 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Informed Sampler: A Discriminative Approach to Bayesian Inference in Generative Computer Vision Models
Mar 07, 2015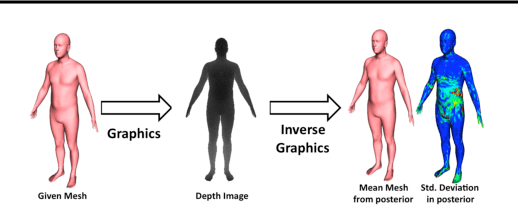
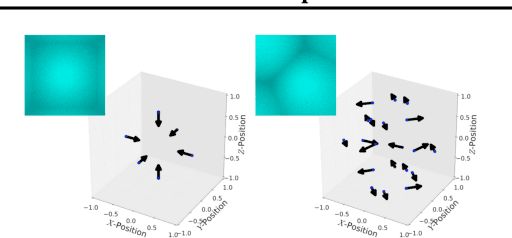
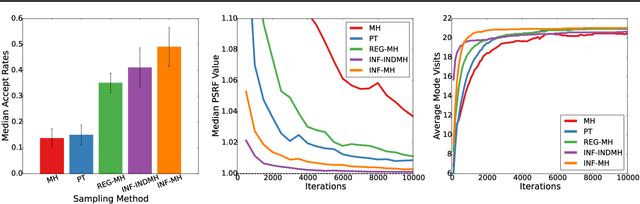
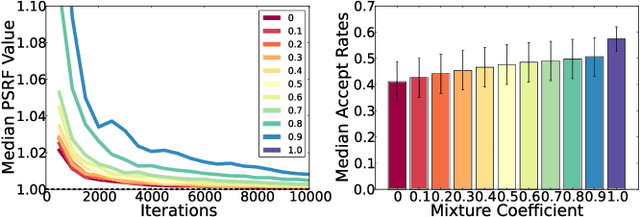
Computer vision is hard because of a large variability in lighting, shape, and texture; in addition the image signal is non-additive due to occlusion. Generative models promised to account for this variability by accurately modelling the image formation process as a function of latent variables with prior beliefs. Bayesian posterior inference could then, in principle, explain the observation. While intuitively appealing, generative models for computer vision have largely failed to deliver on that promise due to the difficulty of posterior inference. As a result the community has favoured efficient discriminative approaches. We still believe in the usefulness of generative models in computer vision, but argue that we need to leverage existing discriminative or even heuristic computer vision methods. We implement this idea in a principled way with an "informed sampler" and in careful experiments demonstrate it on challenging generative models which contain renderer programs as their components. We concentrate on the problem of inverting an existing graphics rendering engine, an approach that can be understood as "Inverse Graphics". The informed sampler, using simple discriminative proposals based on existing computer vision technology, achieves significant improvements of inference.
Cascades of Regression Tree Fields for Image Restoration
Nov 21, 2014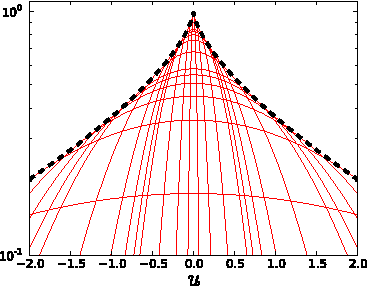
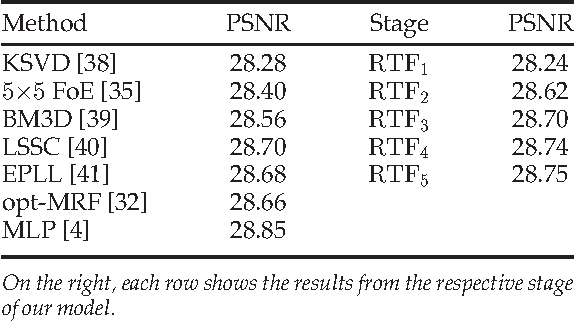
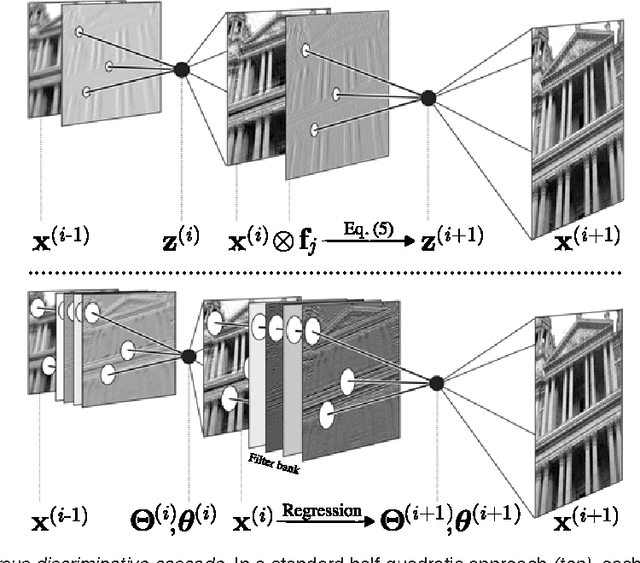
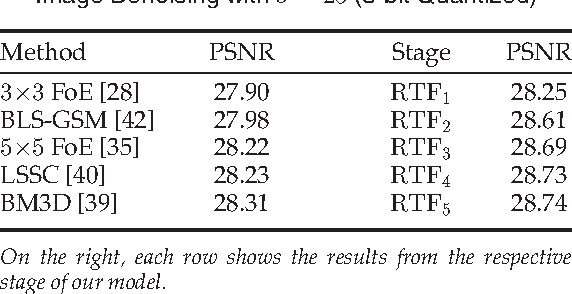
Conditional random fields (CRFs) are popular discriminative models for computer vision and have been successfully applied in the domain of image restoration, especially to image denoising. For image deblurring, however, discriminative approaches have been mostly lacking. We posit two reasons for this: First, the blur kernel is often only known at test time, requiring any discriminative approach to cope with considerable variability. Second, given this variability it is quite difficult to construct suitable features for discriminative prediction. To address these challenges we first show a connection between common half-quadratic inference for generative image priors and Gaussian CRFs. Based on this analysis, we then propose a cascade model for image restoration that consists of a Gaussian CRF at each stage. Each stage of our cascade is semi-parametric, i.e. it depends on the instance-specific parameters of the restoration problem, such as the blur kernel. We train our model by loss minimization with synthetically generated training data. Our experiments show that when applied to non-blind image deblurring, the proposed approach is efficient and yields state-of-the-art restoration quality on images corrupted with synthetic and real blur. Moreover, we demonstrate its suitability for image denoising, where we achieve competitive results for grayscale and color images.
A Comparative Study of Modern Inference Techniques for Structured Discrete Energy Minimization Problems
Apr 02, 2014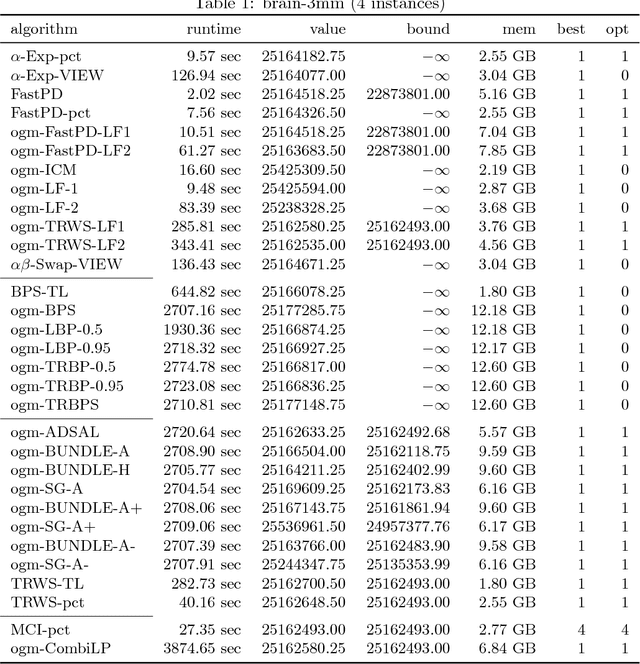
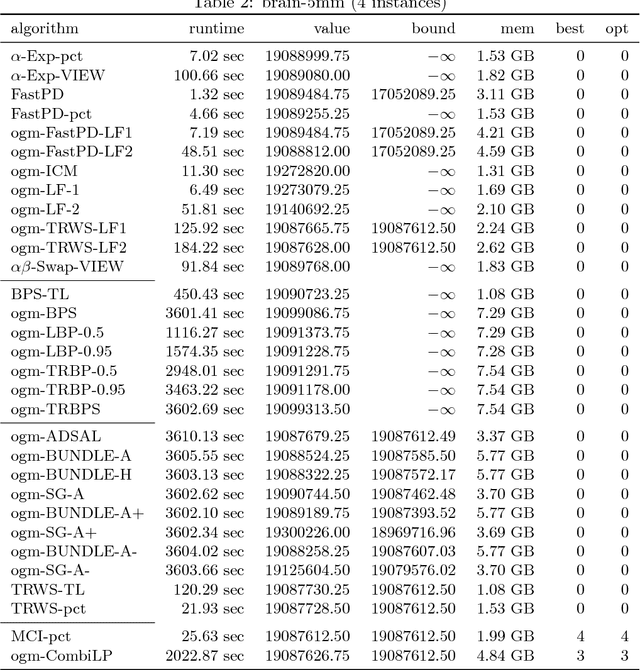
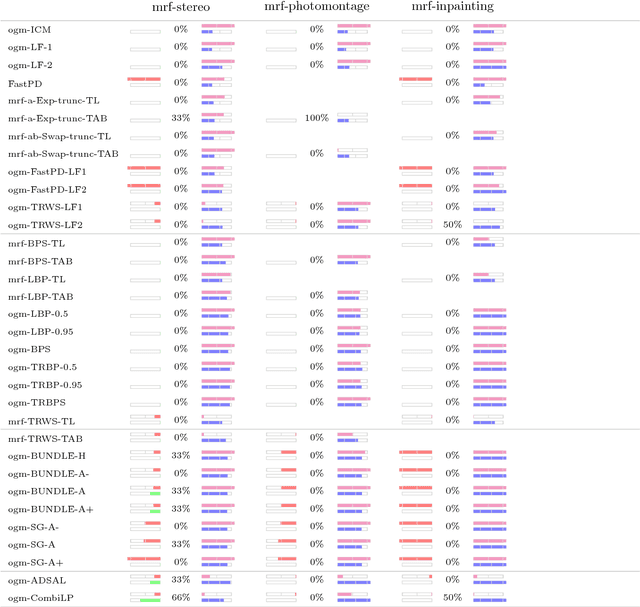
Szeliski et al. published an influential study in 2006 on energy minimization methods for Markov Random Fields (MRF). This study provided valuable insights in choosing the best optimization technique for certain classes of problems. While these insights remain generally useful today, the phenomenal success of random field models means that the kinds of inference problems that have to be solved changed significantly. Specifically, the models today often include higher order interactions, flexible connectivity structures, large la\-bel-spaces of different cardinalities, or learned energy tables. To reflect these changes, we provide a modernized and enlarged study. We present an empirical comparison of 32 state-of-the-art optimization techniques on a corpus of 2,453 energy minimization instances from diverse applications in computer vision. To ensure reproducibility, we evaluate all methods in the OpenGM 2 framework and report extensive results regarding runtime and solution quality. Key insights from our study agree with the results of Szeliski et al. for the types of models they studied. However, on new and challenging types of models our findings disagree and suggest that polyhedral methods and integer programming solvers are competitive in terms of runtime and solution quality over a large range of model types.
Bayesian Inference for NMR Spectroscopy with Applications to Chemical Quantification
Feb 24, 2014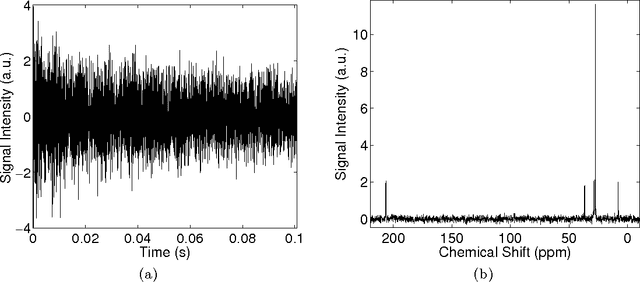
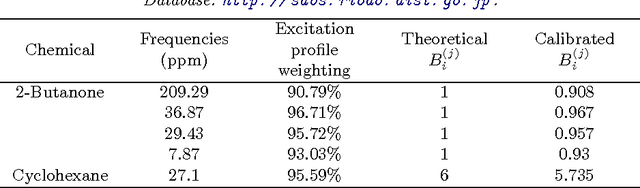
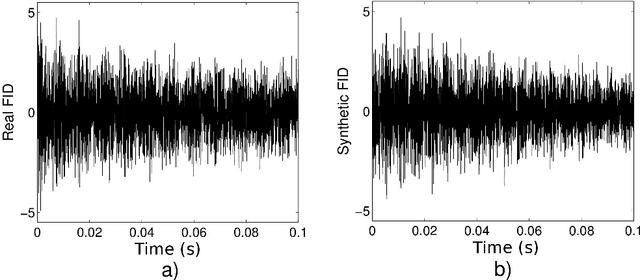
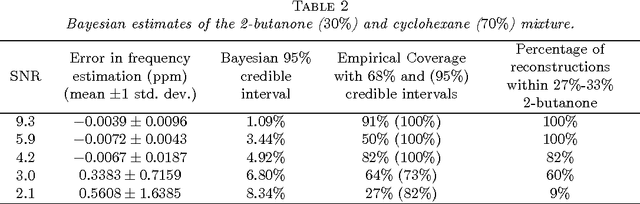
Nuclear magnetic resonance (NMR) spectroscopy exploits the magnetic properties of atomic nuclei to discover the structure, reaction state and chemical environment of molecules. We propose a probabilistic generative model and inference procedures for NMR spectroscopy. Specifically, we use a weighted sum of trigonometric functions undergoing exponential decay to model free induction decay (FID) signals. We discuss the challenges in estimating the components of this general model -- amplitudes, phase shifts, frequencies, decay rates, and noise variances -- and offer practical solutions. We compare with conventional Fourier transform spectroscopy for estimating the relative concentrations of chemicals in a mixture, using synthetic and experimentally acquired FID signals. We find the proposed model is particularly robust to low signal to noise ratios (SNR), and overlapping peaks in the Fourier transform of the FID, enabling accurate predictions (e.g., 1% sensitivity at low SNR) which are not possible with conventional spectroscopy (5% sensitivity).
Improved Information Gain Estimates for Decision Tree Induction
Jun 18, 2012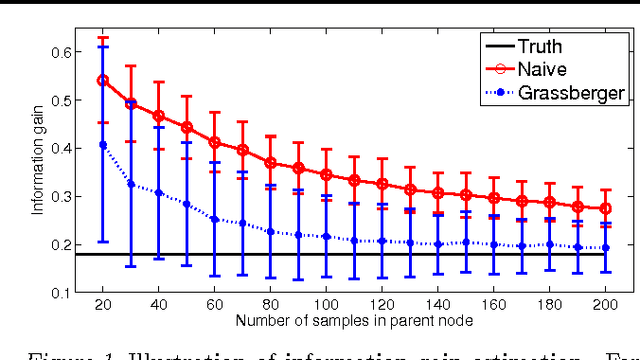
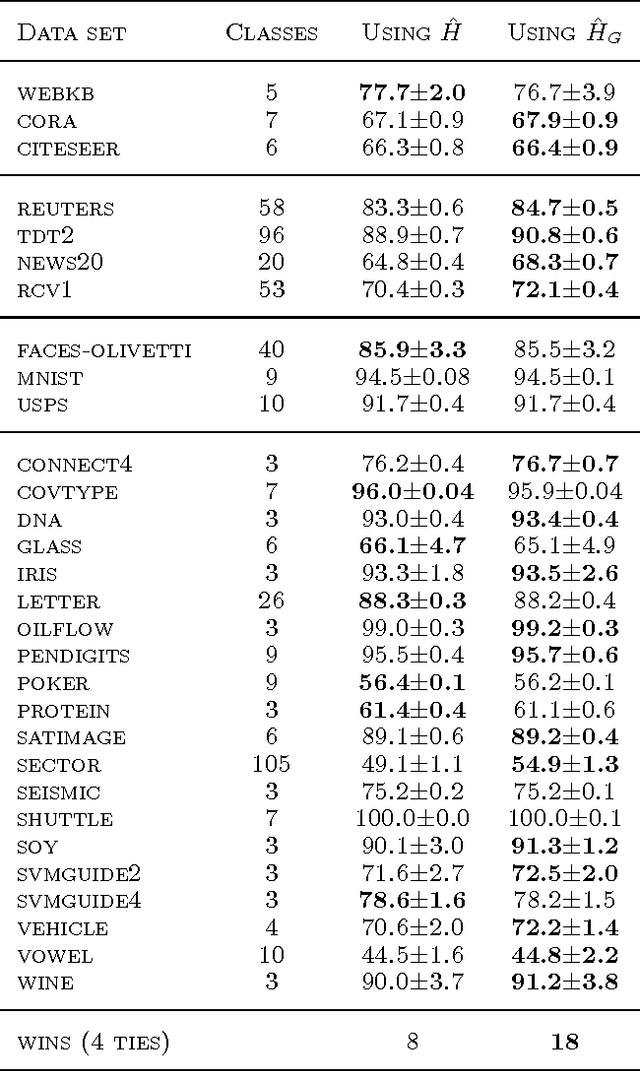
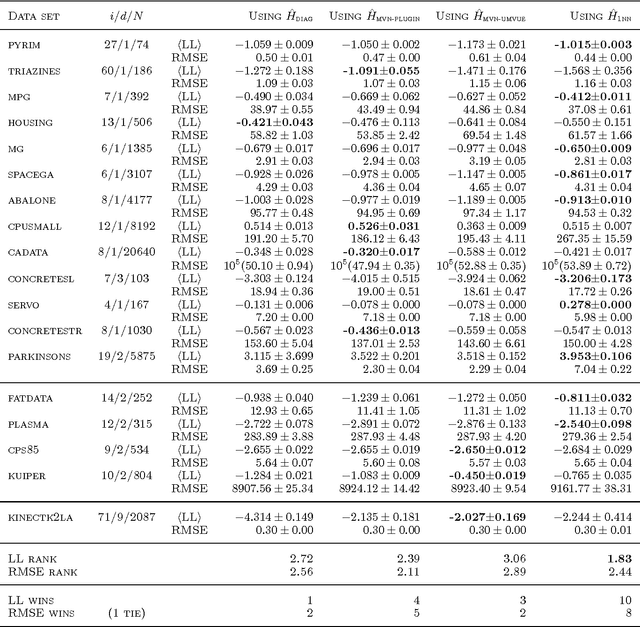
Ensembles of classification and regression trees remain popular machine learning methods because they define flexible non-parametric models that predict well and are computationally efficient both during training and testing. During induction of decision trees one aims to find predicates that are maximally informative about the prediction target. To select good predicates most approaches estimate an information-theoretic scoring function, the information gain, both for classification and regression problems. We point out that the common estimation procedures are biased and show that by replacing them with improved estimators of the discrete and the differential entropy we can obtain better decision trees. In effect our modifications yield improved predictive performance and are simple to implement in any decision tree code.