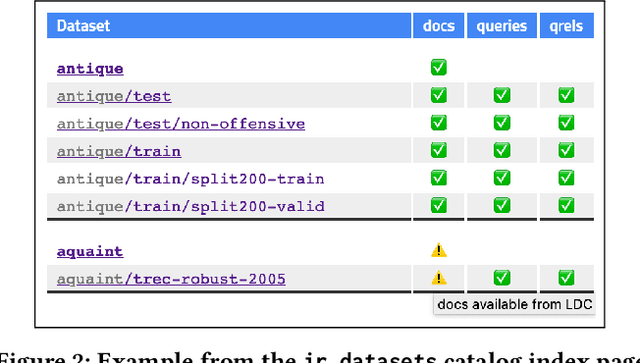
Managing the data for Information Retrieval (IR) experiments can be challenging. Dataset documentation is scattered across the Internet and once one obtains a copy of the data, there are numerous different data formats to work with. Even basic formats can have subtle dataset-specific nuances that need to be considered for proper use. To help mitigate these challenges, we introduce a new robust and lightweight tool (ir_datases) for acquiring, managing, and performing typical operations over datasets used in IR. We primarily focus on textual datasets used for ad-hoc search. This tool provides both a python and command line interface to numerous IR datasets and benchmarks. To our knowledge, this is the most extensive tool of its kind. Integrations with popular IR indexing and experimentation toolkits demonstrate the tool's utility. We also provide documentation of these datasets through the ir_datasets catalog: https://ir-datasets.com/. The catalog acts as a hub for information on datasets used in IR, providing core information about what data each benchmark provides as well as links to more detailed information. We welcome community contributions and intend to continue to maintain and grow this tool.
ABNIRML: Analyzing the Behavior of Neural IR Models
Nov 02, 2020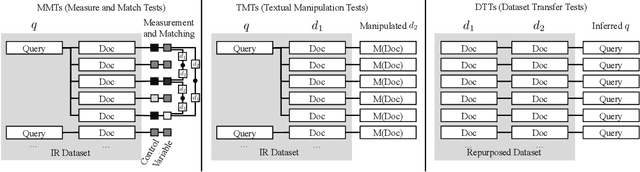
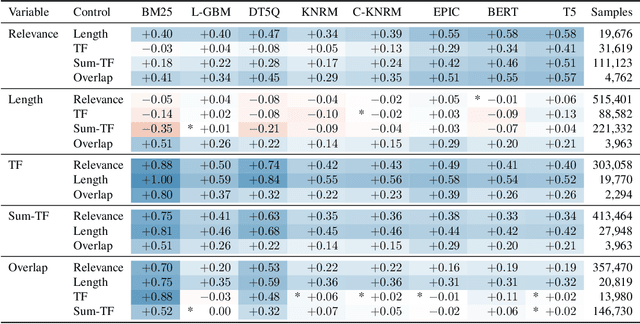
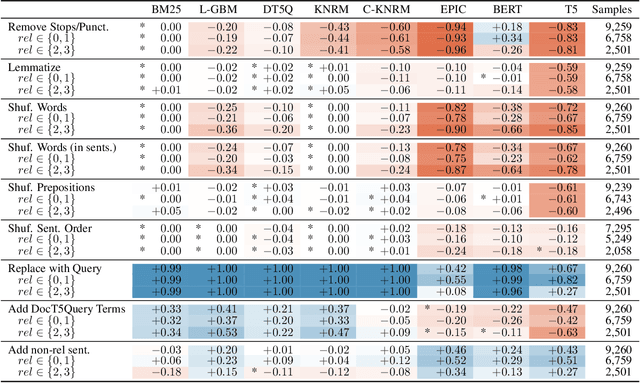
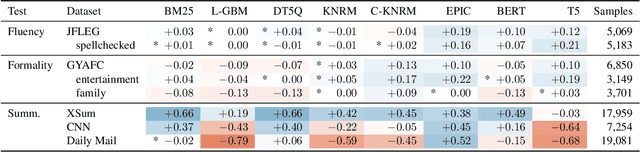
Numerous studies have demonstrated the effectiveness of pretrained contextualized language models such as BERT and T5 for ad-hoc search. However, it is not well-understood why these methods are so effective, what makes some variants more effective than others, and what pitfalls they may have. We present a new comprehensive framework for Analyzing the Behavior of Neural IR ModeLs (ABNIRML), which includes new types of diagnostic tests that allow us to probe several characteristics---such as sensitivity to word order---that are not addressed by previous techniques. To demonstrate the value of the framework, we conduct an extensive empirical study that yields insights into the factors that contribute to the neural model's gains, and identify potential unintended biases the models exhibit. We find evidence that recent neural ranking models have fundamentally different characteristics from prior ranking models. For instance, these models can be highly influenced by altered document word order, sentence order and inflectional endings. They can also exhibit unexpected behaviors when additional content is added to documents, or when documents are expressed with different levels of fluency or formality. We find that these differences can depend on the architecture and not just the underlying language model.
SPECTER: Document-level Representation Learning using Citation-informed Transformers
May 20, 2020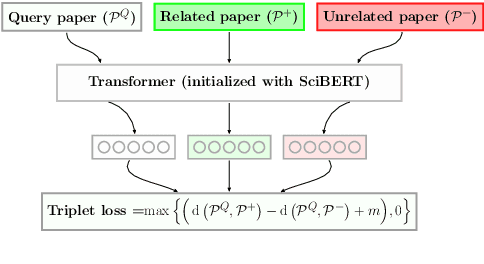
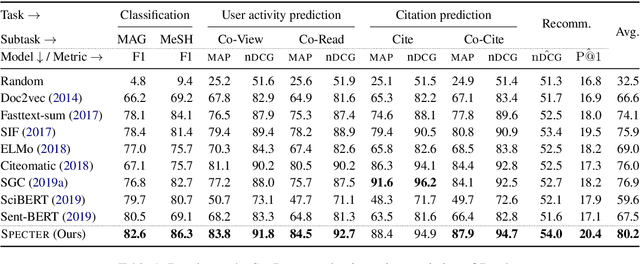
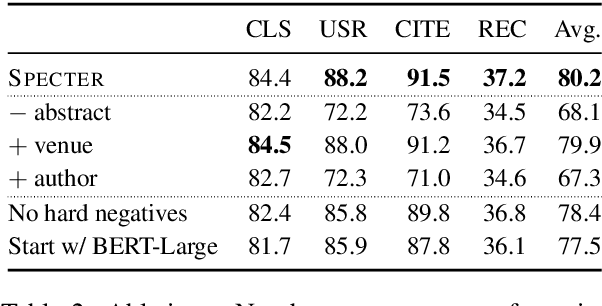

Representation learning is a critical ingredient for natural language processing systems. Recent Transformer language models like BERT learn powerful textual representations, but these models are targeted towards token- and sentence-level training objectives and do not leverage information on inter-document relatedness, which limits their document-level representation power. For applications on scientific documents, such as classification and recommendation, the embeddings power strong performance on end tasks. We propose SPECTER, a new method to generate document-level embedding of scientific documents based on pretraining a Transformer language model on a powerful signal of document-level relatedness: the citation graph. Unlike existing pretrained language models, SPECTER can be easily applied to downstream applications without task-specific fine-tuning. Additionally, to encourage further research on document-level models, we introduce SciDocs, a new evaluation benchmark consisting of seven document-level tasks ranging from citation prediction, to document classification and recommendation. We show that SPECTER outperforms a variety of competitive baselines on the benchmark.
Construction of the Literature Graph in Semantic Scholar
May 06, 2018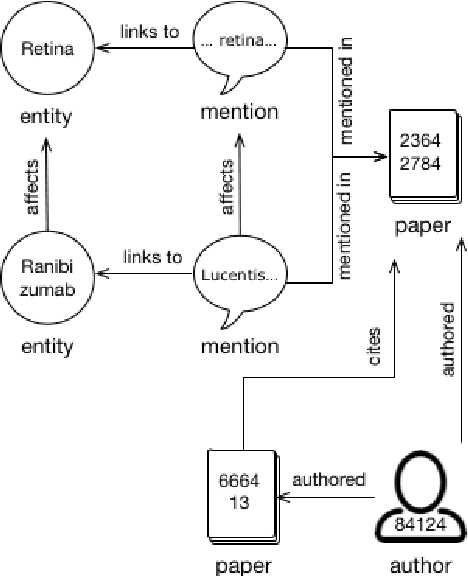
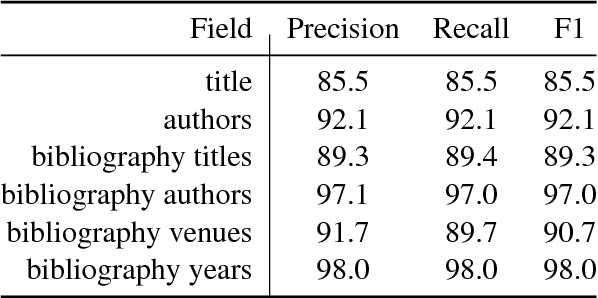
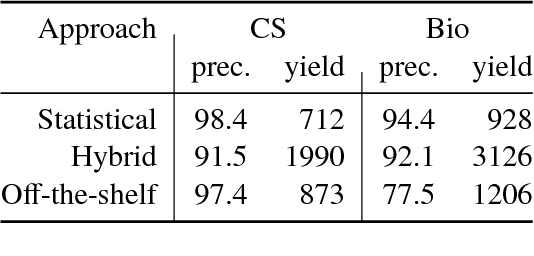

We describe a deployed scalable system for organizing published scientific literature into a heterogeneous graph to facilitate algorithmic manipulation and discovery. The resulting literature graph consists of more than 280M nodes, representing papers, authors, entities and various interactions between them (e.g., authorships, citations, entity mentions). We reduce literature graph construction into familiar NLP tasks (e.g., entity extraction and linking), point out research challenges due to differences from standard formulations of these tasks, and report empirical results for each task. The methods described in this paper are used to enable semantic features in www.semanticscholar.org
Content-Based Citation Recommendation
Feb 22, 2018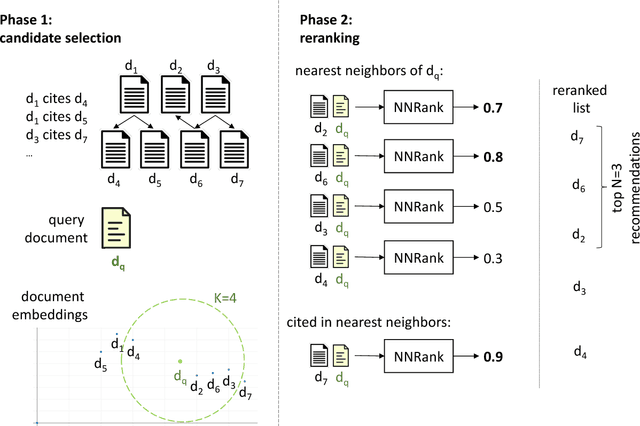
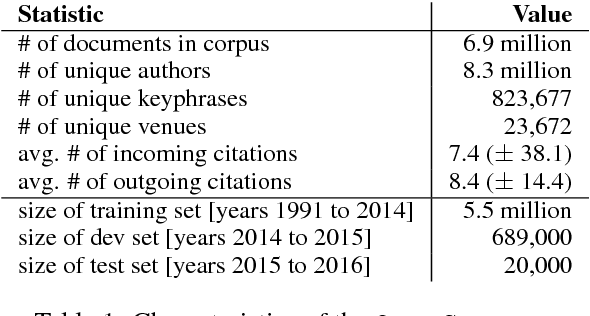
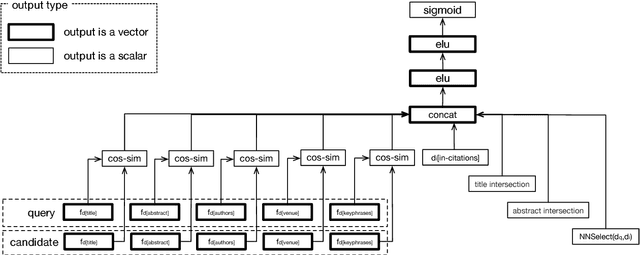
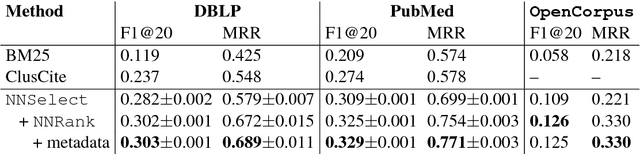
We present a content-based method for recommending citations in an academic paper draft. We embed a given query document into a vector space, then use its nearest neighbors as candidates, and rerank the candidates using a discriminative model trained to distinguish between observed and unobserved citations. Unlike previous work, our method does not require metadata such as author names which can be missing, e.g., during the peer review process. Without using metadata, our method outperforms the best reported results on PubMed and DBLP datasets with relative improvements of over 18% in F1@20 and over 22% in MRR. We show empirically that, although adding metadata improves the performance on standard metrics, it favors self-citations which are less useful in a citation recommendation setup. We release an online portal (http://labs.semanticscholar.org/citeomatic/) for citation recommendation based on our method, and a new dataset OpenCorpus of 7 million research articles to facilitate future research on this task.
Multi-Task Averaging
Aug 24, 2012
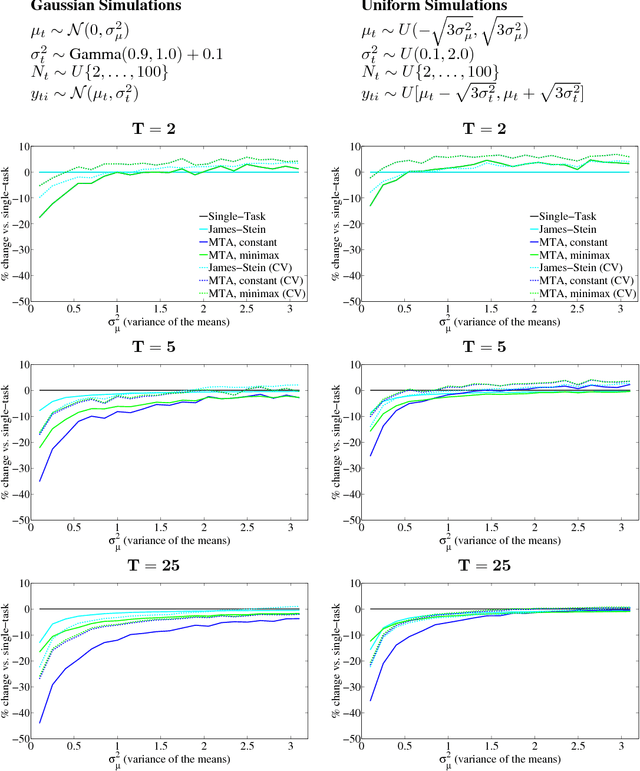
We present a multi-task learning approach to jointly estimate the means of multiple independent data sets. The proposed multi-task averaging (MTA) algorithm results in a convex combination of the single-task maximum likelihood estimates. We derive the optimal minimum risk estimator and the minimax estimator, and show that these estimators can be efficiently estimated. Simulations and real data experiments demonstrate that MTA estimators often outperform both single-task and James-Stein estimators.