 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Fast Graph-based Algorithms with Graph Metric Embeddings
Jun 17, 2019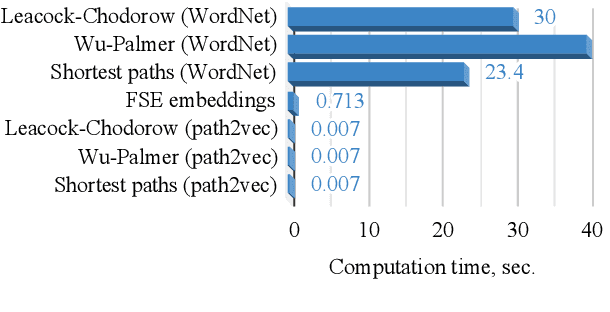
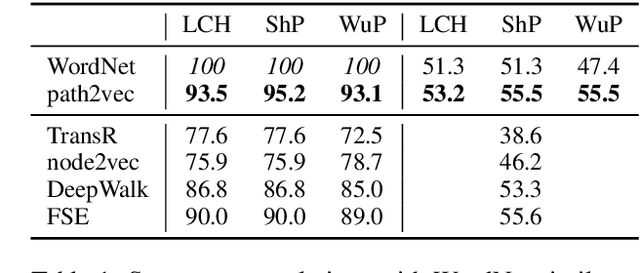
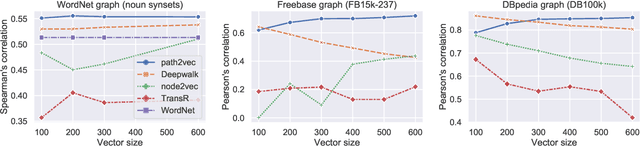
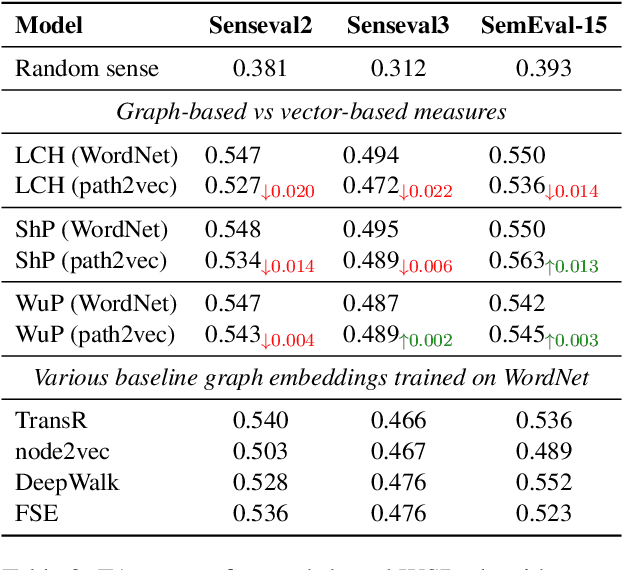
The computation of distance measures between nodes in graphs is inefficient and does not scale to large graphs. We explore dense vector representations as an effective way to approximate the same information: we introduce a simple yet efficient and effective approach for learning graph embeddings. Instead of directly operating on the graph structure, our method takes structural measures of pairwise node similarities into account and learns dense node representations reflecting user-defined graph distance measures, such as e.g.the shortest path distance or distance measures that take information beyond the graph structure into account. We demonstrate a speed-up of several orders of magnitude when predicting word similarity by vector operations on our embeddings as opposed to directly computing the respective path-based measures, while outperforming various other graph embeddings on semantic similarity and word sense disambiguation tasks and show evaluations on the WordNet graph and two knowledge base graphs.
Learning Graph Embeddings from WordNet-based Similarity Measures
Aug 17, 2018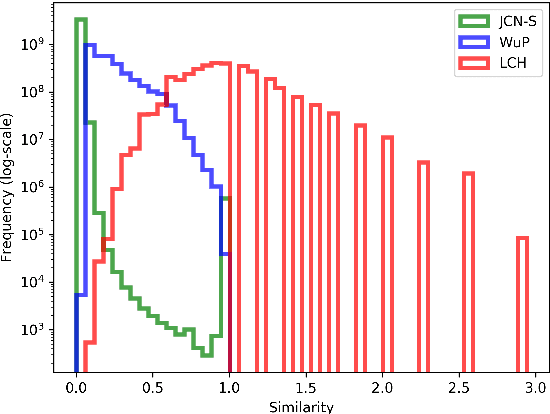
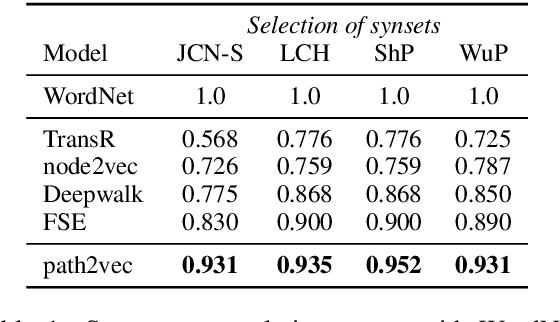
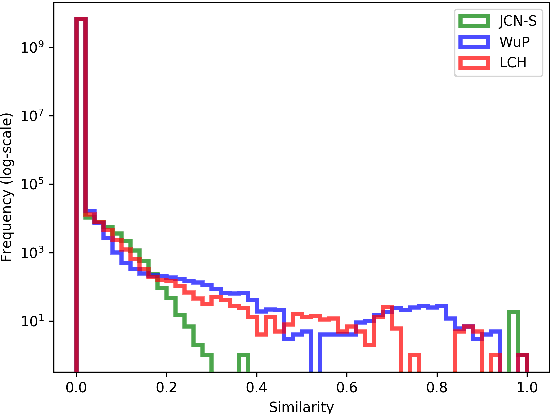
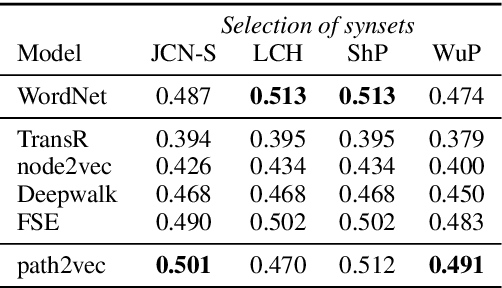
We present a new approach for learning graph embeddings, that relies on structural measures of node similarities for generation of training data. The model learns node embeddings that are able to approximate a given measure, such as the shortest path distance or any other. Evaluations of the proposed model on semantic similarity and word sense disambiguation tasks (using WordNet as the source of gold similarities) show that our method yields state-of-the-art results, but also is capable in certain cases to yield even better performance than the input similarity measure. The model is computationally efficient, orders of magnitude faster than the direct computation of graph distances.