 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Speech Translation Accuracy and Time Efficiency with Fine-tuned wav2vec 2.0-based Speech Segmentation
Apr 25, 2023Speech translation (ST) automatically converts utterances in a source language into text in another language. Splitting continuous speech into shorter segments, known as speech segmentation, plays an important role in ST. Recent segmentation methods trained to mimic the segmentation of ST corpora have surpassed traditional approaches. Tsiamas et al. proposed a segmentation frame classifier (SFC) based on a pre-trained speech encoder called wav2vec 2.0. Their method, named SHAS, retains 95-98% of the BLEU score for ST corpus segmentation. However, the segments generated by SHAS are very different from ST corpus segmentation and tend to be longer with multiple combined utterances. This is due to SHAS's reliance on length heuristics, i.e., it splits speech into segments of easily translatable length without fully considering the potential for ST improvement by splitting them into even shorter segments. Longer segments often degrade translation quality and ST's time efficiency. In this study, we extended SHAS to improve ST translation accuracy and efficiency by splitting speech into shorter segments that correspond to sentences. We introduced a simple segmentation algorithm using the moving average of SFC predictions without relying on length heuristics and explored wav2vec 2.0 fine-tuning for improved speech segmentation prediction. Our experimental results reveal that our speech segmentation method significantly improved the quality and the time efficiency of speech translation compared to SHAS.
NAIST-SIC-Aligned: Automatically-Aligned English-Japanese Simultaneous Interpretation Corpus
Apr 25, 2023It remains a question that how simultaneous interpretation (SI) data affects simultaneous machine translation (SiMT). Research has been limited due to the lack of a large-scale training corpus. In this work, we aim to fill in the gap by introducing NAIST-SIC-Aligned, which is an automatically-aligned parallel English-Japanese SI dataset. Starting with a non-aligned corpus NAIST-SIC, we propose a two-stage alignment approach to make the corpus parallel and thus suitable for model training. The first stage is coarse alignment where we perform a many-to-many mapping between source and target sentences, and the second stage is fine-grained alignment where we perform intra- and inter-sentence filtering to improve the quality of aligned pairs. To ensure the quality of the corpus, each step has been validated either quantitatively or qualitatively. This is the first open-sourced large-scale parallel SI dataset in the literature. We also manually curated a small test set for evaluation purposes. We hope our work advances research on SI corpora construction and SiMT. Please find our data at \url{https://github.com/mingzi151/AHC-SI}.
Sketch-based Medical Image Retrieval
Mar 07, 2023



The amount of medical images stored in hospitals is increasing faster than ever; however, utilizing the accumulated medical images has been limited. This is because existing content-based medical image retrieval (CBMIR) systems usually require example images to construct query vectors; nevertheless, example images cannot always be prepared. Besides, there can be images with rare characteristics that make it difficult to find similar example images, which we call isolated samples. Here, we introduce a novel sketch-based medical image retrieval (SBMIR) system that enables users to find images of interest without example images. The key idea lies in feature decomposition of medical images, whereby the entire feature of a medical image can be decomposed into and reconstructed from normal and abnormal features. By extending this idea, our SBMIR system provides an easy-to-use two-step graphical user interface: users first select a template image to specify a normal feature and then draw a semantic sketch of the disease on the template image to represent an abnormal feature. Subsequently, it integrates the two kinds of input to construct a query vector and retrieves reference images with the closest reference vectors. Using two datasets, ten healthcare professionals with various clinical backgrounds participated in the user test for evaluation. As a result, our SBMIR system enabled users to overcome previous challenges, including image retrieval based on fine-grained image characteristics, image retrieval without example images, and image retrieval for isolated samples. Our SBMIR system achieves flexible medical image retrieval on demand, thereby expanding the utility of medical image databases.
Modeling Multiple User Interests using Hierarchical Knowledge for Conversational Recommender System
Mar 01, 2023



A conversational recommender system (CRS) is a practical application for item recommendation through natural language conversation. Such a system estimates user interests for appropriate personalized recommendations. Users sometimes have various interests in different categories or genres, but existing studies assume a unique user interest that can be covered by closely related items. In this work, we propose to model such multiple user interests in CRS. We investigated its effects in experiments using the ReDial dataset and found that the proposed method can recommend a wider variety of items than that of the baseline CR-Walker.
Whats New? Identifying the Unfolding of New Events in Narratives
Feb 20, 2023
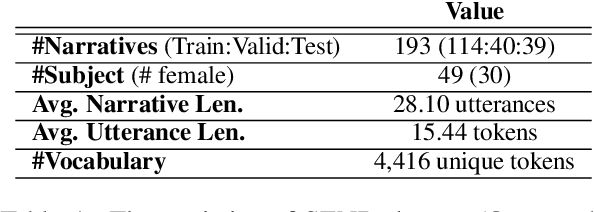
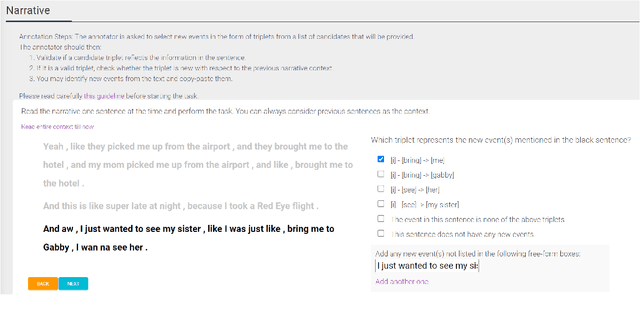
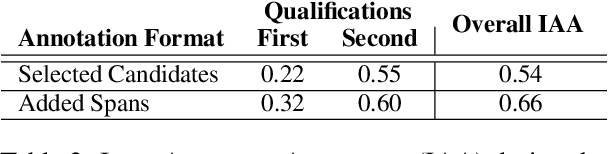
Narratives include a rich source of events unfolding over time and context. Automatic understanding of these events may provide a summarised comprehension of the narrative for further computation (such as reasoning). In this paper, we study the Information Status (IS) of the events and propose a novel challenging task: the automatic identification of new events in a narrative. We define an event as a triplet of subject, predicate, and object. The event is categorized as new with respect to the discourse context and whether it can be inferred through commonsense reasoning. We annotated a publicly available corpus of narratives with the new events at sentence level using human annotators. We present the annotation protocol and a study aiming at validating the quality of the annotation and the difficulty of the task. We publish the annotated dataset, annotation materials, and machine learning baseline models for the task of new event extraction for narrative understanding.
Evaluating the Robustness of Discrete Prompts
Feb 11, 2023



Discrete prompts have been used for fine-tuning Pre-trained Language Models for diverse NLP tasks. In particular, automatic methods that generate discrete prompts from a small set of training instances have reported superior performance. However, a closer look at the learnt prompts reveals that they contain noisy and counter-intuitive lexical constructs that would not be encountered in manually-written prompts. This raises an important yet understudied question regarding the robustness of automatically learnt discrete prompts when used in downstream tasks. To address this question, we conduct a systematic study of the robustness of discrete prompts by applying carefully designed perturbations into an application using AutoPrompt and then measure their performance in two Natural Language Inference (NLI) datasets. Our experimental results show that although the discrete prompt-based method remains relatively robust against perturbations to NLI inputs, they are highly sensitive to other types of perturbations such as shuffling and deletion of prompt tokens. Moreover, they generalize poorly across different NLI datasets. We hope our findings will inspire future work on robust discrete prompt learning.
SpeeChain: A Speech Toolkit for Large-Scale Machine Speech Chain
Jan 08, 2023This paper introduces SpeeChain, an open-source Pytorch-based toolkit designed to develop the machine speech chain for large-scale use. This first release focuses on the TTS-to-ASR chain, a core component of the machine speech chain, that refers to the TTS data augmentation by unspoken text for ASR. To build an efficient pipeline for the large-scale TTS-to-ASR chain, we implement easy-to-use multi-GPU batch-level model inference, multi-dataloader batch generation, and on-the-fly data selection techniques. In this paper, we first explain the overall procedure of the TTS-to-ASR chain and the difficulties of each step. Then, we present a detailed ablation study on different types of unlabeled data, data filtering thresholds, batch composition, and real-synthetic data ratios. Our experimental results on train_clean_460 of LibriSpeech demonstrate that our TTS-to-ASR chain can significantly improve WER in a semi-supervised setting.
Instance-level Heterogeneous Domain Adaptation for Limited-labeled Sketch-to-Photo Retrieval
Dec 06, 2022Although sketch-to-photo retrieval has a wide range of applications, it is costly to obtain paired and rich-labeled ground truth. Differently, photo retrieval data is easier to acquire. Therefore, previous works pre-train their models on rich-labeled photo retrieval data (i.e., source domain) and then fine-tune them on the limited-labeled sketch-to-photo retrieval data (i.e., target domain). However, without co-training source and target data, source domain knowledge might be forgotten during the fine-tuning process, while simply co-training them may cause negative transfer due to domain gaps. Moreover, identity label spaces of source data and target data are generally disjoint and therefore conventional category-level Domain Adaptation (DA) is not directly applicable. To address these issues, we propose an Instance-level Heterogeneous Domain Adaptation (IHDA) framework. We apply the fine-tuning strategy for identity label learning, aiming to transfer the instance-level knowledge in an inductive transfer manner. Meanwhile, labeled attributes from the source data are selected to form a shared label space for source and target domains. Guided by shared attributes, DA is utilized to bridge cross-dataset domain gaps and heterogeneous domain gaps, which transfers instance-level knowledge in a transductive transfer manner. Experiments show that our method has set a new state of the art on three sketch-to-photo image retrieval benchmarks without extra annotations, which opens the door to train more effective models on limited-labeled heterogeneous image retrieval tasks. Related codes are available at https://github.com/fandulu/IHDA.
Average Token Delay: A Latency Metric for Simultaneous Translation
Nov 22, 2022Simultaneous translation is a task in which translation begins before the speaker has finished speaking. In its evaluation, we have to consider the latency of the translation in addition to the quality. The latency is preferably as small as possible for users to comprehend what the speaker says with a small delay. Existing latency metrics focus on when the translation starts but do not consider adequately when the translation ends. This means such metrics do not penalize the latency caused by a long translation output, which actually delays users' comprehension. In this work, we propose a novel latency evaluation metric called Average Token Delay (ATD) that focuses on the end timings of partial translations in simultaneous translation. We discuss the advantage of ATD using simulated examples and also investigate the differences between ATD and Average Lagging with simultaneous translation experiments.
E2E Refined Dataset
Nov 01, 2022



Although the well-known MR-to-text E2E dataset has been used by many researchers, its MR-text pairs include many deletion/insertion/substitution errors. Since such errors affect the quality of MR-to-text systems, they must be fixed as much as possible. Therefore, we developed a refined dataset and some python programs that convert the original E2E dataset into a refined dataset.