 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Spatial Audio Transcoder
May 07, 2024This paper addresses the challenges associated with both the conversion between different spatial audio formats and the decoding of a spatial audio format to a specific loudspeaker layout. Existing approaches often rely on layout remapping tools, which may not guarantee optimal conversion from a psychoacoustic perspective. To overcome these challenges, we present the Universal Spatial Audio Transcoder(USAT) method and its corresponding open source implementation. USAT generates an optimal decoder or transcoder for any input spatial audio format, adapting it to any output format or 2D/3D loudspeaker configuration. Drawing upon optimization techniques based on psychoacoustic principles, the algorithm maximizes the preservation of spatial information. We present examples of the decoding and transcoding of several audio formats, and show that USAT approach is advantageous compared to the most common methods in the field.
Mono-to-stereo through parametric stereo generation
Jun 26, 2023



Generating a stereophonic presentation from a monophonic audio signal is a challenging open task, especially if the goal is to obtain a realistic spatial imaging with a specific panning of sound elements. In this work, we propose to convert mono to stereo by means of predicting parametric stereo (PS) parameters using both nearest neighbor and deep network approaches. In combination with PS, we also propose to model the task with generative approaches, allowing to synthesize multiple and equally-plausible stereo renditions from the same mono signal. To achieve this, we consider both autoregressive and masked token modelling approaches. We provide evidence that the proposed PS-based models outperform a competitive classical decorrelation baseline and that, within a PS prediction framework, modern generative models outshine equivalent non-generative counterparts. Overall, our work positions both PS and generative modelling as strong and appealing methodologies for mono-to-stereo upmixing. A discussion of the limitations of these approaches is also provided.
Universal Speech Enhancement with Score-based Diffusion
Jun 07, 2022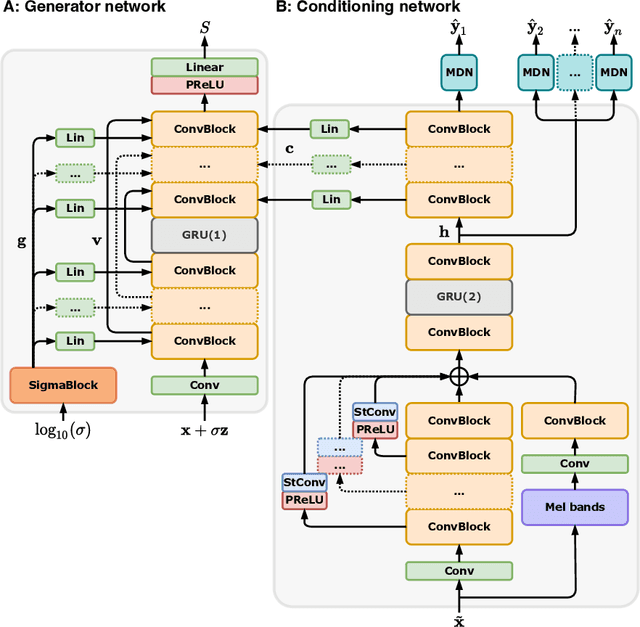
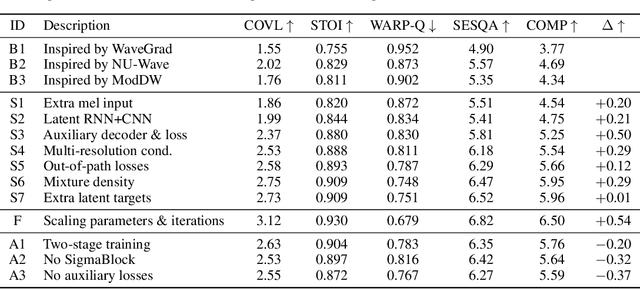
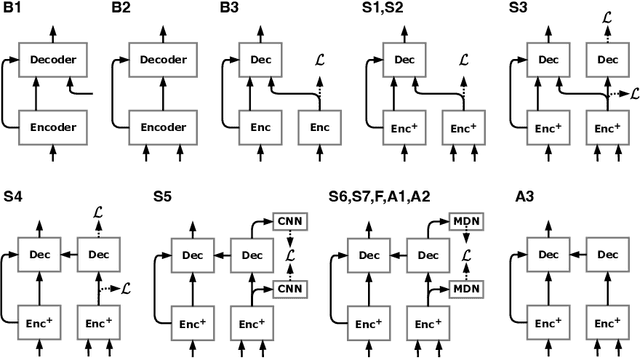
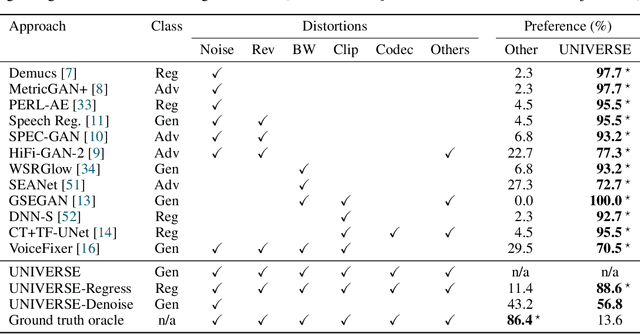
Removing background noise from speech audio has been the subject of considerable research and effort, especially in recent years due to the rise of virtual communication and amateur sound recording. Yet background noise is not the only unpleasant disturbance that can prevent intelligibility: reverb, clipping, codec artifacts, problematic equalization, limited bandwidth, or inconsistent loudness are equally disturbing and ubiquitous. In this work, we propose to consider the task of speech enhancement as a holistic endeavor, and present a universal speech enhancement system that tackles 55 different distortions at the same time. Our approach consists of a generative model that employs score-based diffusion, together with a multi-resolution conditioning network that performs enhancement with mixture density networks. We show that this approach significantly outperforms the state of the art in a subjective test performed by expert listeners. We also show that it achieves competitive objective scores with just 4-8 diffusion steps, despite not considering any particular strategy for fast sampling. We hope that both our methodology and technical contributions encourage researchers and practitioners to adopt a universal approach to speech enhancement, possibly framing it as a generative task.
Upsampling layers for music source separation
Nov 23, 2021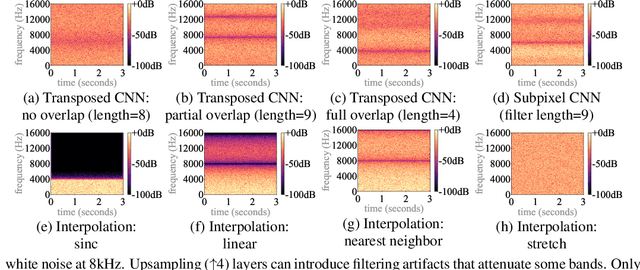
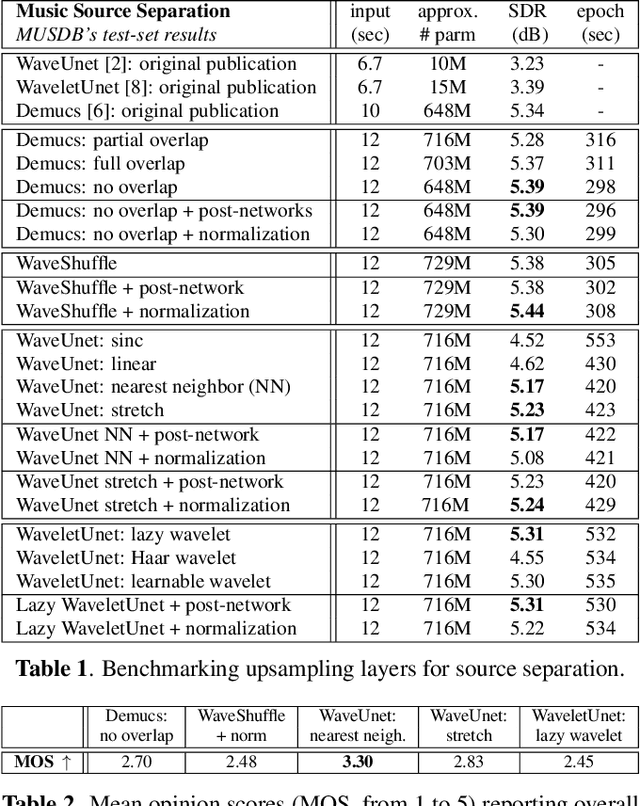

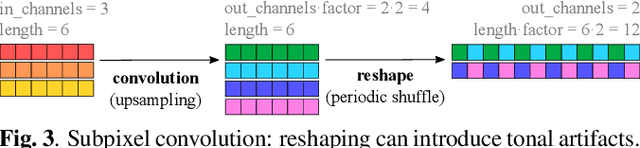
Upsampling artifacts are caused by problematic upsampling layers and due to spectral replicas that emerge while upsampling. Also, depending on the used upsampling layer, such artifacts can either be tonal artifacts (additive high-frequency noise) or filtering artifacts (substractive, attenuating some bands). In this work we investigate the practical implications of having upsampling artifacts in the resulting audio, by studying how different artifacts interact and assessing their impact on the models' performance. To that end, we benchmark a large set of upsampling layers for music source separation: different transposed and subpixel convolution setups, different interpolation upsamplers (including two novel layers based on stretch and sinc interpolation), and different wavelet-based upsamplers (including a novel learnable wavelet layer). Our results show that filtering artifacts, associated with interpolation upsamplers, are perceptually preferrable, even if they tend to achieve worse objective scores.