 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Training of Generative Adversarial Networks through Regularization
Nov 07, 2017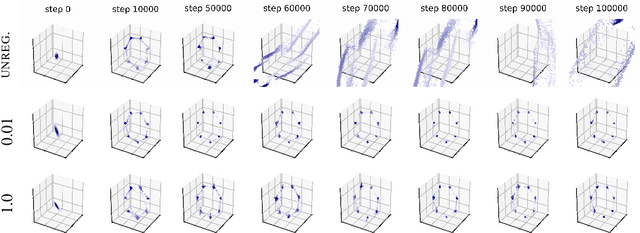



Deep generative models based on Generative Adversarial Networks (GANs) have demonstrated impressive sample quality but in order to work they require a careful choice of architecture, parameter initialization, and selection of hyper-parameters. This fragility is in part due to a dimensional mismatch or non-overlapping support between the model distribution and the data distribution, causing their density ratio and the associated f-divergence to be undefined. We overcome this fundamental limitation and propose a new regularization approach with low computational cost that yields a stable GAN training procedure. We demonstrate the effectiveness of this regularizer across several architectures trained on common benchmark image generation tasks. Our regularization turns GAN models into reliable building blocks for deep learning.
The Atari Grand Challenge Dataset
May 31, 2017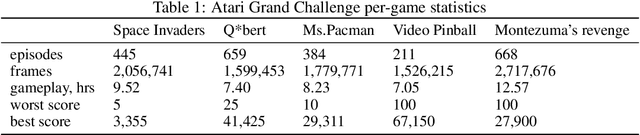

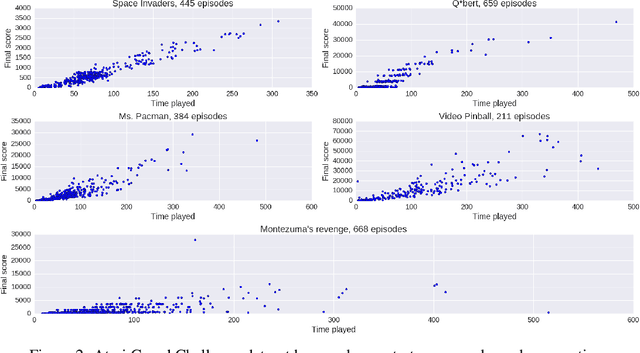
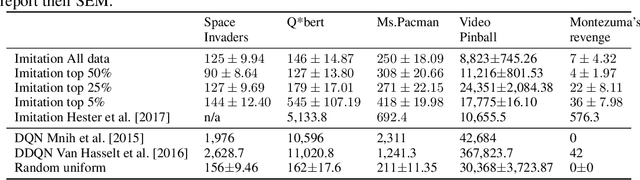
Recent progress in Reinforcement Learning (RL), fueled by its combination, with Deep Learning has enabled impressive results in learning to interact with complex virtual environments, yet real-world applications of RL are still scarce. A key limitation is data efficiency, with current state-of-the-art approaches requiring millions of training samples. A promising way to tackle this problem is to augment RL with learning from human demonstrations. However, human demonstration data is not yet readily available. This hinders progress in this direction. The present work addresses this problem as follows. We (i) collect and describe a large dataset of human Atari 2600 replays -- the largest and most diverse such data set publicly released to date, (ii) illustrate an example use of this dataset by analyzing the relation between demonstration quality and imitation learning performance, and (iii) outline possible research directions that are opened up by our work.
Multi-Level Variational Autoencoder: Learning Disentangled Representations from Grouped Observations
May 24, 2017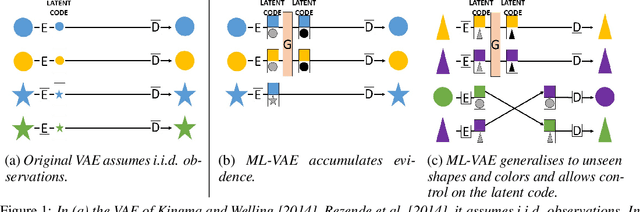
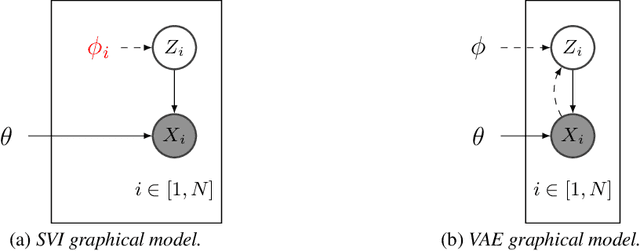
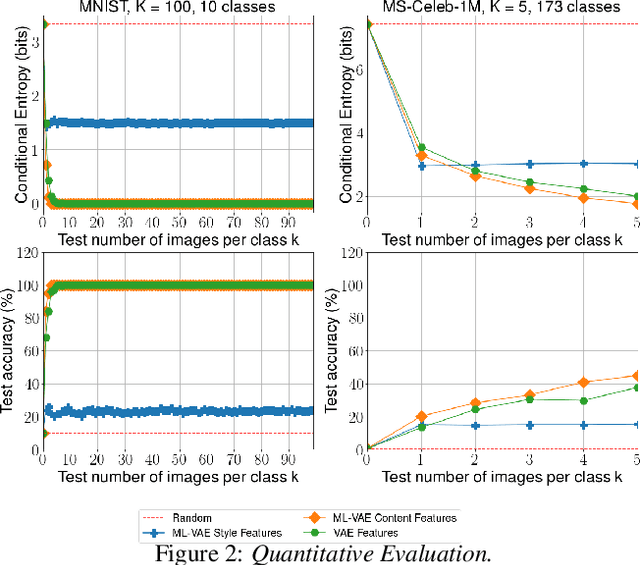
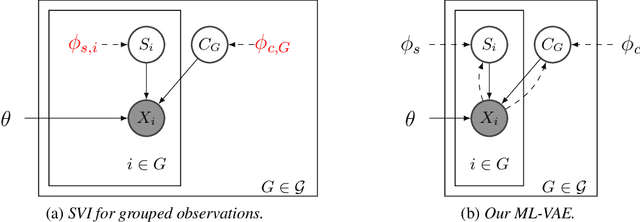
We would like to learn a representation of the data which decomposes an observation into factors of variation which we can independently control. Specifically, we want to use minimal supervision to learn a latent representation that reflects the semantics behind a specific grouping of the data, where within a group the samples share a common factor of variation. For example, consider a collection of face images grouped by identity. We wish to anchor the semantics of the grouping into a relevant and disentangled representation that we can easily exploit. However, existing deep probabilistic models often assume that the observations are independent and identically distributed. We present the Multi-Level Variational Autoencoder (ML-VAE), a new deep probabilistic model for learning a disentangled representation of a set of grouped observations. The ML-VAE separates the latent representation into semantically meaningful parts by working both at the group level and the observation level, while retaining efficient test-time inference. Quantitative and qualitative evaluations show that the ML-VAE model (i) learns a semantically meaningful disentanglement of grouped data, (ii) enables manipulation of the latent representation, and (iii) generalises to unseen groups.
PoseAgent: Budget-Constrained 6D Object Pose Estimation via Reinforcement Learning
Apr 11, 2017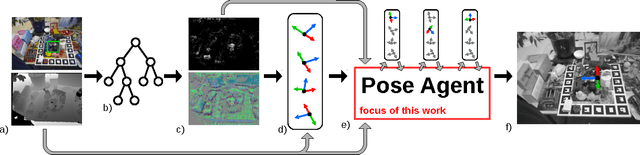
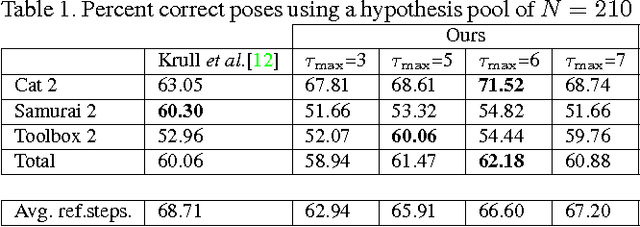
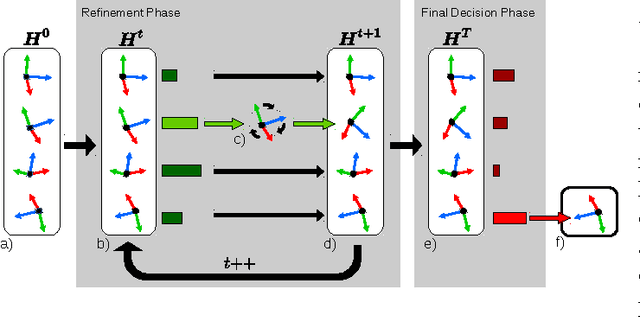
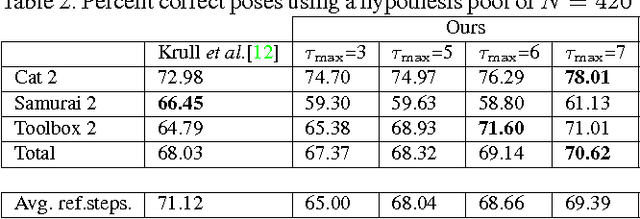
State-of-the-art computer vision algorithms often achieve efficiency by making discrete choices about which hypotheses to explore next. This allows allocation of computational resources to promising candidates, however, such decisions are non-differentiable. As a result, these algorithms are hard to train in an end-to-end fashion. In this work we propose to learn an efficient algorithm for the task of 6D object pose estimation. Our system optimizes the parameters of an existing state-of-the art pose estimation system using reinforcement learning, where the pose estimation system now becomes the stochastic policy, parametrized by a CNN. Additionally, we present an efficient training algorithm that dramatically reduces computation time. We show empirically that our learned pose estimation procedure makes better use of limited resources and improves upon the state-of-the-art on a challenging dataset. Our approach enables differentiable end-to-end training of complex algorithmic pipelines and learns to make optimal use of a given computational budget.
DeepCoder: Learning to Write Programs
Mar 08, 2017


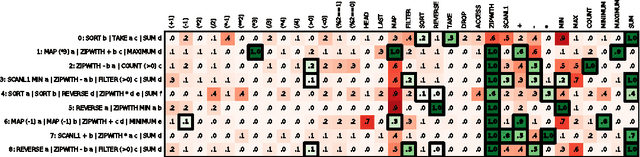
We develop a first line of attack for solving programming competition-style problems from input-output examples using deep learning. The approach is to train a neural network to predict properties of the program that generated the outputs from the inputs. We use the neural network's predictions to augment search techniques from the programming languages community, including enumerative search and an SMT-based solver. Empirically, we show that our approach leads to an order of magnitude speedup over the strong non-augmented baselines and a Recurrent Neural Network approach, and that we are able to solve problems of difficulty comparable to the simplest problems on programming competition websites.
Memory Lens: How Much Memory Does an Agent Use?
Nov 21, 2016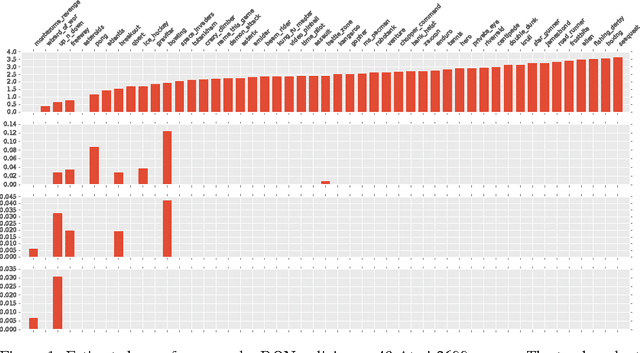
We propose a new method to study the internal memory used by reinforcement learning policies. We estimate the amount of relevant past information by estimating mutual information between behavior histories and the current action of an agent. We perform this estimation in the passive setting, that is, we do not intervene but merely observe the natural behavior of the agent. Moreover, we provide a theoretical justification for our approach by showing that it yields an implementation-independent lower bound on the minimal memory capacity of any agent that implement the observed policy. We demonstrate our approach by estimating the use of memory of DQN policies on concatenated Atari frames, demonstrating sharply different use of memory across 49 games. The study of memory as information that flows from the past to the current action opens avenues to understand and improve successful reinforcement learning algorithms.
Probabilistic Duality for Parallel Gibbs Sampling without Graph Coloring
Nov 21, 2016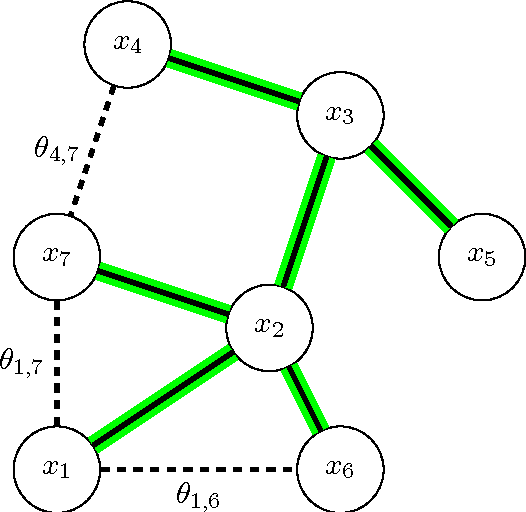
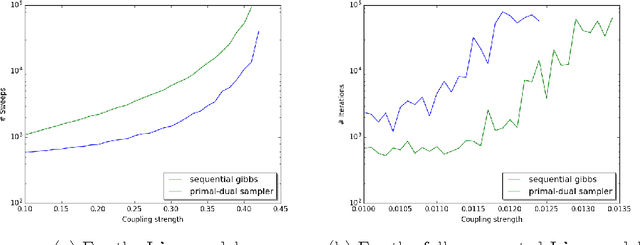
We present a new notion of probabilistic duality for random variables involving mixture distributions. Using this notion, we show how to implement a highly-parallelizable Gibbs sampler for weakly coupled discrete pairwise graphical models with strictly positive factors that requires almost no preprocessing and is easy to implement. Moreover, we show how our method can be combined with blocking to improve mixing. Even though our method leads to inferior mixing times compared to a sequential Gibbs sampler, we argue that our method is still very useful for large dynamic networks, where factors are added and removed on a continuous basis, as it is hard to maintain a graph coloring in this setup. Similarly, our method is useful for parallelizing Gibbs sampling in graphical models that do not allow for graph colorings with a small number of colors such as densely connected graphs.
DISCO Nets: DISsimilarity COefficient Networks
Oct 28, 2016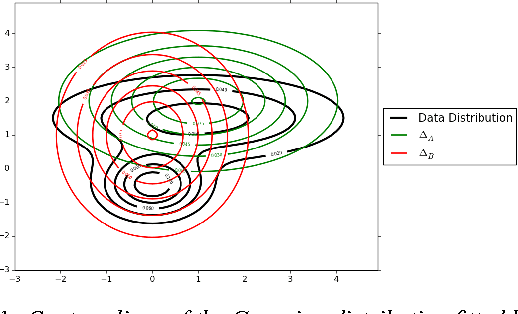
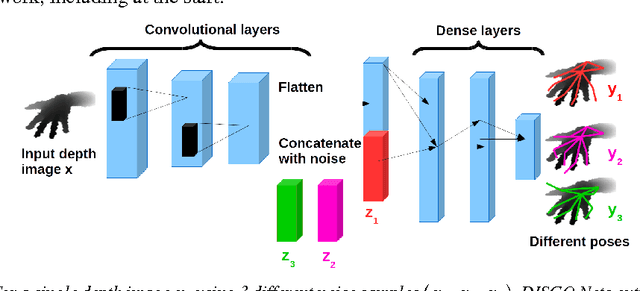


We present a new type of probabilistic model which we call DISsimilarity COefficient Networks (DISCO Nets). DISCO Nets allow us to efficiently sample from a posterior distribution parametrised by a neural network. During training, DISCO Nets are learned by minimising the dissimilarity coefficient between the true distribution and the estimated distribution. This allows us to tailor the training to the loss related to the task at hand. We empirically show that (i) by modeling uncertainty on the output value, DISCO Nets outperform equivalent non-probabilistic predictive networks and (ii) DISCO Nets accurately model the uncertainty of the output, outperforming existing probabilistic models based on deep neural networks.
f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization
Jun 02, 2016
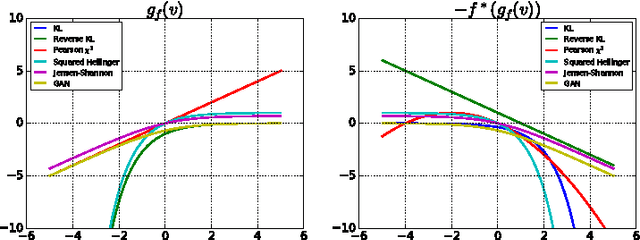


Generative neural samplers are probabilistic models that implement sampling using feedforward neural networks: they take a random input vector and produce a sample from a probability distribution defined by the network weights. These models are expressive and allow efficient computation of samples and derivatives, but cannot be used for computing likelihoods or for marginalization. The generative-adversarial training method allows to train such models through the use of an auxiliary discriminative neural network. We show that the generative-adversarial approach is a special case of an existing more general variational divergence estimation approach. We show that any f-divergence can be used for training generative neural samplers. We discuss the benefits of various choices of divergence functions on training complexity and the quality of the obtained generative models.
Bayesian Time-of-Flight for Realtime Shape, Illumination and Albedo
Jul 22, 2015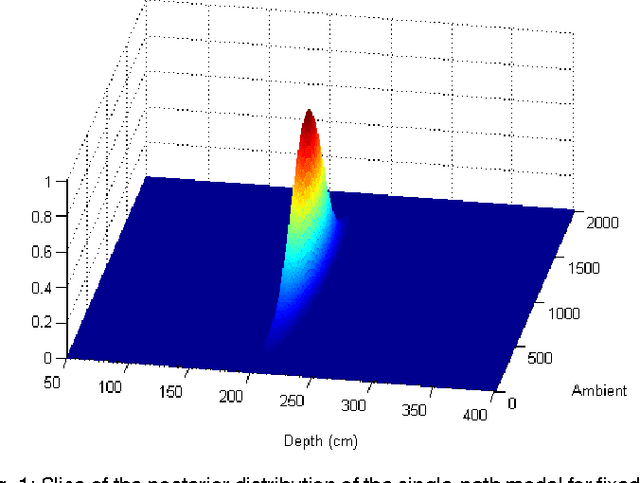
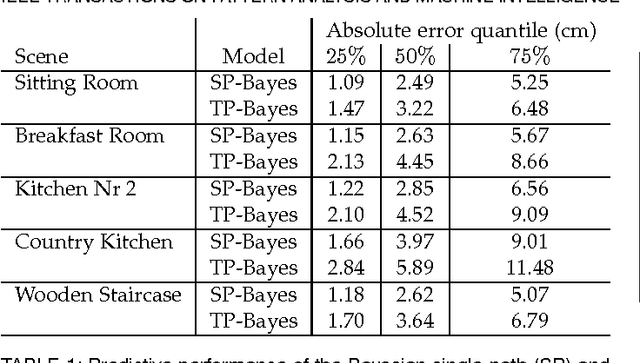
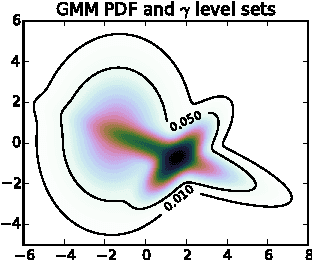
We propose a computational model for shape, illumination and albedo inference in a pulsed time-of-flight (TOF) camera. In contrast to TOF cameras based on phase modulation, our camera enables general exposure profiles. This results in added flexibility and requires novel computational approaches. To address this challenge we propose a generative probabilistic model that accurately relates latent imaging conditions to observed camera responses. While principled, realtime inference in the model turns out to be infeasible, and we propose to employ efficient non-parametric regression trees to approximate the model outputs. As a result we are able to provide, for each pixel, at video frame rate, estimates and uncertainty for depth, effective albedo, and ambient light intensity. These results we present are state-of-the-art in depth imaging. The flexibility of our approach allows us to easily enrich our generative model. We demonstrate that by extending the original single-path model to a two-path model, capable of describing some multipath effects. The new model is seamlessly integrated in the system at no additional computational cost. Our work also addresses the important question of optimal exposure design in pulsed TOF systems. Finally, for benchmark purposes and to obtain realistic empirical priors of multipath and insights into this phenomena, we propose a physically accurate simulation of multipath phenomena.