 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFed-Sim: Federated Simulation for Medical Imaging
Sep 01, 2020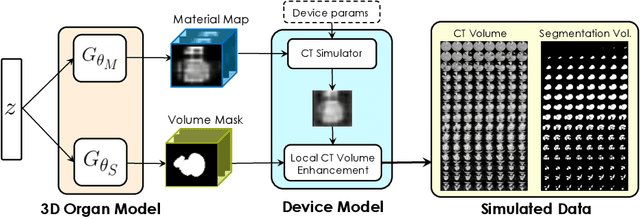

Labelling data is expensive and time consuming especially for domains such as medical imaging that contain volumetric imaging data and require expert knowledge. Exploiting a larger pool of labeled data available across multiple centers, such as in federated learning, has also seen limited success since current deep learning approaches do not generalize well to images acquired with scanners from different manufacturers. We aim to address these problems in a common, learning-based image simulation framework which we refer to as Federated Simulation. We introduce a physics-driven generative approach that consists of two learnable neural modules: 1) a module that synthesizes 3D cardiac shapes along with their materials, and 2) a CT simulator that renders these into realistic 3D CT Volumes, with annotations. Since the model of geometry and material is disentangled from the imaging sensor, it can effectively be trained across multiple medical centers. We show that our data synthesis framework improves the downstream segmentation performance on several datasets. Project Page: https://nv-tlabs.github.io/fed-sim/ .
Expressive Telepresence via Modular Codec Avatars
Aug 26, 2020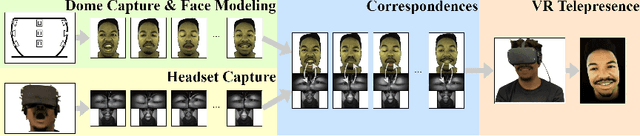
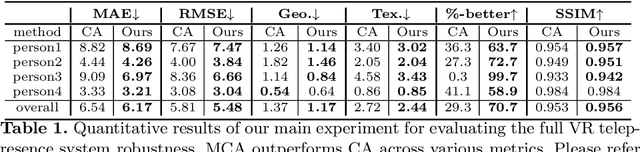
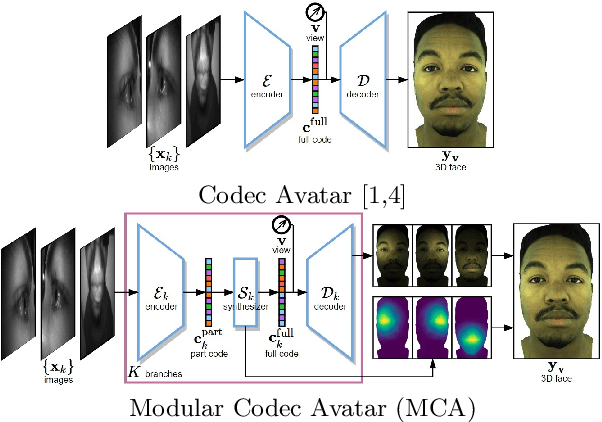
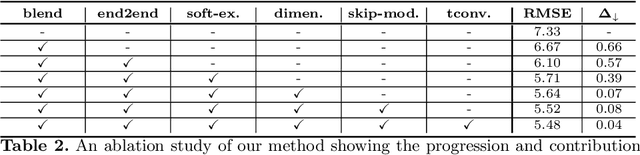
VR telepresence consists of interacting with another human in a virtual space represented by an avatar. Today most avatars are cartoon-like, but soon the technology will allow video-realistic ones. This paper aims in this direction and presents Modular Codec Avatars (MCA), a method to generate hyper-realistic faces driven by the cameras in the VR headset. MCA extends traditional Codec Avatars (CA) by replacing the holistic models with a learned modular representation. It is important to note that traditional person-specific CAs are learned from few training samples, and typically lack robustness as well as limited expressiveness when transferring facial expressions. MCAs solve these issues by learning a modulated adaptive blending of different facial components as well as an exemplar-based latent alignment. We demonstrate that MCA achieves improved expressiveness and robustness w.r.t to CA in a variety of real-world datasets and practical scenarios. Finally, we showcase new applications in VR telepresence enabled by the proposed model.
Interactive Annotation of 3D Object Geometry using 2D Scribbles
Aug 24, 2020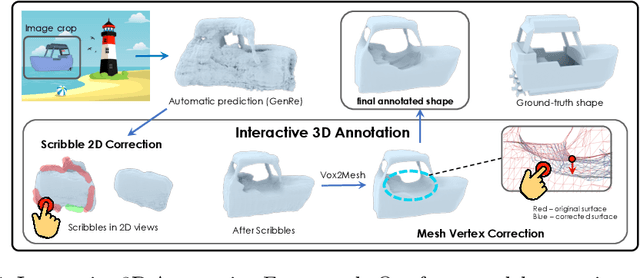
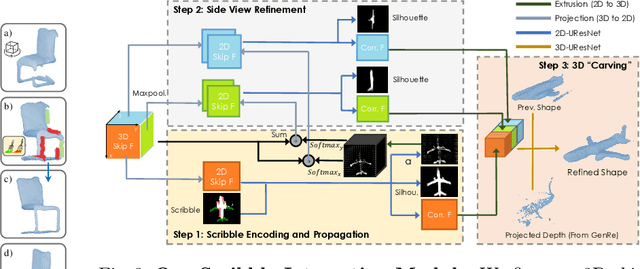
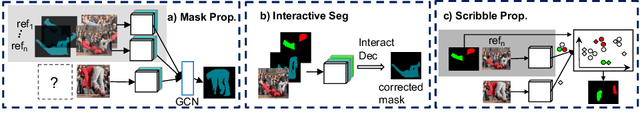
Inferring detailed 3D geometry of the scene is crucial for robotics applications, simulation, and 3D content creation. However, such information is hard to obtain, and thus very few datasets support it. In this paper, we propose an interactive framework for annotating 3D object geometry from both point cloud data and RGB imagery. The key idea behind our approach is to exploit strong priors that humans have about the 3D world in order to interactively annotate complete 3D shapes. Our framework targets naive users without artistic or graphics expertise. We introduce two simple-to-use interaction modules. First, we make an automatic guess of the 3D shape and allow the user to provide feedback about large errors by drawing scribbles in desired 2D views. Next, we aim to correct minor errors, in which users drag and drop mesh vertices, assisted by a neural interactive module implemented as a Graph Convolutional Network. Experimentally, we show that only a few user interactions are needed to produce good quality 3D shapes on popular benchmarks such as ShapeNet, Pix3D and ScanNet. We implement our framework as a web service and conduct a user study, where we show that user annotated data using our method effectively facilitates real-world learning tasks. Web service: http://www.cs.toronto.edu/~shenti11/scribble3d.
ScribbleBox: Interactive Annotation Framework for Video Object Segmentation
Aug 22, 2020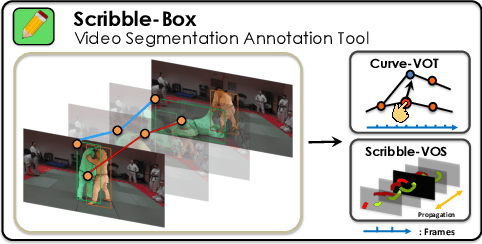
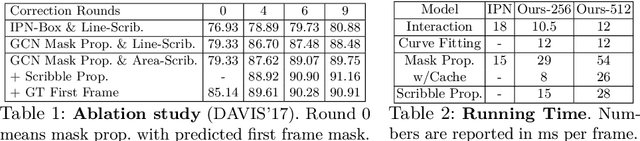
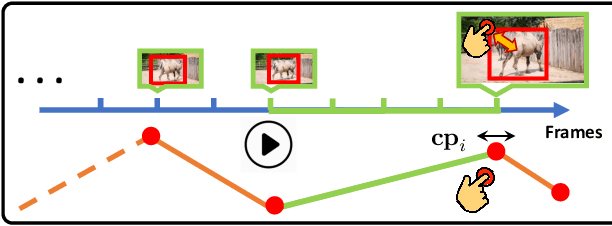
Manually labeling video datasets for segmentation tasks is extremely time consuming. In this paper, we introduce ScribbleBox, a novel interactive framework for annotating object instances with masks in videos. In particular, we split annotation into two steps: annotating objects with tracked boxes, and labeling masks inside these tracks. We introduce automation and interaction in both steps. Box tracks are annotated efficiently by approximating the trajectory using a parametric curve with a small number of control points which the annotator can interactively correct. Our approach tolerates a modest amount of noise in the box placements, thus typically only a few clicks are needed to annotate tracked boxes to a sufficient accuracy. Segmentation masks are corrected via scribbles which are efficiently propagated through time. We show significant performance gains in annotation efficiency over past work. We show that our ScribbleBox approach reaches 88.92% J&F on DAVIS2017 with 9.14 clicks per box track, and 4 frames of scribble annotation.
Beyond Fixed Grid: Learning Geometric Image Representation with a Deformable Grid
Aug 21, 2020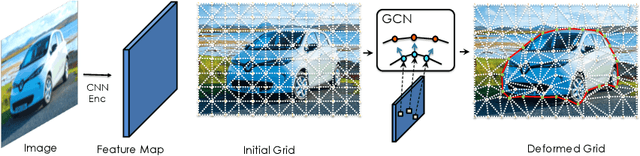

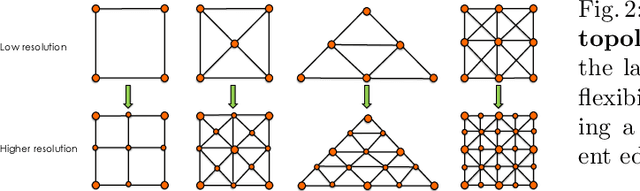

In modern computer vision, images are typically represented as a fixed uniform grid with some stride and processed via a deep convolutional neural network. We argue that deforming the grid to better align with the high-frequency image content is a more effective strategy. We introduce \emph{Deformable Grid} DefGrid, a learnable neural network module that predicts location offsets of vertices of a 2-dimensional triangular grid, such that the edges of the deformed grid align with image boundaries. We showcase our DefGrid in a variety of use cases, i.e., by inserting it as a module at various levels of processing. We utilize DefGrid as an end-to-end \emph{learnable geometric downsampling} layer that replaces standard pooling methods for reducing feature resolution when feeding images into a deep CNN. We show significantly improved results at the same grid resolution compared to using CNNs on uniform grids for the task of semantic segmentation. We also utilize DefGrid at the output layers for the task of object mask annotation, and show that reasoning about object boundaries on our predicted polygonal grid leads to more accurate results over existing pixel-wise and curve-based approaches. We finally showcase DefGrid as a standalone module for unsupervised image partitioning, showing superior performance over existing approaches. Project website: http://www.cs.toronto.edu/~jungao/def-grid
Meta-Sim2: Unsupervised Learning of Scene Structure for Synthetic Data Generation
Aug 20, 2020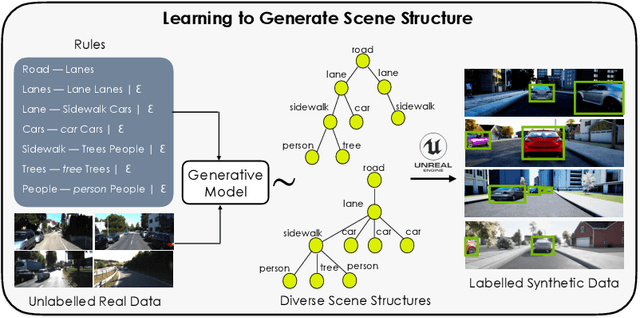

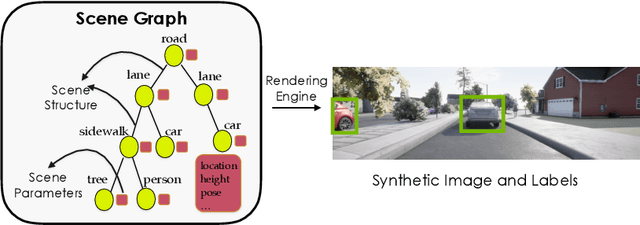
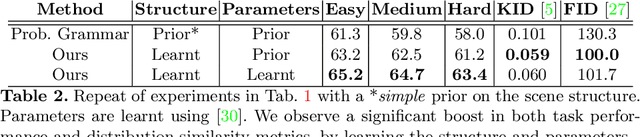
Procedural models are being widely used to synthesize scenes for graphics, gaming, and to create (labeled) synthetic datasets for ML. In order to produce realistic and diverse scenes, a number of parameters governing the procedural models have to be carefully tuned by experts. These parameters control both the structure of scenes being generated (e.g. how many cars in the scene), as well as parameters which place objects in valid configurations. Meta-Sim aimed at automatically tuning parameters given a target collection of real images in an unsupervised way. In Meta-Sim2, we aim to learn the scene structure in addition to parameters, which is a challenging problem due to its discrete nature. Meta-Sim2 proceeds by learning to sequentially sample rule expansions from a given probabilistic scene grammar. Due to the discrete nature of the problem, we use Reinforcement Learning to train our model, and design a feature space divergence between our synthesized and target images that is key to successful training. Experiments on a real driving dataset show that, without any supervision, we can successfully learn to generate data that captures discrete structural statistics of objects, such as their frequency, in real images. We also show that this leads to downstream improvement in the performance of an object detector trained on our generated dataset as opposed to other baseline simulation methods. Project page: https://nv-tlabs.github.io/meta-sim-structure/.
Learning to Generate Diverse Dance Motions with Transformer
Aug 18, 2020
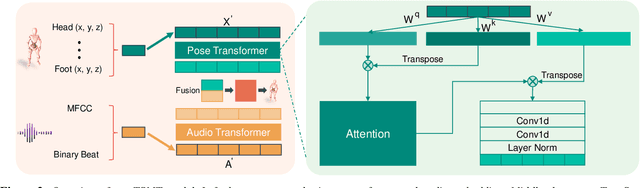

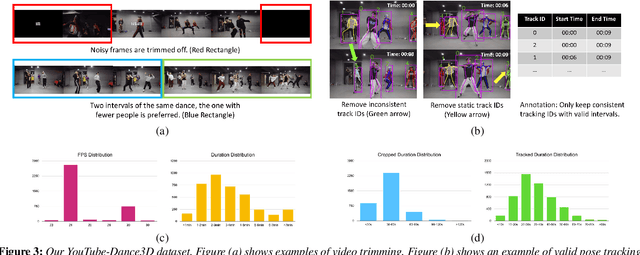
With the ongoing pandemic, virtual concerts and live events using digitized performances of musicians are getting traction on massive multiplayer online worlds. However, well choreographed dance movements are extremely complex to animate and would involve an expensive and tedious production process. In addition to the use of complex motion capture systems, it typically requires a collaborative effort between animators, dancers, and choreographers. We introduce a complete system for dance motion synthesis, which can generate complex and highly diverse dance sequences given an input music sequence. As motion capture data is limited for the range of dance motions and styles, we introduce a massive dance motion data set that is created from YouTube videos. We also present a novel two-stream motion transformer generative model, which can generate motion sequences with high flexibility. We also introduce new evaluation metrics for the quality of synthesized dance motions, and demonstrate that our system can outperform state-of-the-art methods. Our system provides high-quality animations suitable for large crowds for virtual concerts and can also be used as reference for professional animation pipelines. Most importantly, we show that vast online videos can be effective in training dance motion models.
Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
Aug 13, 2020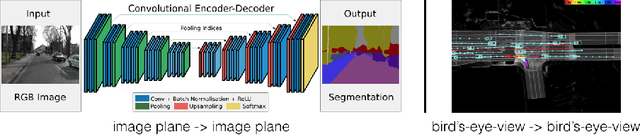
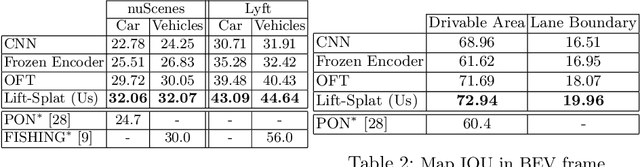
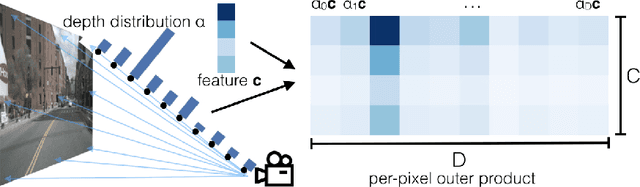
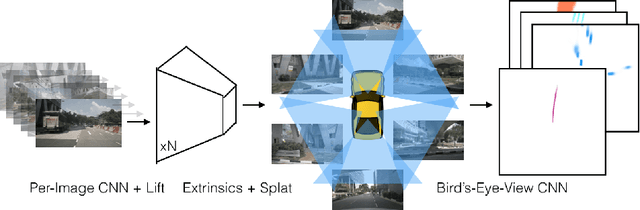
The goal of perception for autonomous vehicles is to extract semantic representations from multiple sensors and fuse these representations into a single "bird's-eye-view" coordinate frame for consumption by motion planning. We propose a new end-to-end architecture that directly extracts a bird's-eye-view representation of a scene given image data from an arbitrary number of cameras. The core idea behind our approach is to "lift" each image individually into a frustum of features for each camera, then "splat" all frustums into a rasterized bird's-eye-view grid. By training on the entire camera rig, we provide evidence that our model is able to learn not only how to represent images but how to fuse predictions from all cameras into a single cohesive representation of the scene while being robust to calibration error. On standard bird's-eye-view tasks such as object segmentation and map segmentation, our model outperforms all baselines and prior work. In pursuit of the goal of learning dense representations for motion planning, we show that the representations inferred by our model enable interpretable end-to-end motion planning by "shooting" template trajectories into a bird's-eye-view cost map output by our network. We benchmark our approach against models that use oracle depth from lidar. Project page with code: https://nv-tlabs.github.io/lift-splat-shoot .
Learning to Simulate Dynamic Environments with GameGAN
May 25, 2020
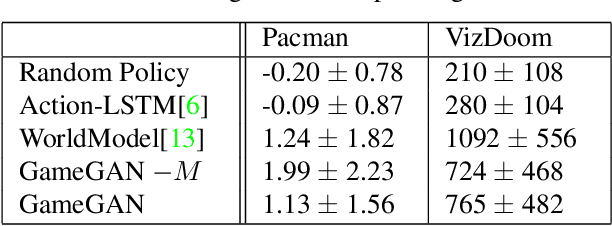
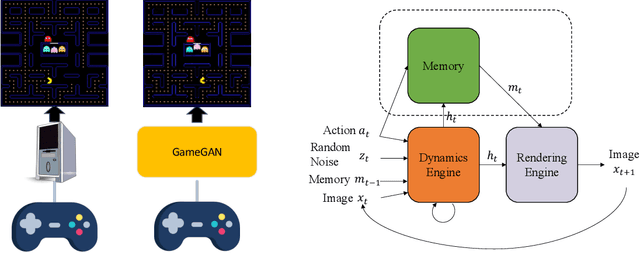

Simulation is a crucial component of any robotic system. In order to simulate correctly, we need to write complex rules of the environment: how dynamic agents behave, and how the actions of each of the agents affect the behavior of others. In this paper, we aim to learn a simulator by simply watching an agent interact with an environment. We focus on graphics games as a proxy of the real environment. We introduce GameGAN, a generative model that learns to visually imitate a desired game by ingesting screenplay and keyboard actions during training. Given a key pressed by the agent, GameGAN "renders" the next screen using a carefully designed generative adversarial network. Our approach offers key advantages over existing work: we design a memory module that builds an internal map of the environment, allowing for the agent to return to previously visited locations with high visual consistency. In addition, GameGAN is able to disentangle static and dynamic components within an image making the behavior of the model more interpretable, and relevant for downstream tasks that require explicit reasoning over dynamic elements. This enables many interesting applications such as swapping different components of the game to build new games that do not exist.
The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines
Apr 29, 2020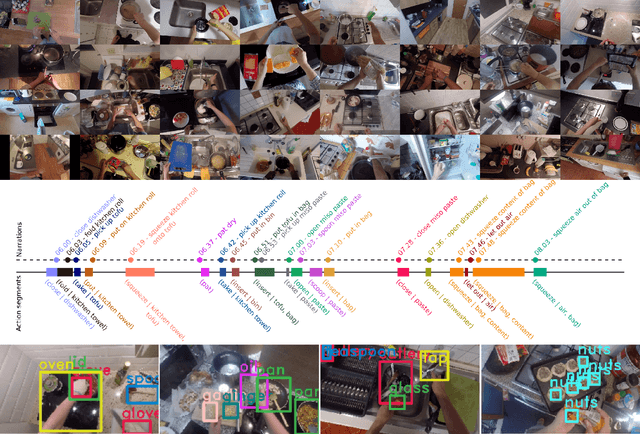
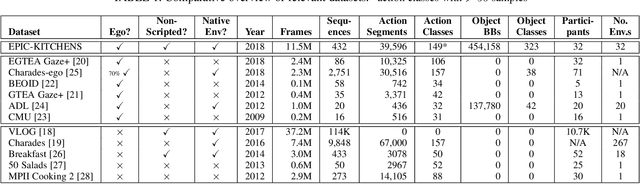

Since its introduction in 2018, EPIC-KITCHENS has attracted attention as the largest egocentric video benchmark, offering a unique viewpoint on people's interaction with objects, their attention, and even intention. In this paper, we detail how this large-scale dataset was captured by 32 participants in their native kitchen environments, and densely annotated with actions and object interactions. Our videos depict nonscripted daily activities, as recording is started every time a participant entered their kitchen. Recording took place in 4 countries by participants belonging to 10 different nationalities, resulting in highly diverse kitchen habits and cooking styles. Our dataset features 55 hours of video consisting of 11.5M frames, which we densely labelled for a total of 39.6K action segments and 454.2K object bounding boxes. Our annotation is unique in that we had the participants narrate their own videos after recording, thus reflecting true intention, and we crowd-sourced ground-truths based on these. We describe our object, action and. anticipation challenges, and evaluate several baselines over two test splits, seen and unseen kitchens. We introduce new baselines that highlight the multimodal nature of the dataset and the importance of explicit temporal modelling to discriminate fine-grained actions e.g. 'closing a tap' from 'opening' it up.