 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVpop -- Key-Value Cache Compression with Predictive Online Pruning
Jul 06, 2026Key-value (KV) cache growth is a major bottleneck in autoregressive decoding, as memory and bandwidth scale linearly with context length. Existing KV eviction methods often rely on static heuristics or proxy scores, which poorly track future token utility and cause brittle eviction as relevance shifts. To address this, we introduce KVpop, which learns a fixed-budget KV eviction policy by directly supervising the keep-or-drop decision. The scorer is trained against a novel future-attention target, computed efficiently without materializing dense attention maps. We further introduce a delayed memory-based scorer that, uniquely among learned eviction methods, defers scoring for a fixed number of steps to exploit near-future context. On AIME and HMMT mathematical reasoning, KVpop retains 98% of full-attention performance on Qwen3-4B at 75% KV cache compression and 97% at 88% compression, consistently outperforming established eviction baselines. Qwen3-8B shows even stronger results, reaching near-full teacher performance. These results show that supervising eviction with future-attention signals cuts memory costs while maintaining quality.
TiRex-2: Generalizing TiRex to Multivariate Data and Streaming
Jul 01, 2026We introduce TiRex-2, a recurrent xLSTM-based time series foundation model that generalizes the univariate TiRex to multivariate forecasting with both past and future covariates. Real-world forecasting is inherently sequential: observations arrive continuously, variables evolve jointly, and a subset of covariates is known ahead of time. Existing Transformer-based time series foundation models capture cross-variate dependencies but incur quadratic complexity in context length and require full-history recomputation as new observations arrive. TiRex-2 addresses these limitations through a memory-centric recurrent design that operates at constant per-patch cost under streaming. The model combines a bidirectional time mixer with an asymmetric grouped-attention variate mixer, enabling the integration of future-known covariates while preserving strict causality over target variables. To our knowledge, this is the first time series foundation model that achieves this combination of properties. To support scalable multivariate pretraining, we propose a synthetic coupling pipeline that composes diverse multivariate samples on the fly from large univariate corpora. Empirically, TiRex-2 achieves state-of-the-art zero-shot performance on GIFT-Eval and fev-bench, remains stable when streamed to arbitrary context lengths, and maintains constant inference cost per patch. The model uses 38.4M active parameters in univariate mode, with an additional 44.1M parameters activated for multivariate forecasting.
On Subquadratic Architectures: From Applications to Principles
Jun 10, 2026Transformers dominate modern sequence modeling, but their quadratic attention incurs substantial computational cost. Subquadratic architectures offer a scalable alternative. However, it remains unclear which designs yield the most effective sequence models. We compare three leading approaches: xLSTM, Mamba-2, and Gated DeltaNet. We evaluate these models on tasks with complex dependencies: (1) code-model pre-training, (2) distillation of code models from large language models, and (3) pre-training of time-series foundation models. Across these settings, xLSTM delivers the strongest overall performance. To explain xLSTM's advantage, we present a unified formulation and analyze the underlying architectural mechanisms, focusing on state tracking and memory dynamics. Our results show that xLSTM enables more flexible and stable memory correction via its gating scheme. We corroborate these findings on controlled synthetic length-generalization tasks. Overall, our findings indicate that xLSTM's gains on complex tasks stem from robust state tracking and accumulation.
Effective Distillation to Hybrid xLSTM Architectures
Mar 16, 2026There have been numerous attempts to distill quadratic attention-based large language models (LLMs) into sub-quadratic linearized architectures. However, despite extensive research, such distilled models often fail to match the performance of their teacher LLMs on various downstream tasks. We set out the goal of lossless distillation, which we define in terms of tolerance-corrected Win-and-Tie rates between student and teacher on sets of tasks. To this end, we introduce an effective distillation pipeline for xLSTM-based students. We propose an additional merging stage, where individually linearized experts are combined into a single model. We show the effectiveness of this pipeline by distilling base and instruction-tuned models from the Llama, Qwen, and Olmo families. In many settings, our xLSTM-based students recover most of the teacher's performance, and even exceed it on some downstream tasks. Our contributions are an important step towards more energy-efficient and cost-effective replacements for transformer-based LLMs.
xLSTM Scaling Laws: Competitive Performance with Linear Time-Complexity
Oct 02, 2025Scaling laws play a central role in the success of Large Language Models (LLMs), enabling the prediction of model performance relative to compute budgets prior to training. While Transformers have been the dominant architecture, recent alternatives such as xLSTM offer linear complexity with respect to context length while remaining competitive in the billion-parameter regime. We conduct a comparative investigation on the scaling behavior of Transformers and xLSTM along the following lines, providing insights to guide future model design and deployment. First, we study the scaling behavior for xLSTM in compute-optimal and over-training regimes using both IsoFLOP and parametric fit approaches on a wide range of model sizes (80M-7B) and number of training tokens (2B-2T). Second, we examine the dependence of optimal model sizes on context length, a pivotal aspect that was largely ignored in previous work. Finally, we analyze inference-time scaling characteristics. Our findings reveal that in typical LLM training and inference scenarios, xLSTM scales favorably compared to Transformers. Importantly, xLSTM's advantage widens as training and inference contexts grow.
TiRex: Zero-Shot Forecasting Across Long and Short Horizons with Enhanced In-Context Learning
May 29, 2025In-context learning, the ability of large language models to perform tasks using only examples provided in the prompt, has recently been adapted for time series forecasting. This paradigm enables zero-shot prediction, where past values serve as context for forecasting future values, making powerful forecasting tools accessible to non-experts and increasing the performance when training data are scarce. Most existing zero-shot forecasting approaches rely on transformer architectures, which, despite their success in language, often fall short of expectations in time series forecasting, where recurrent models like LSTMs frequently have the edge. Conversely, while LSTMs are well-suited for time series modeling due to their state-tracking capabilities, they lack strong in-context learning abilities. We introduce TiRex that closes this gap by leveraging xLSTM, an enhanced LSTM with competitive in-context learning skills. Unlike transformers, state-space models, or parallelizable RNNs such as RWKV, TiRex retains state-tracking, a critical property for long-horizon forecasting. To further facilitate its state-tracking ability, we propose a training-time masking strategy called CPM. TiRex sets a new state of the art in zero-shot time series forecasting on the HuggingFace benchmarks GiftEval and Chronos-ZS, outperforming significantly larger models including TabPFN-TS (Prior Labs), Chronos Bolt (Amazon), TimesFM (Google), and Moirai (Salesforce) across both short- and long-term forecasts.
xLSTM 7B: A Recurrent LLM for Fast and Efficient Inference
Mar 17, 2025Recent breakthroughs in solving reasoning, math and coding problems with Large Language Models (LLMs) have been enabled by investing substantial computation budgets at inference time. Therefore, inference speed is one of the most critical properties of LLM architectures, and there is a growing need for LLMs that are efficient and fast at inference. Recently, LLMs built on the xLSTM architecture have emerged as a powerful alternative to Transformers, offering linear compute scaling with sequence length and constant memory usage, both highly desirable properties for efficient inference. However, such xLSTM-based LLMs have yet to be scaled to larger models and assessed and compared with respect to inference speed and efficiency. In this work, we introduce xLSTM 7B, a 7-billion-parameter LLM that combines xLSTM's architectural benefits with targeted optimizations for fast and efficient inference. Our experiments demonstrate that xLSTM 7B achieves performance on downstream tasks comparable to other similar-sized LLMs, while providing significantly faster inference speeds and greater efficiency compared to Llama- and Mamba-based LLMs. These results establish xLSTM 7B as the fastest and most efficient 7B LLM, offering a solution for tasks that require large amounts of test-time computation. Our work highlights xLSTM's potential as a foundational architecture for methods building on heavy use of LLM inference. Our model weights, model code and training code are open-source.
Deep Learning for MIR Tutorial
Jan 15, 2020Deep Learning has become state of the art in visual computing and continuously emerges into the Music Information Retrieval (MIR) and audio retrieval domain. In order to bring attention to this topic we propose an introductory tutorial on deep learning for MIR. Besides a general introduction to neural networks, the proposed tutorial covers a wide range of MIR relevant deep learning approaches. \textbf{Convolutional Neural Networks} are currently a de-facto standard for deep learning based audio retrieval. \textbf{Recurrent Neural Networks} have proven to be effective in onset detection tasks such as beat or audio-event detection. \textbf{Siamese Networks} have been shown effective in learning audio representations and distance functions specific for music similarity retrieval. We will incorporate both academic and industrial points of view into the tutorial. Accompanying the tutorial, we will create a Github repository for the content presented at the tutorial as well as references to state of the art work and literature for further reading. This repository will remain public after the conference.
On the Potential of Simple Framewise Approaches to Piano Transcription
Dec 15, 2016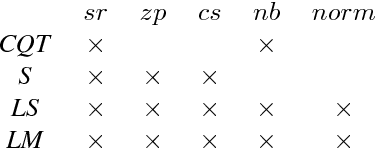
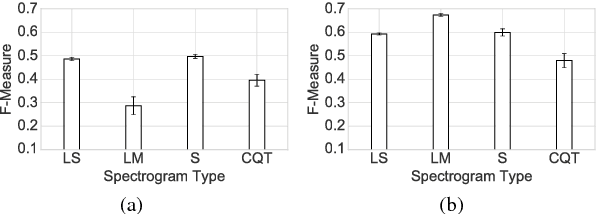
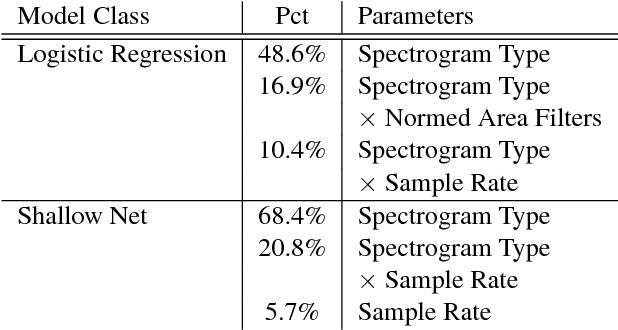
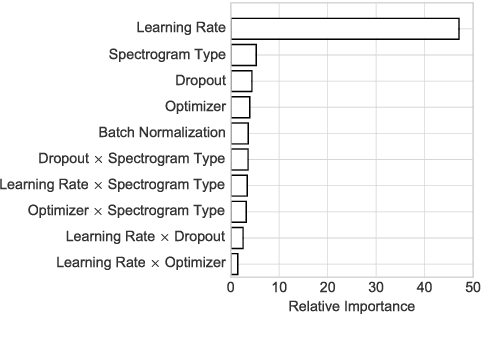
In an attempt at exploring the limitations of simple approaches to the task of piano transcription (as usually defined in MIR), we conduct an in-depth analysis of neural network-based framewise transcription. We systematically compare different popular input representations for transcription systems to determine the ones most suitable for use with neural networks. Exploiting recent advances in training techniques and new regularizers, and taking into account hyper-parameter tuning, we show that it is possible, by simple bottom-up frame-wise processing, to obtain a piano transcriber that outperforms the current published state of the art on the publicly available MAPS dataset -- without any complex post-processing steps. Thus, we propose this simple approach as a new baseline for this dataset, for future transcription research to build on and improve.