 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-HPC: Generating Synthetic Images with Realistic Humans
Mar 16, 2023Recent text-to-image generative models have exhibited remarkable abilities in generating high-fidelity and photo-realistic images. However, despite the visually impressive results, these models often struggle to preserve plausible human structure in the generations. Due to this reason, while generative models have shown promising results in aiding downstream image recognition tasks by generating large volumes of synthetic data, they remain infeasible for improving downstream human pose perception and understanding. In this work, we propose Diffusion model with Human Pose Correction (Diffusion HPC), a text-conditioned method that generates photo-realistic images with plausible posed humans by injecting prior knowledge about human body structure. We show that Diffusion HPC effectively improves the realism of human generations. Furthermore, as the generations are accompanied by 3D meshes that serve as ground truths, Diffusion HPC's generated image-mesh pairs are well-suited for downstream human mesh recovery task, where a shortage of 3D training data has long been an issue.
Diagnosing and Rectifying Vision Models using Language
Feb 08, 2023



Recent multi-modal contrastive learning models have demonstrated the ability to learn an embedding space suitable for building strong vision classifiers, by leveraging the rich information in large-scale image-caption datasets. Our work highlights a distinct advantage of this multi-modal embedding space: the ability to diagnose vision classifiers through natural language. The traditional process of diagnosing model behaviors in deployment settings involves labor-intensive data acquisition and annotation. Our proposed method can discover high-error data slices, identify influential attributes and further rectify undesirable model behaviors, without requiring any visual data. Through a combination of theoretical explanation and empirical verification, we present conditions under which classifiers trained on embeddings from one modality can be equivalently applied to embeddings from another modality. On a range of image datasets with known error slices, we demonstrate that our method can effectively identify the error slices and influential attributes, and can further use language to rectify failure modes of the classifier.
Adapting Pre-trained Vision Transformers from 2D to 3D through Weight Inflation Improves Medical Image Segmentation
Feb 08, 2023Given the prevalence of 3D medical imaging technologies such as MRI and CT that are widely used in diagnosing and treating diverse diseases, 3D segmentation is one of the fundamental tasks of medical image analysis. Recently, Transformer-based models have started to achieve state-of-the-art performances across many vision tasks, through pre-training on large-scale natural image benchmark datasets. While works on medical image analysis have also begun to explore Transformer-based models, there is currently no optimal strategy to effectively leverage pre-trained Transformers, primarily due to the difference in dimensionality between 2D natural images and 3D medical images. Existing solutions either split 3D images into 2D slices and predict each slice independently, thereby losing crucial depth-wise information, or modify the Transformer architecture to support 3D inputs without leveraging pre-trained weights. In this work, we use a simple yet effective weight inflation strategy to adapt pre-trained Transformers from 2D to 3D, retaining the benefit of both transfer learning and depth information. We further investigate the effectiveness of transfer from different pre-training sources and objectives. Our approach achieves state-of-the-art performances across a broad range of 3D medical image datasets, and can become a standard strategy easily utilized by all work on Transformer-based models for 3D medical images, to maximize performance.
NeMo: 3D Neural Motion Fields from Multiple Video Instances of the Same Action
Dec 28, 2022The task of reconstructing 3D human motion has wideranging applications. The gold standard Motion capture (MoCap) systems are accurate but inaccessible to the general public due to their cost, hardware and space constraints. In contrast, monocular human mesh recovery (HMR) methods are much more accessible than MoCap as they take single-view videos as inputs. Replacing the multi-view Mo- Cap systems with a monocular HMR method would break the current barriers to collecting accurate 3D motion thus making exciting applications like motion analysis and motiondriven animation accessible to the general public. However, performance of existing HMR methods degrade when the video contains challenging and dynamic motion that is not in existing MoCap datasets used for training. This reduces its appeal as dynamic motion is frequently the target in 3D motion recovery in the aforementioned applications. Our study aims to bridge the gap between monocular HMR and multi-view MoCap systems by leveraging information shared across multiple video instances of the same action. We introduce the Neural Motion (NeMo) field. It is optimized to represent the underlying 3D motions across a set of videos of the same action. Empirically, we show that NeMo can recover 3D motion in sports using videos from the Penn Action dataset, where NeMo outperforms existing HMR methods in terms of 2D keypoint detection. To further validate NeMo using 3D metrics, we collected a small MoCap dataset mimicking actions in Penn Action,and show that NeMo achieves better 3D reconstruction compared to various baselines.
PROB: Probabilistic Objectness for Open World Object Detection
Dec 02, 2022



Open World Object Detection (OWOD) is a new and challenging computer vision task that bridges the gap between classic object detection (OD) benchmarks and object detection in the real world. In addition to detecting and classifying seen/labeled objects, OWOD algorithms are expected to detect novel/unknown objects - which can be classified and incrementally learned. In standard OD, object proposals not overlapping with a labeled object are automatically classified as background. Therefore, simply applying OD methods to OWOD fails as unknown objects would be predicted as background. The challenge of detecting unknown objects stems from the lack of supervision in distinguishing unknown objects and background object proposals. Previous OWOD methods have attempted to overcome this issue by generating supervision using pseudo-labeling - however, unknown object detection has remained low. Probabilistic/generative models may provide a solution for this challenge. Herein, we introduce a novel probabilistic framework for objectness estimation, where we alternate between probability distribution estimation and objectness likelihood maximization of known objects in the embedded feature space - ultimately allowing us to estimate the objectness probability of different proposals. The resulting Probabilistic Objectness transformer-based open-world detector, PROB, integrates our framework into traditional object detection models, adapting them for the open-world setting. Comprehensive experiments on OWOD benchmarks show that PROB outperforms all existing OWOD methods in both unknown object detection ($\sim 2\times$ unknown recall) and known object detection ($\sim 10\%$ mAP). Our code will be made available upon publication at https://github.com/orrzohar/PROB.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022
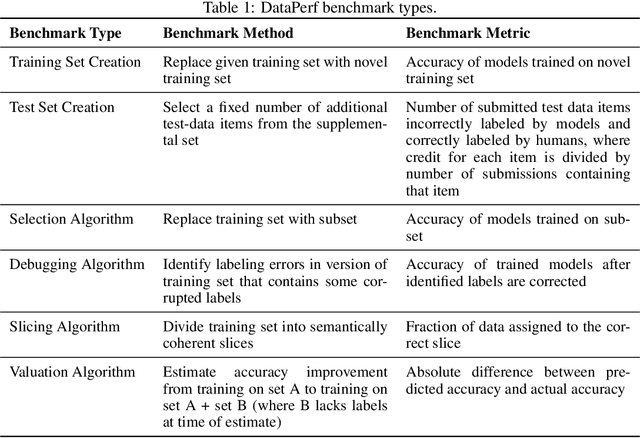
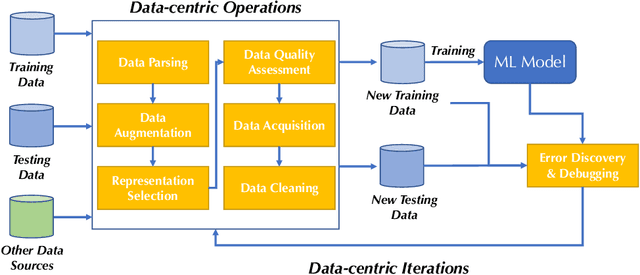
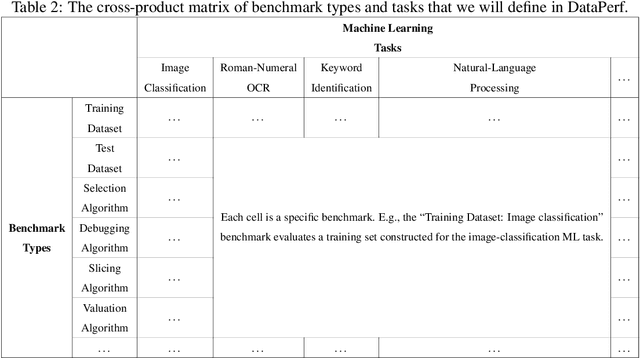
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
Adaptation of Surgical Activity Recognition Models Across Operating Rooms
Jul 07, 2022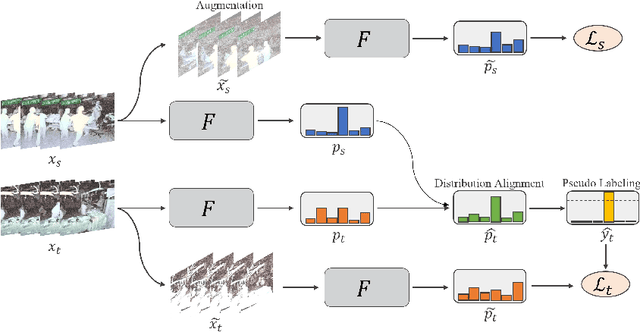

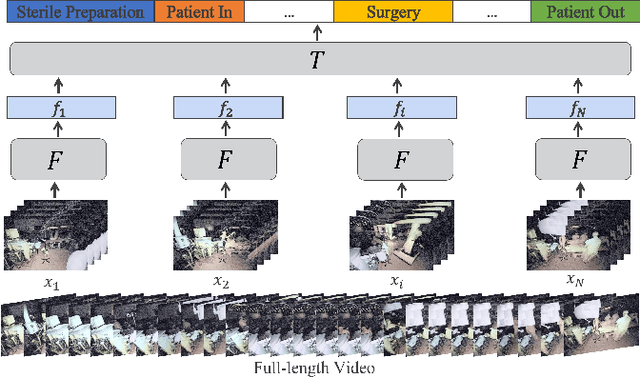

Automatic surgical activity recognition enables more intelligent surgical devices and a more efficient workflow. Integration of such technology in new operating rooms has the potential to improve care delivery to patients and decrease costs. Recent works have achieved a promising performance on surgical activity recognition; however, the lack of generalizability of these models is one of the critical barriers to the wide-scale adoption of this technology. In this work, we study the generalizability of surgical activity recognition models across operating rooms. We propose a new domain adaptation method to improve the performance of the surgical activity recognition model in a new operating room for which we only have unlabeled videos. Our approach generates pseudo labels for unlabeled video clips that it is confident about and trains the model on the augmented version of the clips. We extend our method to a semi-supervised domain adaptation setting where a small portion of the target domain is also labeled. In our experiments, our proposed method consistently outperforms the baselines on a dataset of more than 480 long surgical videos collected from two operating rooms.
Domain Adaptive 3D Pose Augmentation for In-the-wild Human Mesh Recovery
Jun 21, 2022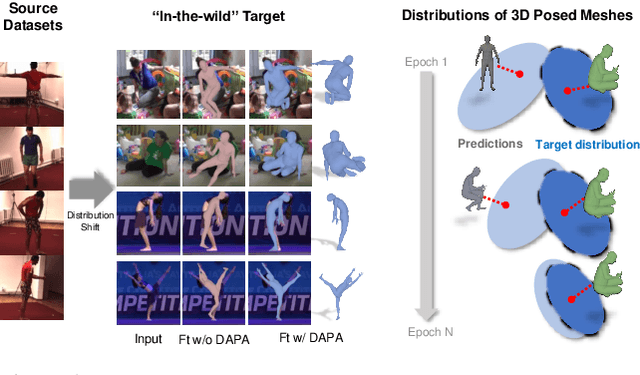
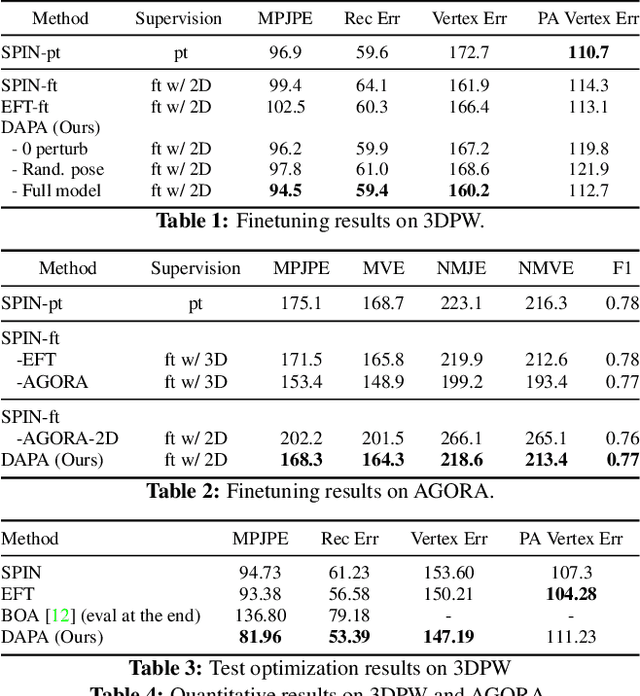
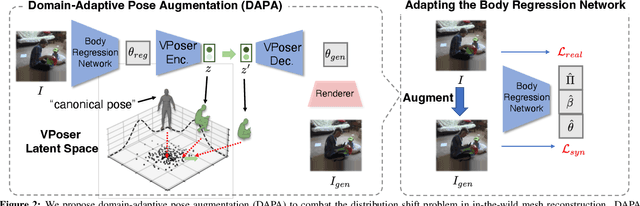

The ability to perceive 3D human bodies from a single image has a multitude of applications ranging from entertainment and robotics to neuroscience and healthcare. A fundamental challenge in human mesh recovery is in collecting the ground truth 3D mesh targets required for training, which requires burdensome motion capturing systems and is often limited to indoor laboratories. As a result, while progress is made on benchmark datasets collected in these restrictive settings, models fail to generalize to real-world ``in-the-wild'' scenarios due to distribution shifts. We propose Domain Adaptive 3D Pose Augmentation (DAPA), a data augmentation method that enhances the model's generalization ability in in-the-wild scenarios. DAPA combines the strength of methods based on synthetic datasets by getting direct supervision from the synthesized meshes, and domain adaptation methods by using ground truth 2D keypoints from the target dataset. We show quantitatively that finetuning with DAPA effectively improves results on benchmarks 3DPW and AGORA. We further demonstrate the utility of DAPA on a challenging dataset curated from videos of real-world parent-child interaction.
Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning
Mar 03, 2022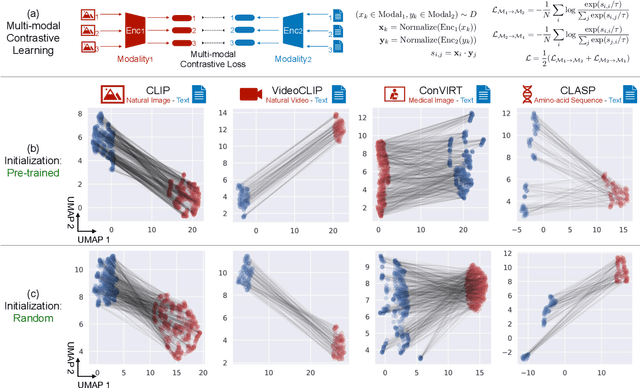

We present modality gap, an intriguing geometric phenomenon of the representation space of multi-modal models. Specifically, we show that different data modalities (e.g. images and text) are embedded at arm's length in their shared representation in multi-modal models such as CLIP. Our systematic analysis demonstrates that this gap is caused by a combination of model initialization and contrastive learning optimization. In model initialization, we show empirically and theoretically that the representation of a common deep neural network is restricted to a narrow cone. As a consequence, in a multi-modal model with two encoders, the representations of the two modalities are clearly apart when the model is initialized. During optimization, contrastive learning keeps the different modalities separate by a certain distance, which is influenced by the temperature parameter in the loss function. Our experiments further demonstrate that varying the modality gap distance has a significant impact in improving the model's downstream zero-shot classification performance and fairness. Our code and data are available at https://modalitygap.readthedocs.io/
A real-time spatiotemporal AI model analyzes skill in open surgical videos
Dec 14, 2021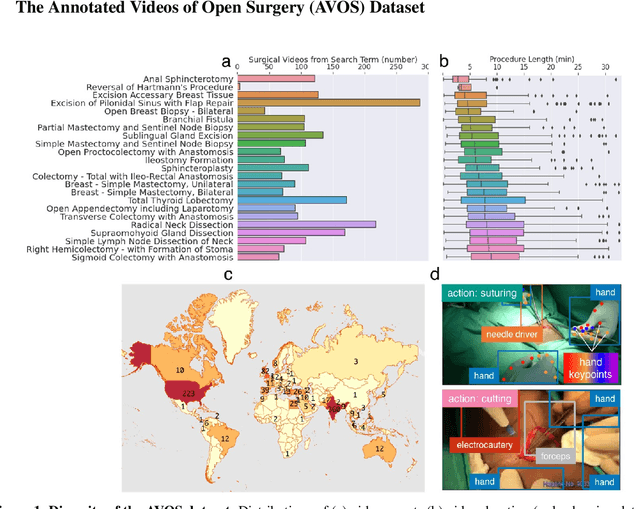
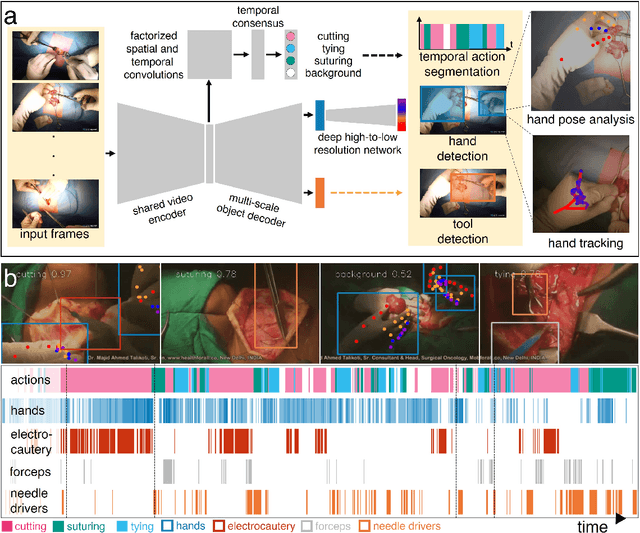
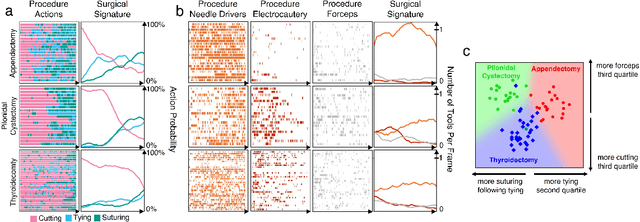
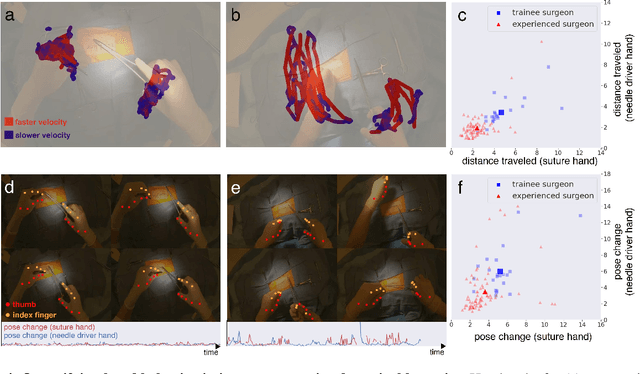
Open procedures represent the dominant form of surgery worldwide. Artificial intelligence (AI) has the potential to optimize surgical practice and improve patient outcomes, but efforts have focused primarily on minimally invasive techniques. Our work overcomes existing data limitations for training AI models by curating, from YouTube, the largest dataset of open surgical videos to date: 1997 videos from 23 surgical procedures uploaded from 50 countries. Using this dataset, we developed a multi-task AI model capable of real-time understanding of surgical behaviors, hands, and tools - the building blocks of procedural flow and surgeon skill. We show that our model generalizes across diverse surgery types and environments. Illustrating this generalizability, we directly applied our YouTube-trained model to analyze open surgeries prospectively collected at an academic medical center and identified kinematic descriptors of surgical skill related to efficiency of hand motion. Our Annotated Videos of Open Surgery (AVOS) dataset and trained model will be made available for further development of surgical AI.