 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Corner Patches: Semantics-Aware Backdoor Attack in Federated Learning
Mar 31, 2026Backdoor attacks on federated learning (FL) are most often evaluated with synthetic corner patches or out-of-distribution (OOD) patterns that are unlikely to arise in practice. In this paper, we revisit the backdoor threat to standard FL (a single global model) under a more realistic setting where triggers must be semantically meaningful, in-distribution, and visually plausible. We propose SABLE, a Semantics-Aware Backdoor for LEarning in federated settings, which constructs natural, content-consistent triggers (e.g., semantic attribute changes such as sunglasses) and optimizes an aggregation-aware malicious objective with feature separation and parameter regularization to keep attacker updates close to benign ones. We instantiate SABLE on CelebA hair-color classification and the German Traffic Sign Recognition Benchmark (GTSRB), poisoning only a small, interpretable subset of each malicious client's local data while otherwise following the standard FL protocol. Across heterogeneous client partitions and multiple aggregation rules (FedAvg, Trimmed Mean, MultiKrum, and FLAME), our semantics-driven triggers achieve high targeted attack success rates while preserving benign test accuracy. These results show that semantics-aligned backdoors remain a potent and practical threat in federated learning, and that robustness claims based solely on synthetic patch triggers can be overly optimistic.
TESSERACT: Gradient Flip Score to Secure Federated Learning Against Model Poisoning Attacks
Oct 19, 2021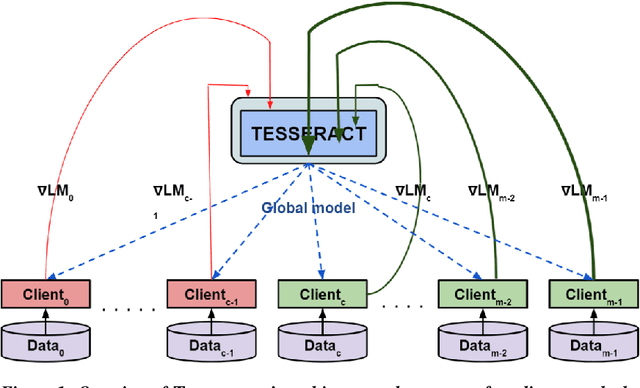

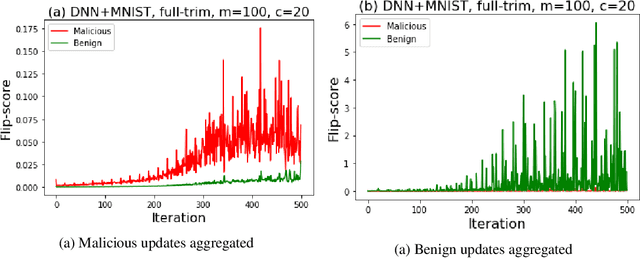
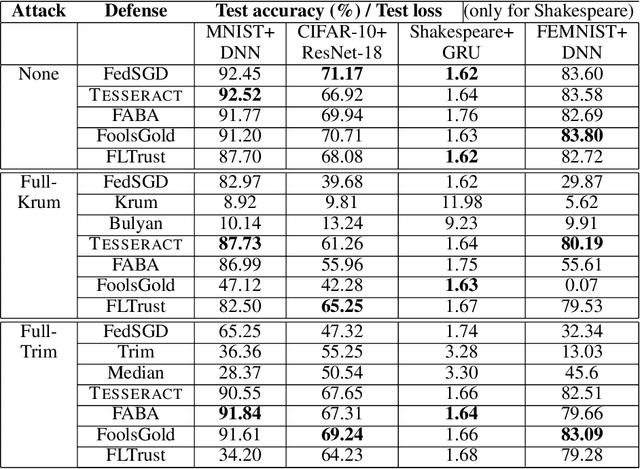
Federated learning---multi-party, distributed learning in a decentralized environment---is vulnerable to model poisoning attacks, even more so than centralized learning approaches. This is because malicious clients can collude and send in carefully tailored model updates to make the global model inaccurate. This motivated the development of Byzantine-resilient federated learning algorithms, such as Krum, Bulyan, FABA, and FoolsGold. However, a recently developed untargeted model poisoning attack showed that all prior defenses can be bypassed. The attack uses the intuition that simply by changing the sign of the gradient updates that the optimizer is computing, for a set of malicious clients, a model can be diverted from the optima to increase the test error rate. In this work, we develop TESSERACT---a defense against this directed deviation attack, a state-of-the-art model poisoning attack. TESSERACT is based on a simple intuition that in a federated learning setting, certain patterns of gradient flips are indicative of an attack. This intuition is remarkably stable across different learning algorithms, models, and datasets. TESSERACT assigns reputation scores to the participating clients based on their behavior during the training phase and then takes a weighted contribution of the clients. We show that TESSERACT provides robustness against even a white-box version of the attack.