 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeong Joon Oh
ECCV Caption: Correcting False Negatives by Collecting Machine-and-Human-verified Image-Caption Associations for MS-COCO
Apr 14, 2022




Image-Text matching (ITM) is a common task for evaluating the quality of Vision and Language (VL) models. However, existing ITM benchmarks have a significant limitation. They have many missing correspondences, originating from the data construction process itself. For example, a caption is only matched with one image although the caption can be matched with other similar images, and vice versa. To correct the massive false negatives, we construct the Extended COCO Validation (ECCV) Caption dataset by supplying the missing associations with machine and human annotators. We employ five state-of-the-art ITM models with diverse properties for our annotation process. Our dataset provides x3.6 positive image-to-caption associations and x8.5 caption-to-image associations compared to the original MS-COCO. We also propose to use an informative ranking-based metric, rather than the popular Recall@K(R@K). We re-evaluate the existing 25 VL models on existing and proposed benchmarks. Our findings are that the existing benchmarks, such as COCO 1K R@K, COCO 5K R@K, CxC R@1 are highly correlated with each other, while the rankings change when we shift to the ECCV mAP. Lastly, we delve into the effect of the bias introduced by the choice of machine annotator. Source code and dataset are available at https://github.com/naver-ai/eccv-caption
Weakly Supervised Semantic Segmentation using Out-of-Distribution Data
Mar 08, 2022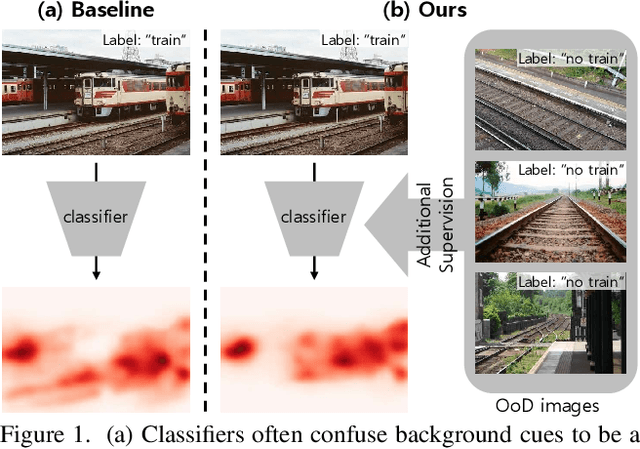
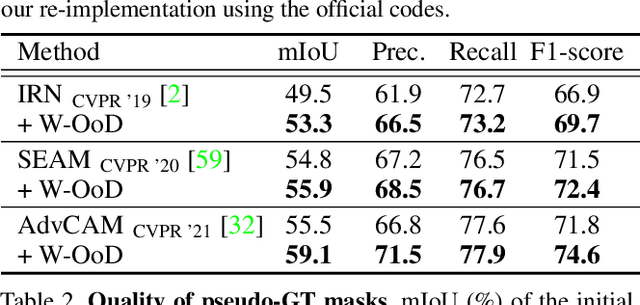

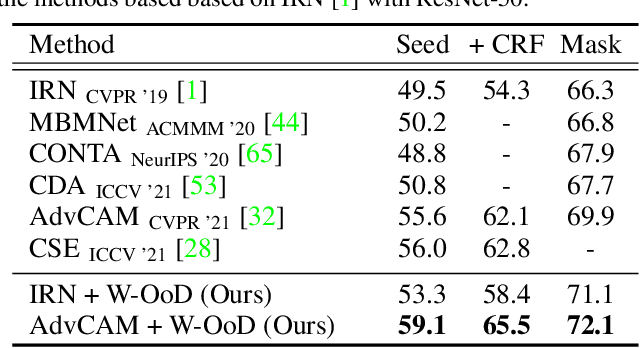
Weakly supervised semantic segmentation (WSSS) methods are often built on pixel-level localization maps obtained from a classifier. However, training on class labels only, classifiers suffer from the spurious correlation between foreground and background cues (e.g. train and rail), fundamentally bounding the performance of WSSS. There have been previous endeavors to address this issue with additional supervision. We propose a novel source of information to distinguish foreground from the background: Out-of-Distribution (OoD) data, or images devoid of foreground object classes. In particular, we utilize the hard OoDs that the classifier is likely to make false-positive predictions. These samples typically carry key visual features on the background (e.g. rail) that the classifiers often confuse as foreground (e.g. train), so these cues let classifiers correctly suppress spurious background cues. Acquiring such hard OoDs does not require an extensive amount of annotation efforts; it only incurs a few additional image-level labeling costs on top of the original efforts to collect class labels. We propose a method, W-OoD, for utilizing the hard OoDs. W-OoD achieves state-of-the-art performance on Pascal VOC 2012.
ALP: Data Augmentation using Lexicalized PCFGs for Few-Shot Text Classification
Dec 16, 2021
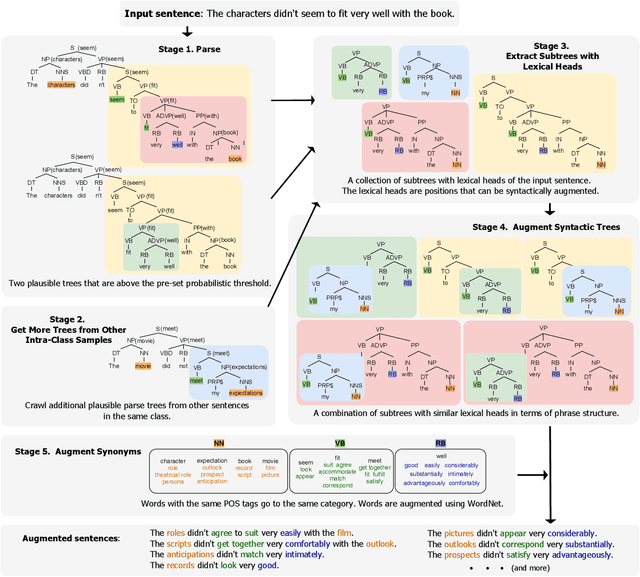
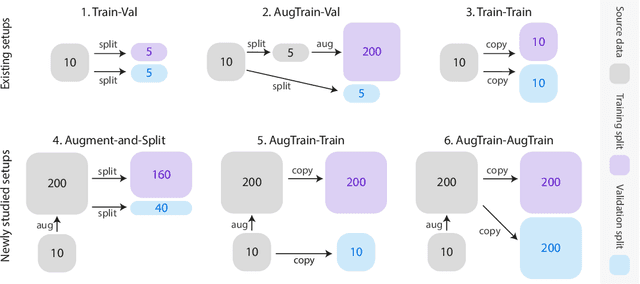
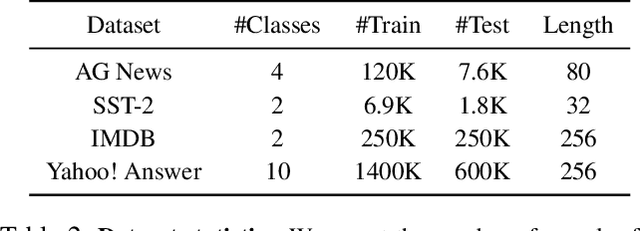
Data augmentation has been an important ingredient for boosting performances of learned models. Prior data augmentation methods for few-shot text classification have led to great performance boosts. However, they have not been designed to capture the intricate compositional structure of natural language. As a result, they fail to generate samples with plausible and diverse sentence structures. Motivated by this, we present the data Augmentation using Lexicalized Probabilistic context-free grammars (ALP) that generates augmented samples with diverse syntactic structures with plausible grammar. The lexicalized PCFG parse trees consider both the constituents and dependencies to produce a syntactic frame that maximizes a variety of word choices in a syntactically preservable manner without specific domain experts. Experiments on few-shot text classification tasks demonstrate that ALP enhances many state-of-the-art classification methods. As a second contribution, we delve into the train-val splitting methodologies when a data augmentation method comes into play. We argue empirically that the traditional splitting of training and validation sets is sub-optimal compared to our novel augmentation-based splitting strategies that further expand the training split with the same number of labeled data. Taken together, our contributions on the data augmentation strategies yield a strong training recipe for few-shot text classification tasks.
Which Shortcut Cues Will DNNs Choose? A Study from the Parameter-Space Perspective
Oct 06, 2021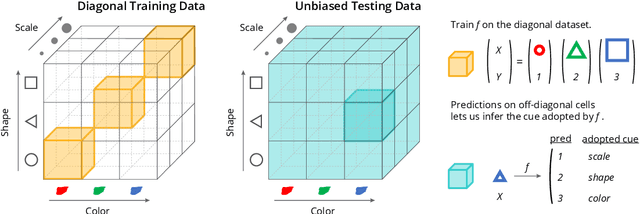
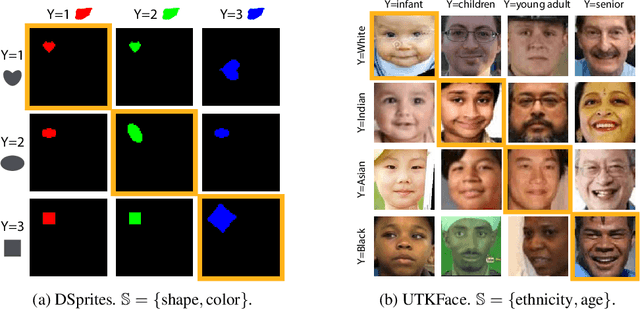
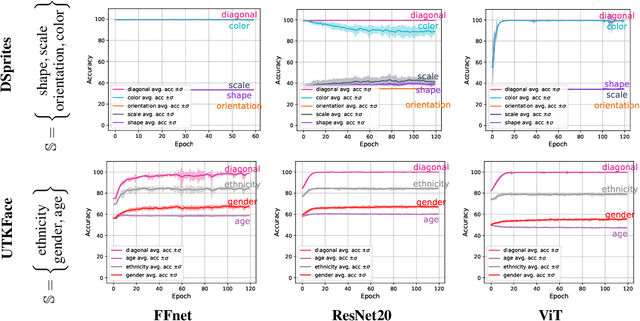
Deep neural networks (DNNs) often rely on easy-to-learn discriminatory features, or cues, that are not necessarily essential to the problem at hand. For example, ducks in an image may be recognized based on their typical background scenery, such as lakes or streams. This phenomenon, also known as shortcut learning, is emerging as a key limitation of the current generation of machine learning models. In this work, we introduce a set of experiments to deepen our understanding of shortcut learning and its implications. We design a training setup with several shortcut cues, named WCST-ML, where each cue is equally conducive to the visual recognition problem at hand. Even under equal opportunities, we observe that (1) certain cues are preferred to others, (2) solutions biased to the easy-to-learn cues tend to converge to relatively flat minima on the loss surface, and (3) the solutions focusing on those preferred cues are far more abundant in the parameter space. We explain the abundance of certain cues via their Kolmogorov (descriptional) complexity: solutions corresponding to Kolmogorov-simple cues are abundant in the parameter space and are thus preferred by DNNs. Our studies are based on the synthetic dataset DSprites and the face dataset UTKFace. In our WCST-ML, we observe that the inborn bias of models leans toward simple cues, such as color and ethnicity. Our findings emphasize the importance of active human intervention to remove the inborn model biases that may cause negative societal impacts.
Keep CALM and Improve Visual Feature Attribution
Jun 15, 2021
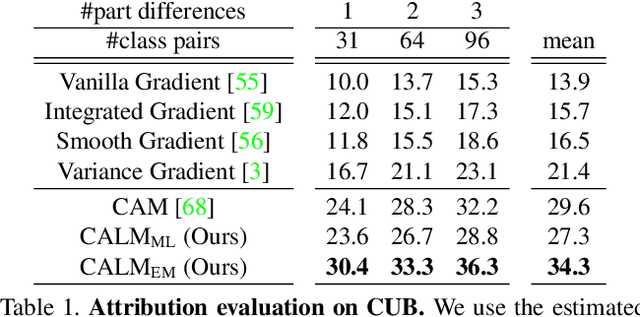
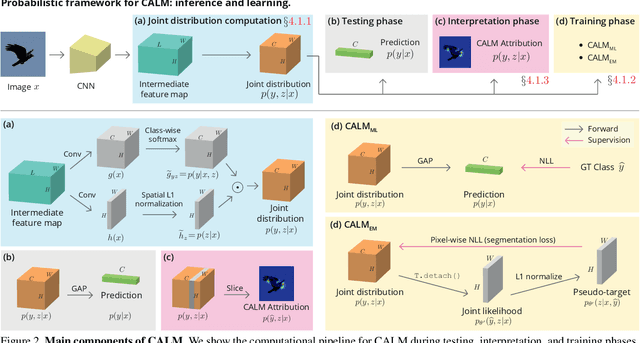

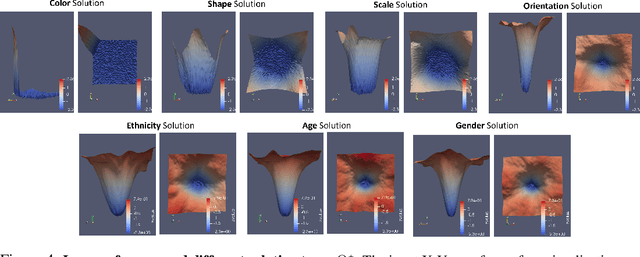
The class activation mapping, or CAM, has been the cornerstone of feature attribution methods for multiple vision tasks. Its simplicity and effectiveness have led to wide applications in the explanation of visual predictions and weakly-supervised localization tasks. However, CAM has its own shortcomings. The computation of attribution maps relies on ad-hoc calibration steps that are not part of the training computational graph, making it difficult for us to understand the real meaning of the attribution values. In this paper, we improve CAM by explicitly incorporating a latent variable encoding the location of the cue for recognition in the formulation, thereby subsuming the attribution map into the training computational graph. The resulting model, class activation latent mapping, or CALM, is trained with the expectation-maximization algorithm. Our experiments show that CALM identifies discriminative attributes for image classifiers more accurately than CAM and other visual attribution baselines. CALM also shows performance improvements over prior arts on the weakly-supervised object localization benchmarks. Our code is available at https://github.com/naver-ai/calm.
Neural Hybrid Automata: Learning Dynamics with Multiple Modes and Stochastic Transitions
Jun 08, 2021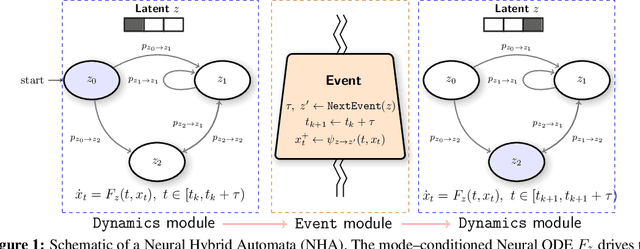
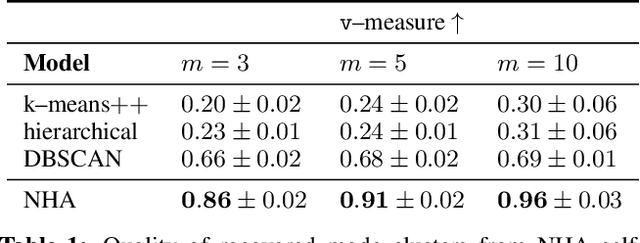
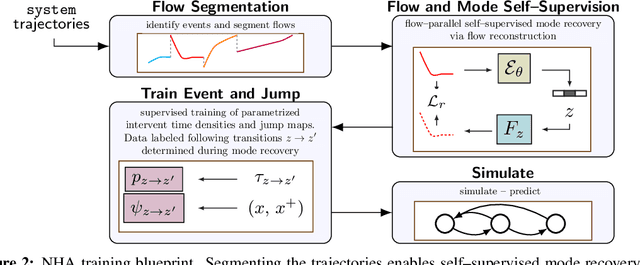
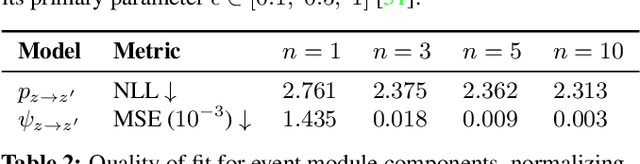
Effective control and prediction of dynamical systems often require appropriate handling of continuous-time and discrete, event-triggered processes. Stochastic hybrid systems (SHSs), common across engineering domains, provide a formalism for dynamical systems subject to discrete, possibly stochastic, state jumps and multi-modal continuous-time flows. Despite the versatility and importance of SHSs across applications, a general procedure for the explicit learning of both discrete events and multi-mode continuous dynamics remains an open problem. This work introduces Neural Hybrid Automata (NHAs), a recipe for learning SHS dynamics without a priori knowledge on the number of modes and inter-modal transition dynamics. NHAs provide a systematic inference method based on normalizing flows, neural differential equations and self-supervision. We showcase NHAs on several tasks, including mode recovery and flow learning in systems with stochastic transitions, and end-to-end learning of hierarchical robot controllers.
Rethinking Spatial Dimensions of Vision Transformers
Mar 30, 2021
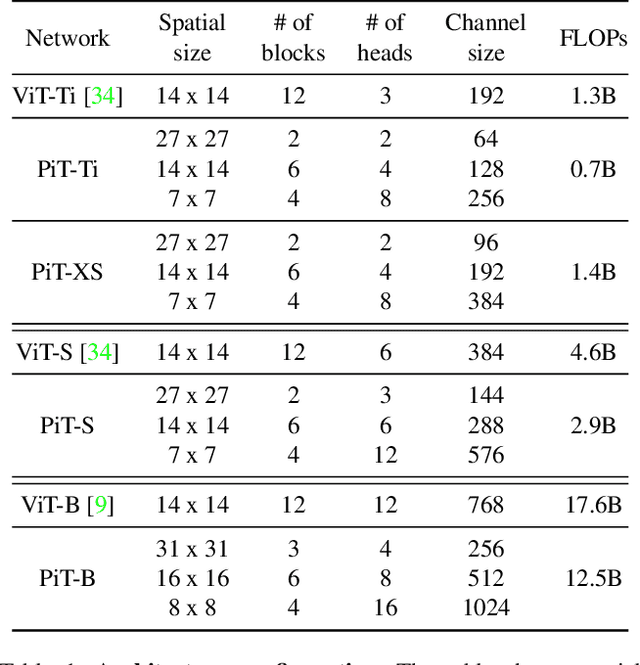
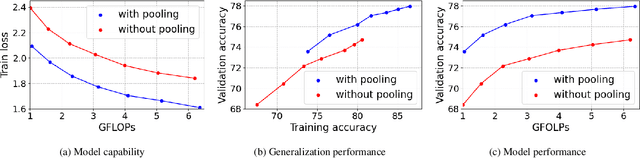
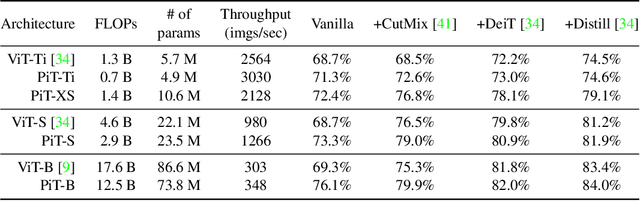
Vision Transformer (ViT) extends the application range of transformers from language processing to computer vision tasks as being an alternative architecture against the existing convolutional neural networks (CNN). Since the transformer-based architecture has been innovative for computer vision modeling, the design convention towards an effective architecture has been less studied yet. From the successful design principles of CNN, we investigate the role of the spatial dimension conversion and its effectiveness on the transformer-based architecture. We particularly attend the dimension reduction principle of CNNs; as the depth increases, a conventional CNN increases channel dimension and decreases spatial dimensions. We empirically show that such a spatial dimension reduction is beneficial to a transformer architecture as well, and propose a novel Pooling-based Vision Transformer (PiT) upon the original ViT model. We show that PiT achieves the improved model capability and generalization performance against ViT. Throughout the extensive experiments, we further show PiT outperforms the baseline on several tasks such as image classification, object detection and robustness evaluation. Source codes and ImageNet models are available at https://github.com/naver-ai/pit
Probabilistic Embeddings for Cross-Modal Retrieval
Jan 13, 2021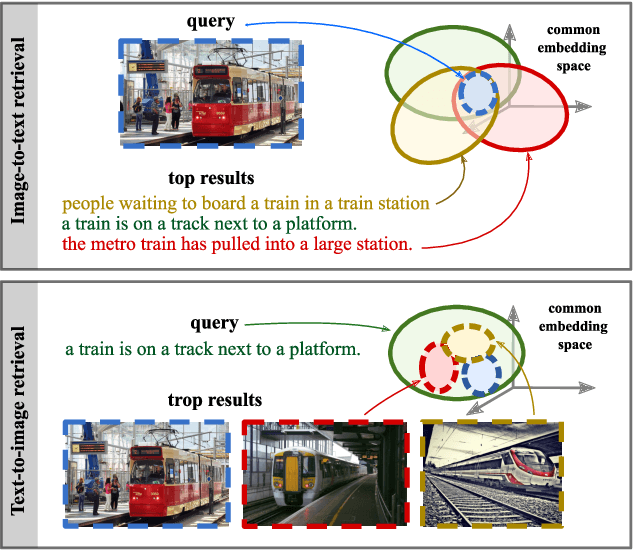
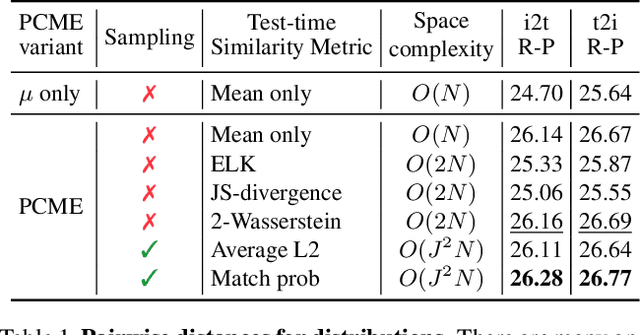
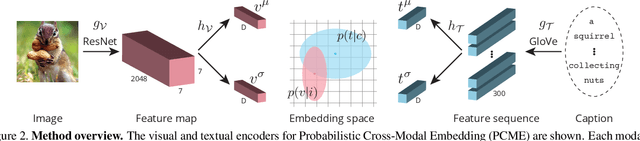
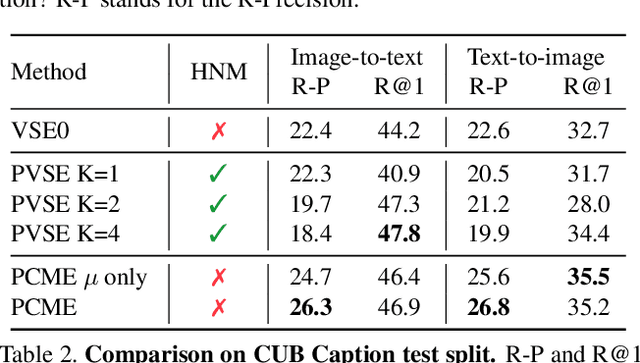
Cross-modal retrieval methods build a common representation space for samples from multiple modalities, typically from the vision and the language domains. For images and their captions, the multiplicity of the correspondences makes the task particularly challenging. Given an image (respectively a caption), there are multiple captions (respectively images) that equally make sense. In this paper, we argue that deterministic functions are not sufficiently powerful to capture such one-to-many correspondences. Instead, we propose to use Probabilistic Cross-Modal Embedding (PCME), where samples from the different modalities are represented as probabilistic distributions in the common embedding space. Since common benchmarks such as COCO suffer from non-exhaustive annotations for cross-modal matches, we propose to additionally evaluate retrieval on the CUB dataset, a smaller yet clean database where all possible image-caption pairs are annotated. We extensively ablate PCME and demonstrate that it not only improves the retrieval performance over its deterministic counterpart, but also provides uncertainty estimates that render the embeddings more interpretable.
Re-labeling ImageNet: from Single to Multi-Labels, from Global to Localized Labels
Jan 13, 2021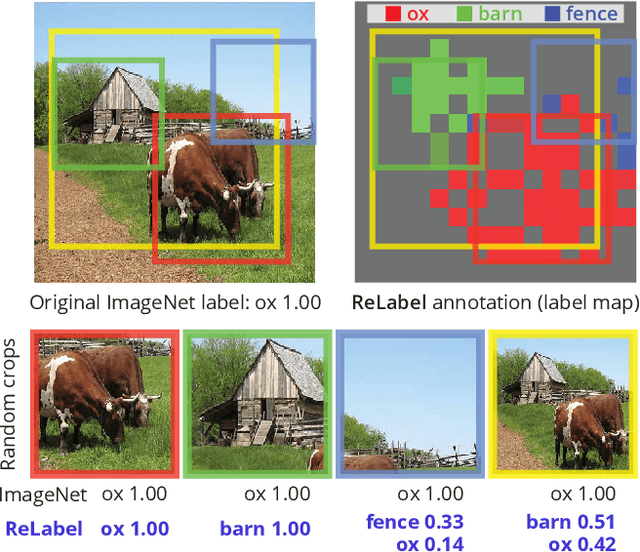


ImageNet has been arguably the most popular image classification benchmark, but it is also the one with a significant level of label noise. Recent studies have shown that many samples contain multiple classes, despite being assumed to be a single-label benchmark. They have thus proposed to turn ImageNet evaluation into a multi-label task, with exhaustive multi-label annotations per image. However, they have not fixed the training set, presumably because of a formidable annotation cost. We argue that the mismatch between single-label annotations and effectively multi-label images is equally, if not more, problematic in the training setup, where random crops are applied. With the single-label annotations, a random crop of an image may contain an entirely different object from the ground truth, introducing noisy or even incorrect supervision during training. We thus re-label the ImageNet training set with multi-labels. We address the annotation cost barrier by letting a strong image classifier, trained on an extra source of data, generate the multi-labels. We utilize the pixel-wise multi-label predictions before the final pooling layer, in order to exploit the additional location-specific supervision signals. Training on the re-labeled samples results in improved model performances across the board. ResNet-50 attains the top-1 classification accuracy of 78.9% on ImageNet with our localized multi-labels, which can be further boosted to 80.2% with the CutMix regularization. We show that the models trained with localized multi-labels also outperforms the baselines on transfer learning to object detection and instance segmentation tasks, and various robustness benchmarks. The re-labeled ImageNet training set, pre-trained weights, and the source code are available at {https://github.com/naver-ai/relabel_imagenet}.