 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the efficacy of LLM Safety Solutions : The Palit Benchmark Dataset
May 20, 2025Large Language Models (LLMs) are increasingly integrated into critical systems in industries like healthcare and finance. Users can often submit queries to LLM-enabled chatbots, some of which can enrich responses with information retrieved from internal databases storing sensitive data. This gives rise to a range of attacks in which a user submits a malicious query and the LLM-system outputs a response that creates harm to the owner, such as leaking internal data or creating legal liability by harming a third-party. While security tools are being developed to counter these threats, there is little formal evaluation of their effectiveness and usability. This study addresses this gap by conducting a thorough comparative analysis of LLM security tools. We identified 13 solutions (9 closed-source, 4 open-source), but only 7 were evaluated due to a lack of participation by proprietary model owners.To evaluate, we built a benchmark dataset of malicious prompts, and evaluate these tools performance against a baseline LLM model (ChatGPT-3.5-Turbo). Our results show that the baseline model has too many false positives to be used for this task. Lakera Guard and ProtectAI LLM Guard emerged as the best overall tools showcasing the tradeoff between usability and performance. The study concluded with recommendations for greater transparency among closed source providers, improved context-aware detections, enhanced open-source engagement, increased user awareness, and the adoption of more representative performance metrics.
Evaluatiing the efficacy of LLM Safety Solutions : The Palit Benchmark Dataset
May 19, 2025Large Language Models (LLMs) are increasingly integrated into critical systems in industries like healthcare and finance. Users can often submit queries to LLM-enabled chatbots, some of which can enrich responses with information retrieved from internal databases storing sensitive data. This gives rise to a range of attacks in which a user submits a malicious query and the LLM-system outputs a response that creates harm to the owner, such as leaking internal data or creating legal liability by harming a third-party. While security tools are being developed to counter these threats, there is little formal evaluation of their effectiveness and usability. This study addresses this gap by conducting a thorough comparative analysis of LLM security tools. We identified 13 solutions (9 closed-source, 4 open-source), but only 7 were evaluated due to a lack of participation by proprietary model owners.To evaluate, we built a benchmark dataset of malicious prompts, and evaluate these tools performance against a baseline LLM model (ChatGPT-3.5-Turbo). Our results show that the baseline model has too many false positives to be used for this task. Lakera Guard and ProtectAI LLM Guard emerged as the best overall tools showcasing the tradeoff between usability and performance. The study concluded with recommendations for greater transparency among closed source providers, improved context-aware detections, enhanced open-source engagement, increased user awareness, and the adoption of more representative performance metrics.
Morshed: Guiding Behavioral Decision-Makers towards Better Security Investment in Interdependent Systems
Nov 22, 2020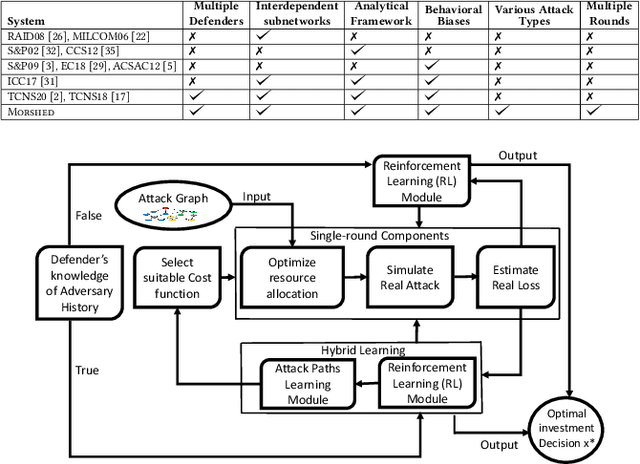
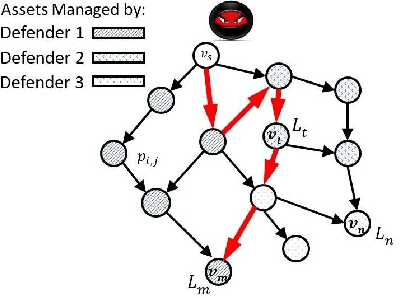

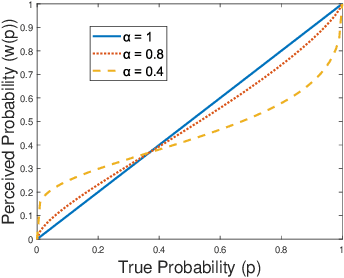
We model the behavioral biases of human decision-making in securing interdependent systems and show that such behavioral decision-making leads to a suboptimal pattern of resource allocation compared to non-behavioral (rational) decision-making. We provide empirical evidence for the existence of such behavioral bias model through a controlled subject study with 145 participants. We then propose three learning techniques for enhancing decision-making in multi-round setups. We illustrate the benefits of our decision-making model through multiple interdependent real-world systems and quantify the level of gain compared to the case in which the defenders are behavioral. We also show the benefit of our learning techniques against different attack models. We identify the effects of different system parameters on the degree of suboptimality of security outcomes due to behavioral decision-making.