 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtuoso: Video-based Intelligence for real-time tuning on SOCs
Dec 24, 2021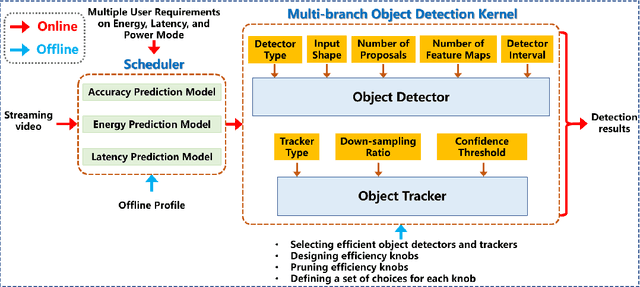
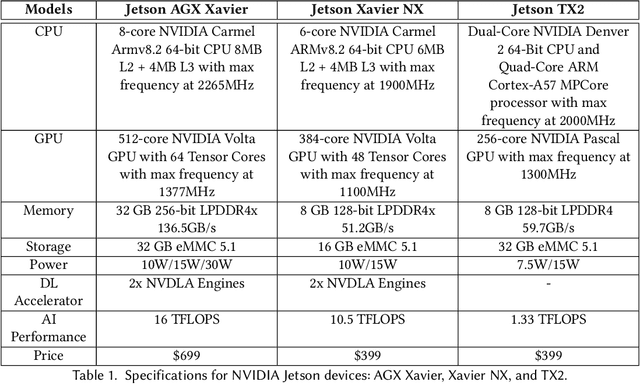
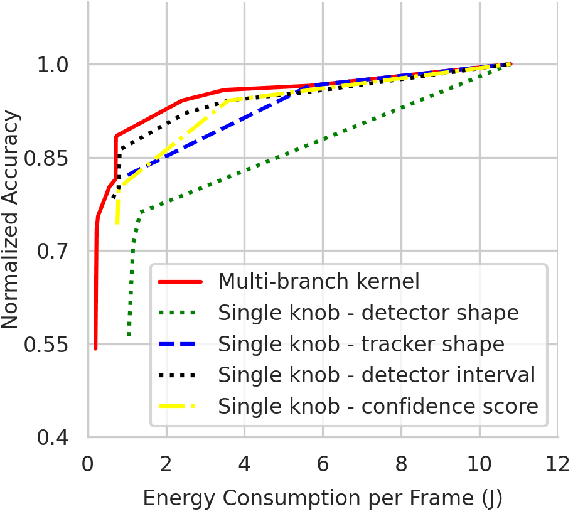
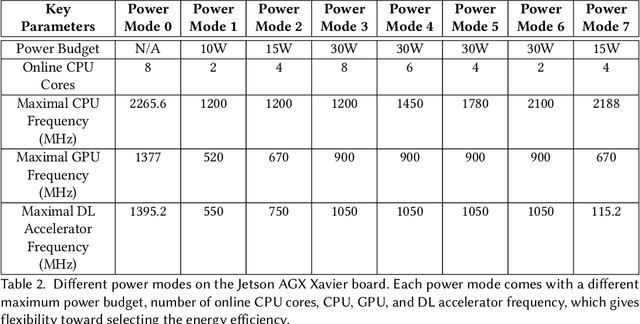
Efficient and adaptive computer vision systems have been proposed to make computer vision tasks, such as image classification and object detection, optimized for embedded or mobile devices. These solutions, quite recent in their origin, focus on optimizing the model (a deep neural network, DNN) or the system by designing an adaptive system with approximation knobs. In spite of several recent efforts, we show that existing solutions suffer from two major drawbacks. First, the system does not consider energy consumption of the models while making a decision on which model to run. Second, the evaluation does not consider the practical scenario of contention on the device, due to other co-resident workloads. In this work, we propose an efficient and adaptive video object detection system, Virtuoso, which is jointly optimized for accuracy, energy efficiency, and latency. Underlying Virtuoso is a multi-branch execution kernel that is capable of running at different operating points in the accuracy-energy-latency axes, and a lightweight runtime scheduler to select the best fit execution branch to satisfy the user requirement. To fairly compare with Virtuoso, we benchmark 15 state-of-the-art or widely used protocols, including Faster R-CNN (FRCNN), YOLO v3, SSD, EfficientDet, SELSA, MEGA, REPP, FastAdapt, and our in-house adaptive variants of FRCNN+, YOLO+, SSD+, and EfficientDet+ (our variants have enhanced efficiency for mobiles). With this comprehensive benchmark, Virtuoso has shown superiority to all the above protocols, leading the accuracy frontier at every efficiency level on NVIDIA Jetson mobile GPUs. Specifically, Virtuoso has achieved an accuracy of 63.9%, which is more than 10% higher than some of the popular object detection models, FRCNN at 51.1%, and YOLO at 49.5%.
TESSERACT: Gradient Flip Score to Secure Federated Learning Against Model Poisoning Attacks
Oct 19, 2021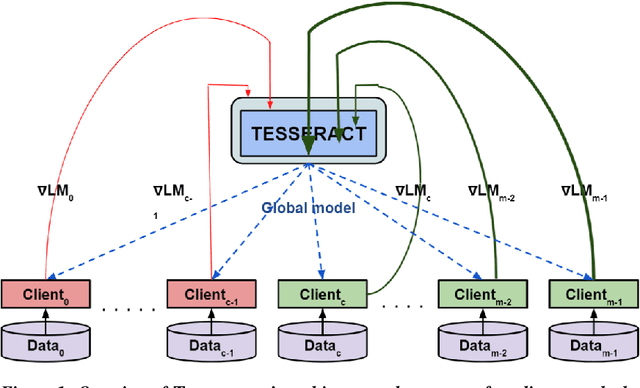

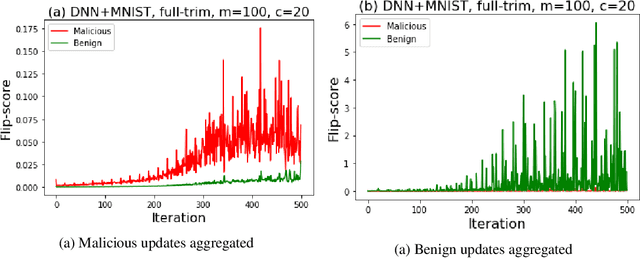
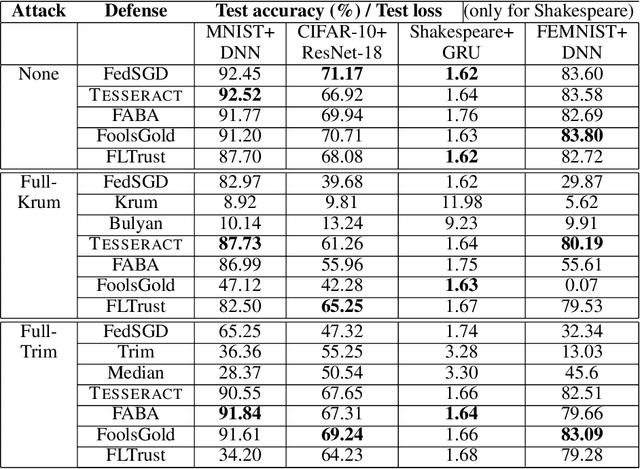
Federated learning---multi-party, distributed learning in a decentralized environment---is vulnerable to model poisoning attacks, even more so than centralized learning approaches. This is because malicious clients can collude and send in carefully tailored model updates to make the global model inaccurate. This motivated the development of Byzantine-resilient federated learning algorithms, such as Krum, Bulyan, FABA, and FoolsGold. However, a recently developed untargeted model poisoning attack showed that all prior defenses can be bypassed. The attack uses the intuition that simply by changing the sign of the gradient updates that the optimizer is computing, for a set of malicious clients, a model can be diverted from the optima to increase the test error rate. In this work, we develop TESSERACT---a defense against this directed deviation attack, a state-of-the-art model poisoning attack. TESSERACT is based on a simple intuition that in a federated learning setting, certain patterns of gradient flips are indicative of an attack. This intuition is remarkably stable across different learning algorithms, models, and datasets. TESSERACT assigns reputation scores to the participating clients based on their behavior during the training phase and then takes a weighted contribution of the clients. We show that TESSERACT provides robustness against even a white-box version of the attack.
Federated Action Recognition on Heterogeneous Embedded Devices
Jul 18, 2021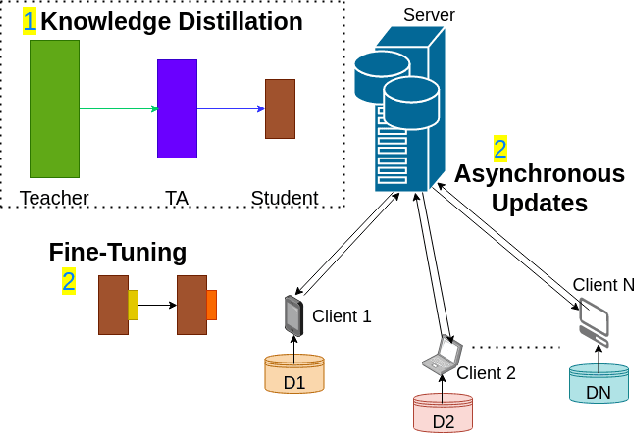
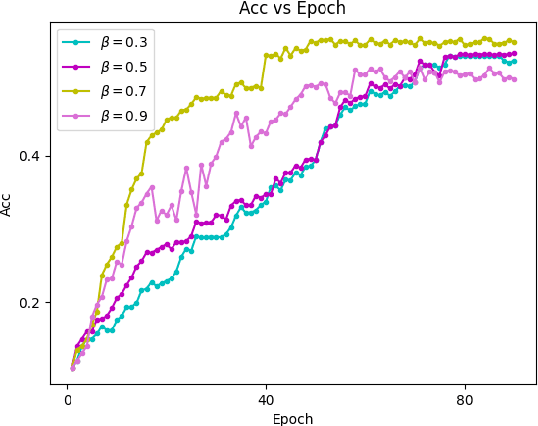
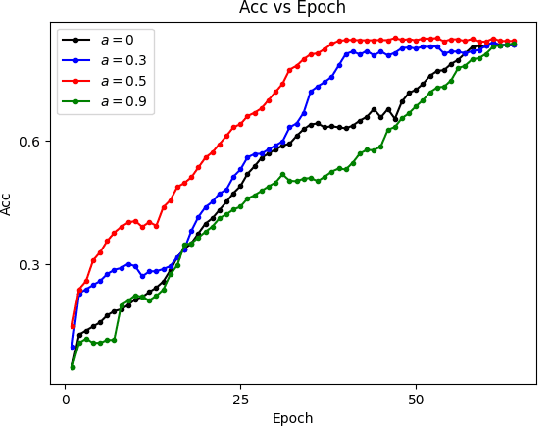
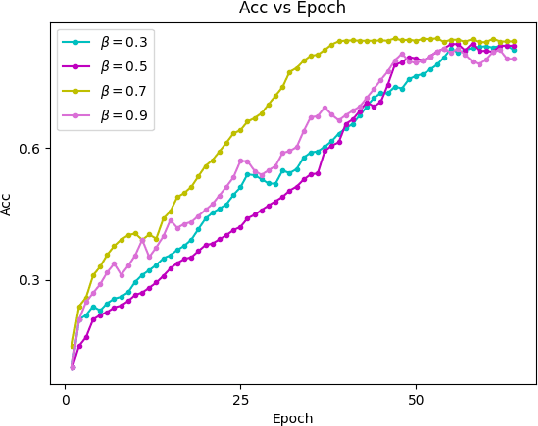
Federated learning allows a large number of devices to jointly learn a model without sharing data. In this work, we enable clients with limited computing power to perform action recognition, a computationally heavy task. We first perform model compression at the central server through knowledge distillation on a large dataset. This allows the model to learn complex features and serves as an initialization for model fine-tuning. The fine-tuning is required because the limited data present in smaller datasets is not adequate for action recognition models to learn complex spatio-temporal features. Because the clients present are often heterogeneous in their computing resources, we use an asynchronous federated optimization and we further show a convergence bound. We compare our approach to two baseline approaches: fine-tuning at the central server (no clients) and fine-tuning using (heterogeneous) clients using synchronous federated averaging. We empirically show on a testbed of heterogeneous embedded devices that we can perform action recognition with comparable accuracy to the two baselines above, while our asynchronous learning strategy reduces the training time by 40%, relative to synchronous learning.
* 13 pages, 12 figures
Feature Shift Detection: Localizing Which Features Have Shifted via Conditional Distribution Tests
Jul 14, 2021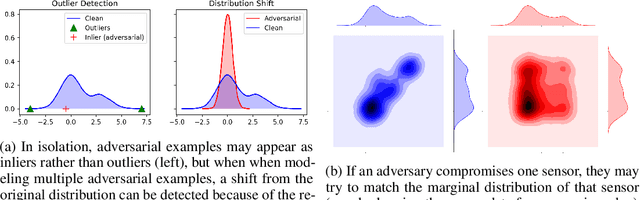
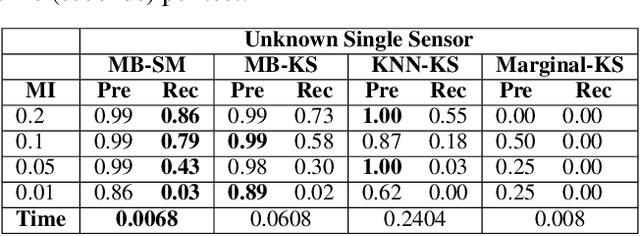
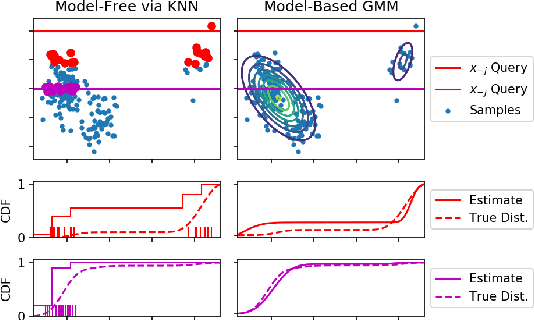

While previous distribution shift detection approaches can identify if a shift has occurred, these approaches cannot localize which specific features have caused a distribution shift -- a critical step in diagnosing or fixing any underlying issue. For example, in military sensor networks, users will want to detect when one or more of the sensors has been compromised, and critically, they will want to know which specific sensors might be compromised. Thus, we first define a formalization of this problem as multiple conditional distribution hypothesis tests and propose both non-parametric and parametric statistical tests. For both efficiency and flexibility, we then propose to use a test statistic based on the density model score function (i.e. gradient with respect to the input) -- which can easily compute test statistics for all dimensions in a single forward and backward pass. Any density model could be used for computing the necessary statistics including deep density models such as normalizing flows or autoregressive models. We additionally develop methods for identifying when and where a shift occurs in multivariate time-series data and show results for multiple scenarios using realistic attack models on both simulated and real world data.
* NeurIPS 2020 Camera Ready
Anomaly Detection through Transfer Learning in Agriculture and Manufacturing IoT Systems
Feb 11, 2021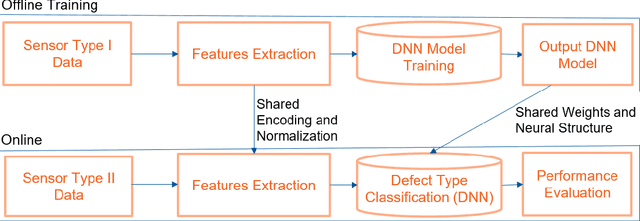
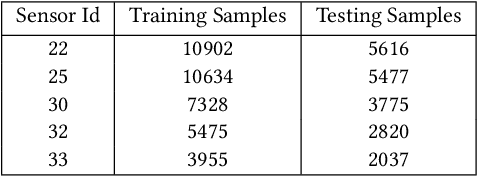
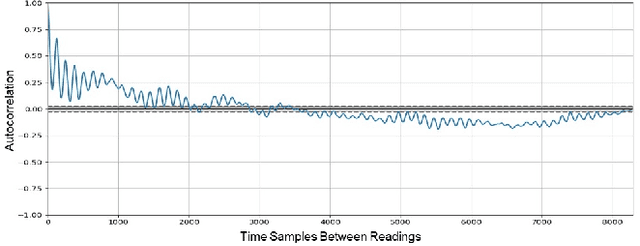
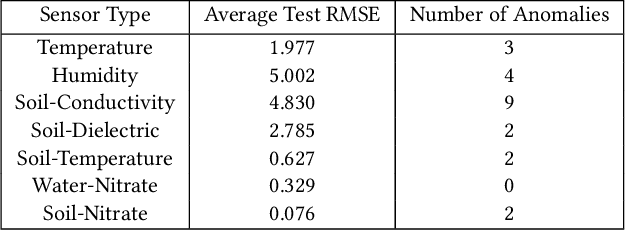
IoT systems have been facing increasingly sophisticated technical problems due to the growing complexity of these systems and their fast deployment practices. Consequently, IoT managers have to judiciously detect failures (anomalies) in order to reduce their cyber risk and operational cost. While there is a rich literature on anomaly detection in many IoT-based systems, there is no existing work that documents the use of ML models for anomaly detection in digital agriculture and in smart manufacturing systems. These two application domains pose certain salient technical challenges. In agriculture the data is often sparse, due to the vast areas of farms and the requirement to keep the cost of monitoring low. Second, in both domains, there are multiple types of sensors with varying capabilities and costs. The sensor data characteristics change with the operating point of the environment or machines, such as, the RPM of the motor. The inferencing and the anomaly detection processes therefore have to be calibrated for the operating point. In this paper, we analyze data from sensors deployed in an agricultural farm with data from seven different kinds of sensors, and from an advanced manufacturing testbed with vibration sensors. We evaluate the performance of ARIMA and LSTM models for predicting the time series of sensor data. Then, considering the sparse data from one kind of sensor, we perform transfer learning from a high data rate sensor. We then perform anomaly detection using the predicted sensor data. Taken together, we show how in these two application domains, predictive failure classification can be achieved, thus paving the way for predictive maintenance.
Exploring Adversarial Examples via Invertible Neural Networks
Dec 24, 2020

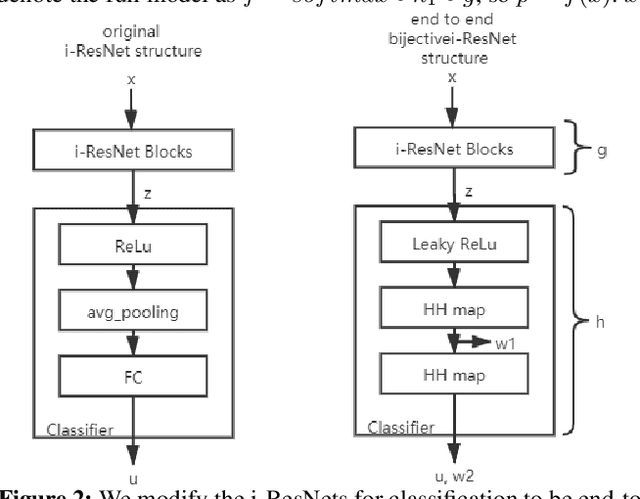

Adversarial examples (AEs) are images that can mislead deep neural network (DNN) classifiers via introducing slight perturbations into original images. This security vulnerability has led to vast research in recent years because it can introduce real-world threats into systems that rely on neural networks. Yet, a deep understanding of the characteristics of adversarial examples has remained elusive. We propose a new way of achieving such understanding through a recent development, namely, invertible neural models with Lipschitz continuous mapping functions from the input to the output. With the ability to invert any latent representation back to its corresponding input image, we can investigate adversarial examples at a deeper level and disentangle the adversarial example's latent representation. Given this new perspective, we propose a fast latent space adversarial example generation method that could accelerate adversarial training. Moreover, this new perspective could contribute to new ways of adversarial example detection.
Morshed: Guiding Behavioral Decision-Makers towards Better Security Investment in Interdependent Systems
Nov 22, 2020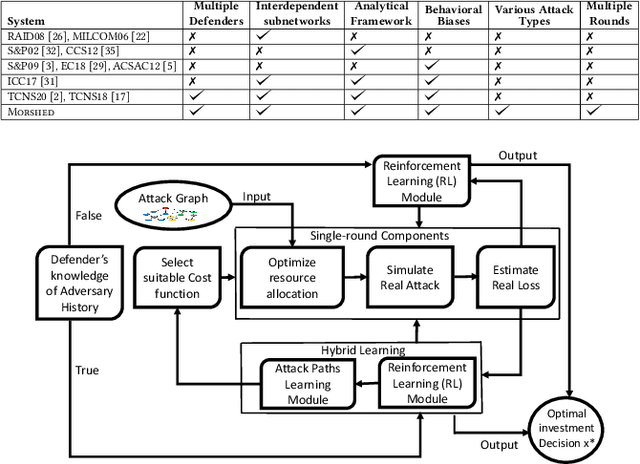
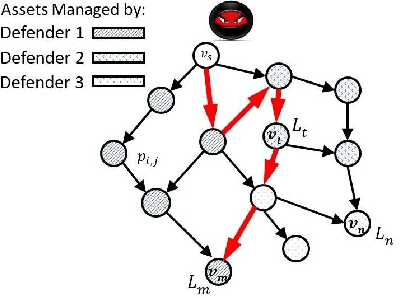

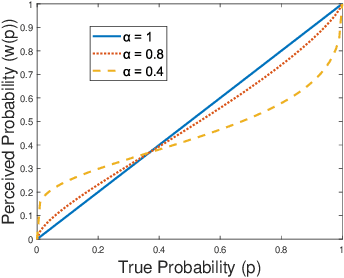
We model the behavioral biases of human decision-making in securing interdependent systems and show that such behavioral decision-making leads to a suboptimal pattern of resource allocation compared to non-behavioral (rational) decision-making. We provide empirical evidence for the existence of such behavioral bias model through a controlled subject study with 145 participants. We then propose three learning techniques for enhancing decision-making in multi-round setups. We illustrate the benefits of our decision-making model through multiple interdependent real-world systems and quantify the level of gain compared to the case in which the defenders are behavioral. We also show the benefit of our learning techniques against different attack models. We identify the effects of different system parameters on the degree of suboptimality of security outcomes due to behavioral decision-making.
ApproxDet: Content and Contention-Aware Approximate Object Detection for Mobiles
Oct 21, 2020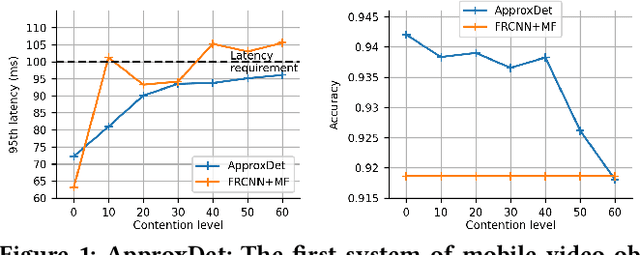
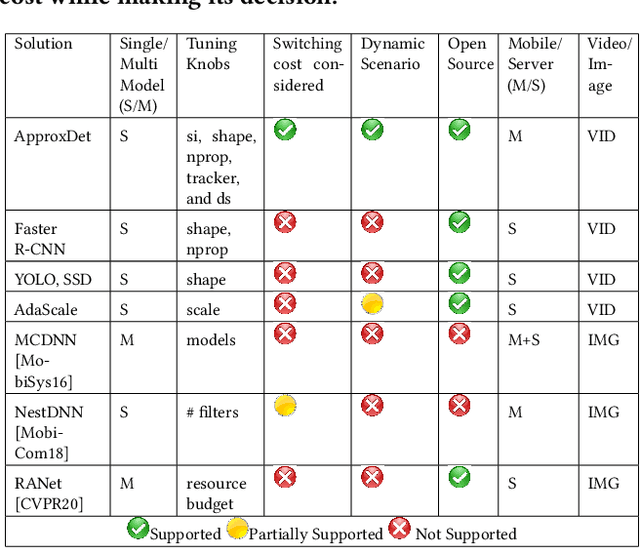
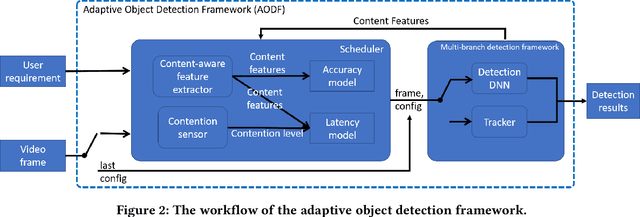

Advanced video analytic systems, including scene classification and object detection, have seen widespread success in various domains such as smart cities and autonomous transportation. With an ever-growing number of powerful client devices, there is incentive to move these heavy video analytics workloads from the cloud to mobile devices to achieve low latency and real-time processing and to preserve user privacy. However, most video analytic systems are heavyweight and are trained offline with some pre-defined latency or accuracy requirements. This makes them unable to adapt at runtime in the face of three types of dynamism -- the input video characteristics change, the amount of compute resources available on the node changes due to co-located applications, and the user's latency-accuracy requirements change. In this paper we introduce ApproxDet, an adaptive video object detection framework for mobile devices to meet accuracy-latency requirements in the face of changing content and resource contention scenarios. To achieve this, we introduce a multi-branch object detection kernel (layered on Faster R-CNN), which incorporates a data-driven modeling approach on the performance metrics, and a latency SLA-driven scheduler to pick the best execution branch at runtime. We couple this kernel with approximable video object tracking algorithms to create an end-to-end video object detection system. We evaluate ApproxDet on a large benchmark video dataset and compare quantitatively to AdaScale and YOLOv3. We find that ApproxDet is able to adapt to a wide variety of contention and content characteristics and outshines all baselines, e.g., it achieves 52% lower latency and 11.1% higher accuracy over YOLOv3.
Towards Generalized and Distributed Privacy-Preserving Representation Learning
Oct 17, 2020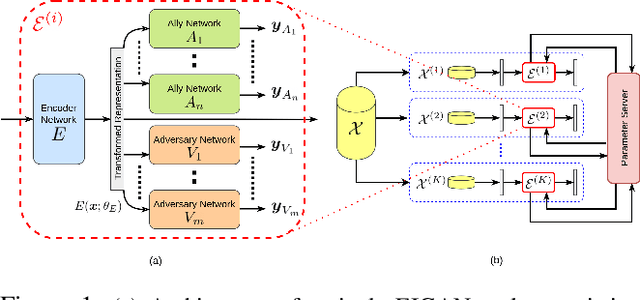
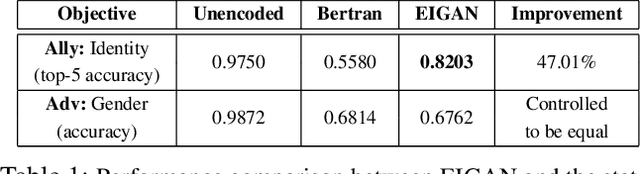
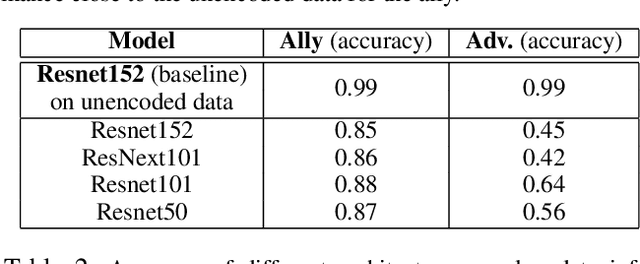
We study the problem of learning data representations that are private yet informative, i.e., providing information about intended "ally" targets while obfuscating sensitive "adversary" attributes. We propose a novel framework, Exclusion-Inclusion Generative Adversarial Network (EIGAN), that generalizes existing adversarial privacy-preserving representation learning (PPRL) approaches to generate data encodings that account for multiple possibly overlapping ally and adversary targets. Preserving privacy is even more difficult when the data is collected across multiple distributed nodes, which for privacy reasons may not wish to share their data even for PPRL training. Thus, learning such data representations at each node in a distributed manner (i.e., without transmitting source data) is of particular importance. This motivates us to develop D-EIGAN, the first distributed PPRL method, based on federated learning with fractional parameter sharing to account for communication resource limitations. We theoretically analyze the behavior of adversaries under the optimal EIGAN and D-EIGAN encoders and consider the impact of dependencies among ally and adversary tasks on the encoder performance. Our experiments on real-world and synthetic datasets demonstrate the advantages of EIGAN encodings in terms of accuracy, robustness, and scalability; in particular, we show that EIGAN outperforms the previous state-of-the-art by a significant accuracy margin (47% improvement). The experiments further reveal that D-EIGAN's performance is consistent with EIGAN under different node data distributions and is resilient to communication constraints.
Event-Triggered Distributed Inference
Apr 02, 2020
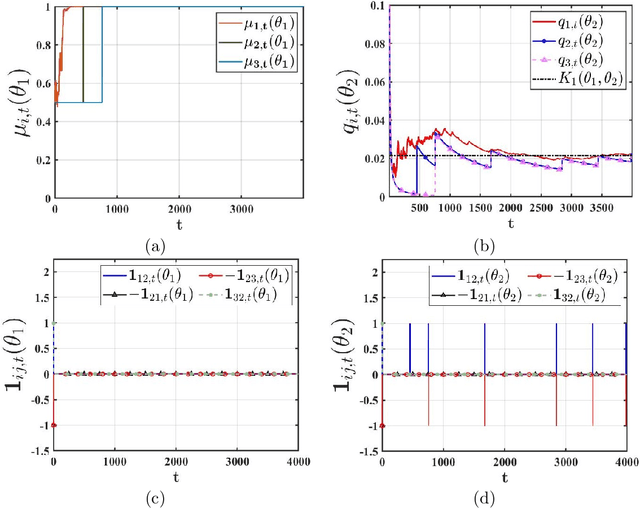
We study a setting where each agent in a network receives certain private signals generated by an unknown static state that belongs to a finite set of hypotheses. The agents are tasked with collectively identifying the true state. To solve this problem in a communication-efficient manner, we propose an event-triggered distributed learning algorithm that is based on the principle of diffusing low beliefs on each false hypothesis. Building on this principle, we design a trigger condition under which an agent broadcasts only those components of its belief vector that have adequate innovation, to only those neighbors that require such information. We establish that under standard assumptions, each agent learns the true state exponentially fast almost surely. We also identify sparse communication regimes where the inter-communication intervals grow unbounded, and yet, the asymptotic learning rate of our algorithm remains the same as the best known rate for this problem. We then establish, both in theory and via simulations, that our event-triggering strategy has the potential to significantly reduce information flow from uninformative agents to informative agents. Finally, we argue that, as far as only asymptotic learning is concerned, one can allow for arbitrarily sparse communication patterns.