 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual vs Crosslingual Retrieval of Fact-Checked Claims: A Tale of Two Approaches
May 28, 2025



Retrieval of previously fact-checked claims is a well-established task, whose automation can assist professional fact-checkers in the initial steps of information verification. Previous works have mostly tackled the task monolingually, i.e., having both the input and the retrieved claims in the same language. However, especially for languages with a limited availability of fact-checks and in case of global narratives, such as pandemics, wars, or international politics, it is crucial to be able to retrieve claims across languages. In this work, we examine strategies to improve the multilingual and crosslingual performance, namely selection of negative examples (in the supervised) and re-ranking (in the unsupervised setting). We evaluate all approaches on a dataset containing posts and claims in 47 languages (283 language combinations). We observe that the best results are obtained by using LLM-based re-ranking, followed by fine-tuning with negative examples sampled using a sentence similarity-based strategy. Most importantly, we show that crosslinguality is a setup with its own unique characteristics compared to the multilingual setup.
EventNet-ITA: Italian Frame Parsing for Events
May 18, 2023This paper introduces EventNet-ITA, a large, multi-domain corpus annotated with event frames for Italian, and presents an efficient approach for multi-label Frame Parsing. The approach is then evaluated on the dataset. Covering a wide range of individual, social and historical phenomena, the main contribution of EventNet-ITA is to provide the research community with a resource for textual event mining and a novel and extensive tool for Frame Parsing in Italian.
Providing Advanced Access to Historical War Memoirs Through the Identification of Events, Participants and Roles
Apr 08, 2019

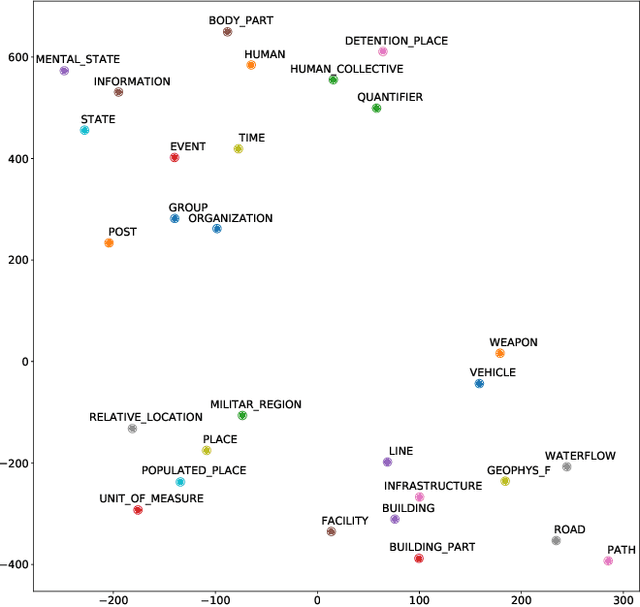
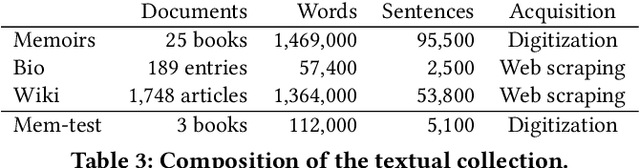
The progressive digitization of historical archives provides new, often domain specific, textual resources that report on facts and events happened in the past; among them, memoirs are a very common type of primary source. In this paper, we present an approach for extracting information from historical war memoirs and turning it into structured knowledge. This is based on the semantic notions of events, participants and roles. We assess quantitatively each of the key-steps of our approach and provide a graph-based representation of the extracted knowledge, which allows the end user to move between close and distant reading of the collection.