 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoom Impulse Response Generation Conditioned on Acoustic Parameters
Jul 16, 2025The generation of room impulse responses (RIRs) using deep neural networks has attracted growing research interest due to its applications in virtual and augmented reality, audio postproduction, and related fields. Most existing approaches condition generative models on physical descriptions of a room, such as its size, shape, and surface materials. However, this reliance on geometric information limits their usability in scenarios where the room layout is unknown or when perceptual realism (how a space sounds to a listener) is more important than strict physical accuracy. In this study, we propose an alternative strategy: conditioning RIR generation directly on a set of RIR acoustic parameters. These parameters include various measures of reverberation time and direct sound to reverberation ratio, both broadband and bandwise. By specifying how the space should sound instead of how it should look, our method enables more flexible and perceptually driven RIR generation. We explore both autoregressive and non-autoregressive generative models operating in the Descript Audio Codec domain, using either discrete token sequences or continuous embeddings. Specifically, we have selected four models to evaluate: an autoregressive transformer, the MaskGIT model, a flow matching model, and a classifier-based approach. Objective and subjective evaluations are performed to compare these methods with state-of-the-art alternatives. Results show that the proposed models match or outperform state-of-the-art alternatives, with the MaskGIT model achieving the best performance.
Single-stage TTS with Masked Audio Token Modeling and Semantic Knowledge Distillation
Sep 17, 2024



Audio token modeling has become a powerful framework for speech synthesis, with two-stage approaches employing semantic tokens remaining prevalent. In this paper, we aim to simplify this process by introducing a semantic knowledge distillation method that enables high-quality speech generation in a single stage. Our proposed model improves speech quality, intelligibility, and speaker similarity compared to a single-stage baseline. Although two-stage systems still lead in intelligibility, our model significantly narrows the gap while delivering comparable speech quality. These findings showcase the potential of single-stage models to achieve efficient, high-quality TTS with a more compact and streamlined architecture.
Antidote: Post-fine-tuning Safety Alignment for Large Language Models against Harmful Fine-tuning
Aug 18, 2024



Safety aligned Large Language Models (LLMs) are vulnerable to harmful fine-tuning attacks \cite{qi2023fine}-- a few harmful data mixed in the fine-tuning dataset can break the LLMs's safety alignment. Existing mitigation strategies include alignment stage solutions \cite{huang2024vaccine, rosati2024representation} and fine-tuning stage solutions \cite{huang2024lazy,mukhoti2023fine}. However, our evaluation shows that both categories of defenses fail \textit{when some specific training hyper-parameters are chosen} -- a large learning rate or a large number of training epochs in the fine-tuning stage can easily invalidate the defense, which however, is necessary to guarantee finetune performance. To this end, we propose Antidote, a post-fine-tuning stage solution, which remains \textbf{\textit{agnostic to the training hyper-parameters in the fine-tuning stage}}. Antidote relies on the philosophy that by removing the harmful parameters, the harmful model can be recovered from the harmful behaviors, regardless of how those harmful parameters are formed in the fine-tuning stage. With this philosophy, we introduce a one-shot pruning stage after harmful fine-tuning to remove the harmful weights that are responsible for the generation of harmful content. Despite its embarrassing simplicity, empirical results show that Antidote can reduce harmful score while maintaining accuracy on downstream tasks.
CLIPSonic: Text-to-Audio Synthesis with Unlabeled Videos and Pretrained Language-Vision Models
Jun 16, 2023



Recent work has studied text-to-audio synthesis using large amounts of paired text-audio data. However, audio recordings with high-quality text annotations can be difficult to acquire. In this work, we approach text-to-audio synthesis using unlabeled videos and pretrained language-vision models. We propose to learn the desired text-audio correspondence by leveraging the visual modality as a bridge. We train a conditional diffusion model to generate the audio track of a video, given a video frame encoded by a pretrained contrastive language-image pretraining (CLIP) model. At test time, we first explore performing a zero-shot modality transfer and condition the diffusion model with a CLIP-encoded text query. However, we observe a noticeable performance drop with respect to image queries. To close this gap, we further adopt a pretrained diffusion prior model to generate a CLIP image embedding given a CLIP text embedding. Our results show the effectiveness of the proposed method, and that the pretrained diffusion prior can reduce the modality transfer gap. While we focus on text-to-audio synthesis, the proposed model can also generate audio from image queries, and it shows competitive performance against a state-of-the-art image-to-audio synthesis model in a subjective listening test. This study offers a new direction of approaching text-to-audio synthesis that leverages the naturally-occurring audio-visual correspondence in videos and the power of pretrained language-vision models.
Full-band General Audio Synthesis with Score-based Diffusion
Oct 26, 2022Recent works have shown the capability of deep generative models to tackle general audio synthesis from a single label, producing a variety of impulsive, tonal, and environmental sounds. Such models operate on band-limited signals and, as a result of an autoregressive approach, they are typically conformed by pre-trained latent encoders and/or several cascaded modules. In this work, we propose a diffusion-based generative model for general audio synthesis, named DAG, which deals with full-band signals end-to-end in the waveform domain. Results show the superiority of DAG over existing label-conditioned generators in terms of both quality and diversity. More specifically, when compared to the state of the art, the band-limited and full-band versions of DAG achieve relative improvements that go up to 40 and 65%, respectively. We believe DAG is flexible enough to accommodate different conditioning schemas while providing good quality synthesis.
Generative Adversarial Speaker Embedding Networks for Domain Robust End-to-End Speaker Verification
Nov 07, 2018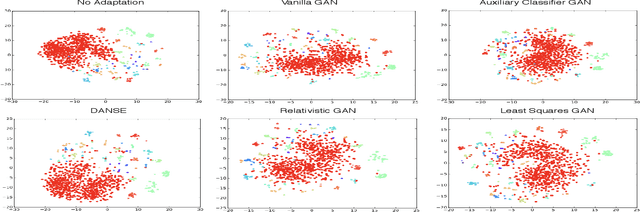
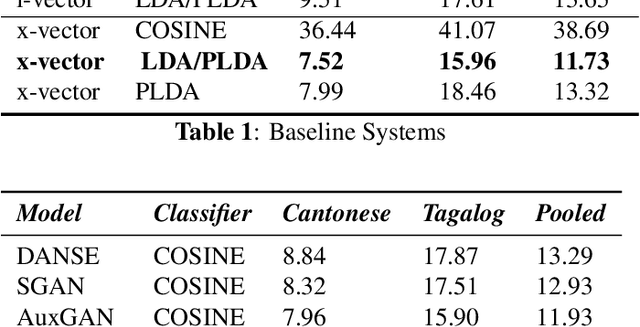
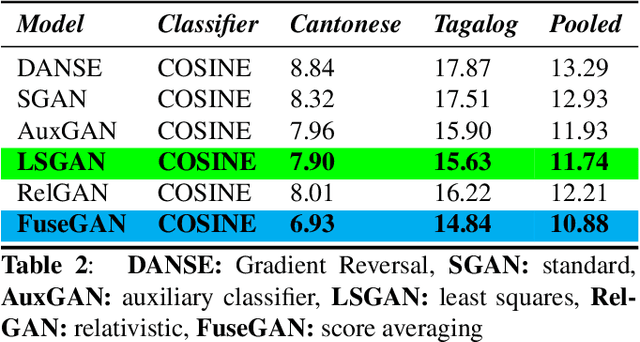
This article presents a novel approach for learning domain-invariant speaker embeddings using Generative Adversarial Networks. The main idea is to confuse a domain discriminator so that is can't tell if embeddings are from the source or target domains. We train several GAN variants using our proposed framework and apply them to the speaker verification task. On the challenging NIST-SRE 2016 dataset, we are able to match the performance of a strong baseline x-vector system. In contrast to the the baseline systems which are dependent on dimensionality reduction (LDA) and an external classifier (PLDA), our proposed speaker embeddings can be scored using simple cosine distance. This is achieved by optimizing our models end-to-end, using an angular margin loss function. Furthermore, we are able to significantly boost verification performance by averaging our different GAN models at the score level, achieving a relative improvement of 7.2% over the baseline.
Adapting End-to-End Neural Speaker Verification to New Languages and Recording Conditions with Adversarial Training
Nov 07, 2018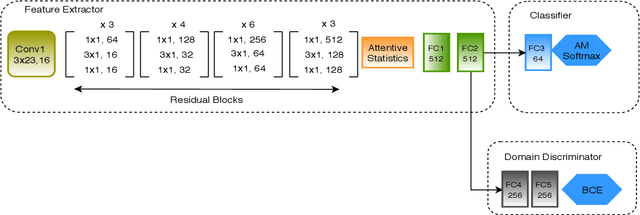
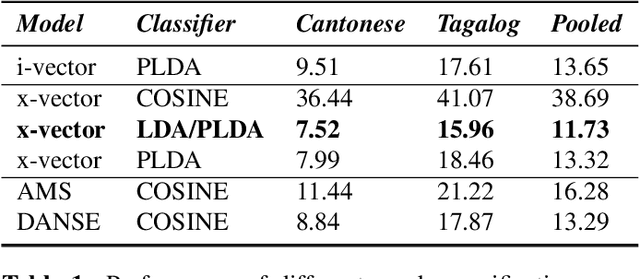

In this article we propose a novel approach for adapting speaker embeddings to new domains based on adversarial training of neural networks. We apply our embeddings to the task of text-independent speaker verification, a challenging, real-world problem in biometric security. We further the development of end-to-end speaker embedding models by combing a novel 1-dimensional, self-attentive residual network, an angular margin loss function and adversarial training strategy. Our model is able to learn extremely compact, 64-dimensional speaker embeddings that deliver competitive performance on a number of popular datasets using simple cosine distance scoring. One the NIST-SRE 2016 task we are able to beat a strong i-vector baseline, while on the Speakers in the Wild task our model was able to outperform both i-vector and x-vector baselines, showing an absolute improvement of 2.19% over the latter. Additionally, we show that the integration of adversarial training consistently leads to a significant improvement over an unadapted model.