 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 9: Detecting Multilingual, Multicultural and Multievent Online Polarization
Apr 08, 2026We present SemEval-2026 Task 9, a shared task on online polarization detection, covering 22 languages and comprising over 110K annotated instances. Each data instance is multi-labeled with the presence of polarization, polarization type, and polarization manifestation. Participants were asked to predict labels in three sub-tasks: (1) detecting the presence of polarization, (2) identifying the type of polarization, and (3) recognizing the polarization manifestation. The three tasks attracted over 1,000 participants worldwide and more than 10k submission on Codabench. We received final submissions from 67 teams and 73 system description papers. We report the baseline results and analyze the performance of the best-performing systems, highlighting the most common approaches and the most effective methods across different subtasks and languages. The dataset of this task is publicly available.
POLAR: A Benchmark for Multilingual, Multicultural, and Multi-Event Online Polarization
May 27, 2025Online polarization poses a growing challenge for democratic discourse, yet most computational social science research remains monolingual, culturally narrow, or event-specific. We introduce POLAR, a multilingual, multicultural, and multievent dataset with over 23k instances in seven languages from diverse online platforms and real-world events. Polarization is annotated along three axes: presence, type, and manifestation, using a variety of annotation platforms adapted to each cultural context. We conduct two main experiments: (1) we fine-tune six multilingual pretrained language models in both monolingual and cross-lingual setups; and (2) we evaluate a range of open and closed large language models (LLMs) in few-shot and zero-shot scenarios. Results show that while most models perform well on binary polarization detection, they achieve substantially lower scores when predicting polarization types and manifestations. These findings highlight the complex, highly contextual nature of polarization and the need for robust, adaptable approaches in NLP and computational social science. All resources will be released to support further research and effective mitigation of digital polarization globally.
Learning Graph Embeddings from WordNet-based Similarity Measures
Aug 17, 2018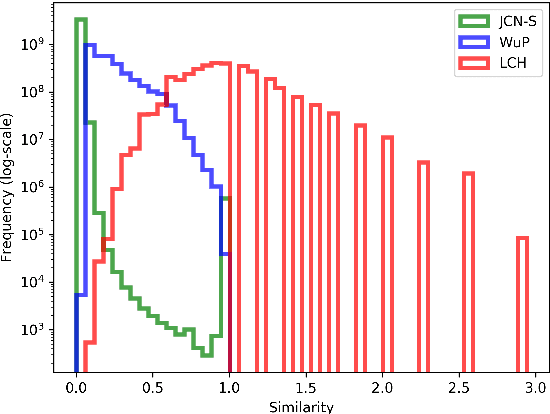
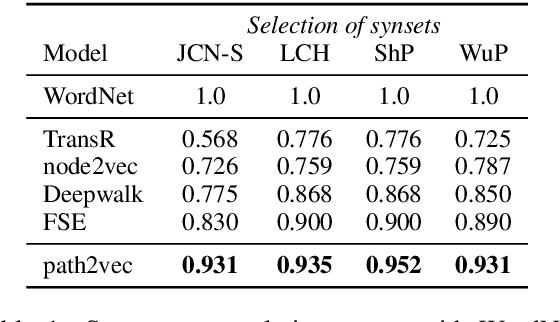
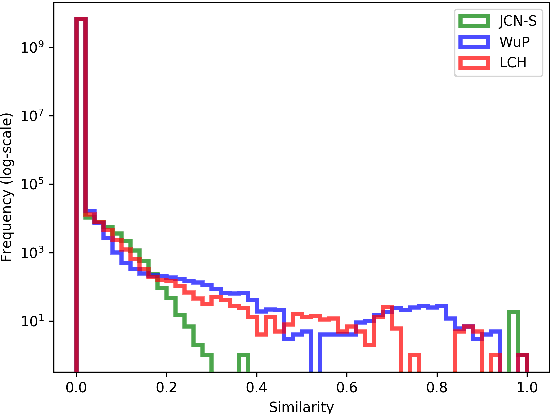
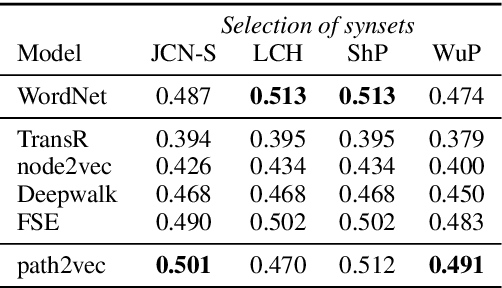
We present a new approach for learning graph embeddings, that relies on structural measures of node similarities for generation of training data. The model learns node embeddings that are able to approximate a given measure, such as the shortest path distance or any other. Evaluations of the proposed model on semantic similarity and word sense disambiguation tasks (using WordNet as the source of gold similarities) show that our method yields state-of-the-art results, but also is capable in certain cases to yield even better performance than the input similarity measure. The model is computationally efficient, orders of magnitude faster than the direct computation of graph distances.
Combining Graph-based Dependency Features with Convolutional Neural Network for Answer Triggering
Aug 05, 2018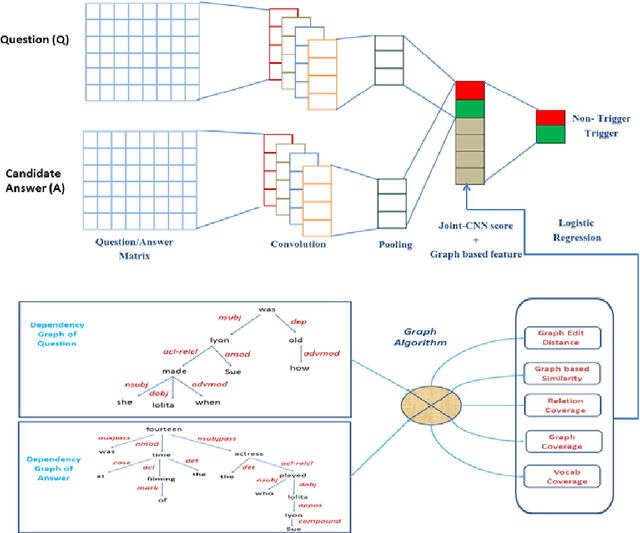

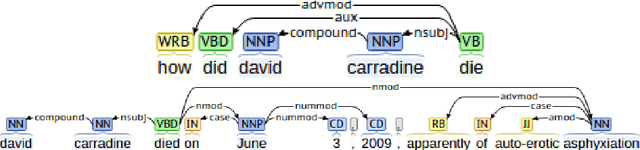
Answer triggering is the task of selecting the best-suited answer for a given question from a set of candidate answers if exists. In this paper, we present a hybrid deep learning model for answer triggering, which combines several dependency graph based alignment features, namely graph edit distance, graph-based similarity and dependency graph coverage, with dense vector embeddings from a Convolutional Neural Network (CNN). Our experiments on the WikiQA dataset show that such a combination can more accurately trigger a candidate answer compared to the previous state-of-the-art models. Comparative study on WikiQA dataset shows 5.86% absolute F-score improvement at the question level.