 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum walk inspired JPEG compression of images
Feb 12, 2026This work proposes a quantum inspired adaptive quantization framework that enhances the classical JPEG compression by introducing a learned, optimized Qtable derived using a Quantum Walk Inspired Optimization (QWIO) search strategy. The optimizer searches a continuous parameter space of frequency band scaling factors under a unified rate distortion objective that jointly considers reconstruction fidelity and compression efficiency. The proposed framework is evaluated on MNIST, CIFAR10, and ImageNet subsets, using Peak Signal to Noise Ratio (PSNR), Structural Similarity Index (SSIM), Bits Per Pixel (BPP), and error heatmap visual analysis as evaluation metrics. Experimental results show average gains ranging from 3 to 6 dB PSNR, along with better structural preservation of edges, contours, and luminance transitions, without modifying decoder compatibility. The structure remains JPEG compliant and can be implemented using accessible scientific packages making it ideal for deployment and practical research use.
Prediction of Malignant & Benign Breast Cancer: A Data Mining Approach in Healthcare Applications
Feb 23, 2019


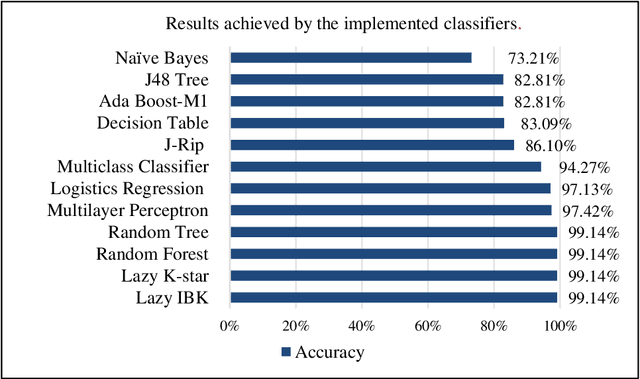
As much as data science is playing a pivotal role everywhere, healthcare also finds it prominent application. Breast Cancer is the top rated type of cancer amongst women; which took away 627,000 lives alone. This high mortality rate due to breast cancer does need attention, for early detection so that prevention can be done in time. As a potential contributor to state-of-art technology development, data mining finds a multi-fold application in predicting Brest cancer. This work focuses on different classification techniques implementation for data mining in predicting malignant and benign breast cancer. Breast Cancer Wisconsin data set from the UCI repository has been used as experimental dataset while attribute clump thickness being used as an evaluation class. The performances of these twelve algorithms: Ada Boost M 1, Decision Table, J Rip, Lazy IBK, Logistics Regression, Multiclass Classifier, Multilayer Perceptron, Naive Bayes, Random forest and Random Tree are analyzed on this data set. Keywords- Data Mining, Classification Techniques, UCI repository, Breast Cancer, Classification Algorithms
Learning to Clean: A GAN Perspective
Jan 28, 2019



In the big data era, the impetus to digitize the vast reservoirs of data trapped in unstructured scanned documents such as invoices, bank documents and courier receipts has gained fresh momentum. The scanning process often results in the introduction of artifacts such as background noise, blur due to camera motion, watermarkings, coffee stains, or faded text. These artifacts pose many readability challenges to current text recognition algorithms and significantly degrade their performance. Existing learning based denoising techniques require a dataset comprising of noisy documents paired with cleaned versions. In such scenarios, a model can be trained to generate clean documents from noisy versions. However, very often in the real world such a paired dataset is not available, and all we have for training our denoising model are unpaired sets of noisy and clean images. This paper explores the use of GANs to generate denoised versions of the noisy documents. In particular, where paired information is available, we formulate the problem as an image-to-image translation task i.e, translating a document from noisy domain ( i.e., background noise, blurred, faded, watermarked ) to a target clean document using Generative Adversarial Networks (GAN). However, in the absence of paired images for training, we employed CycleGAN which is known to learn a mapping between the distributions of the noisy images to the denoised images using unpaired data to achieve image-to-image translation for cleaning the noisy documents. We compare the performance of CycleGAN for document cleaning tasks using unpaired images with a Conditional GAN trained on paired data from the same dataset. Experiments were performed on a public document dataset on which different types of noise were artificially induced, results demonstrate that CycleGAN learns a more robust mapping from the space of noisy to clean documents.
Human Learning of Unknown Environments in Agile Guidance Tasks
Oct 21, 2017



Trained human pilots or operators still stand out through their efficient, robust, and versatile skills in guidance tasks such as driving agile vehicles in spatial environments or performing complex surgeries. This research studies how humans learn a task environment for agile behavior. The hypothesis is that sensory-motor primitives previously described as interaction patterns and proposed as units of behavior for organization and planning of behavior provide elements of memory structure needed to efficiently learn task environments. The paper presents a modeling and analysis framework using the interaction patterns to formulate learning as a graph learning process and apply the framework to investigate and evaluate human learning and decision-making while operating in unknown environments. This approach emphasizes the effects of agent-environment dynamics (e.g., a vehicle controlled by a human operator), which is not emphasized in existing environment learning studies. The framework is applied to study human data collected from simulated first-person guidance experiments in an obstacle field. Subjects were asked to perform multiple trials and find minimum-time routes between prespecified start and goal locations without priori knowledge of the environment.
The Compressed Model of Residual CNDS
Jun 15, 2017

Convolutional neural networks have achieved a great success in the recent years. Although, the way to maximize the performance of the convolutional neural networks still in the beginning. Furthermore, the optimization of the size and the time that need to train the convolutional neural networks is very far away from reaching the researcher's ambition. In this paper, we proposed a new convolutional neural network that combined several techniques to boost the optimization of the convolutional neural network in the aspects of speed and size. As we used our previous model Residual-CNDS (ResCNDS), which solved the problems of slower convergence, overfitting, and degradation, and compressed it. The outcome model called Residual-Squeeze-CNDS (ResSquCNDS), which we demonstrated on our sold technique to add residual learning and our model of compressing the convolutional neural networks. Our model of compressing adapted from the SQUEEZENET model, but our model is more generalizable, which can be applied almost to any neural network model, and fully integrated into the residual learning, which addresses the problem of the degradation very successfully. Our proposed model trained on very large-scale MIT Places365-Standard scene datasets, which backing our hypothesis that the new compressed model inherited the best of the previous ResCNDS8 model, and almost get the same accuracy in the validation Top-1 and Top-5 with 87.64% smaller in size and 13.33% faster in the training time.
Residual Squeeze VGG16
May 05, 2017
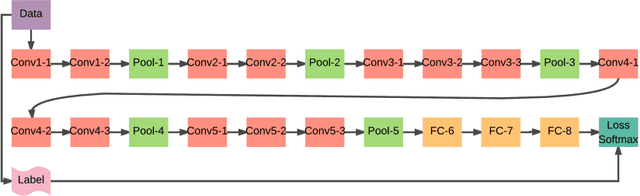
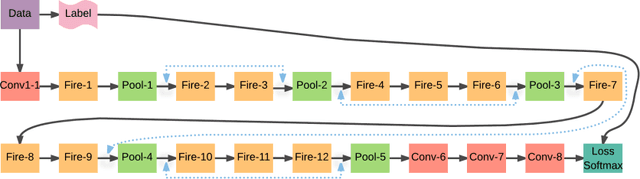

Deep learning has given way to a new era of machine learning, apart from computer vision. Convolutional neural networks have been implemented in image classification, segmentation and object detection. Despite recent advancements, we are still in the very early stages and have yet to settle on best practices for network architecture in terms of deep design, small in size and a short training time. In this work, we propose a very deep neural network comprised of 16 Convolutional layers compressed with the Fire Module adapted from the SQUEEZENET model. We also call for the addition of residual connections to help suppress degradation. This model can be implemented on almost every neural network model with fully incorporated residual learning. This proposed model Residual-Squeeze-VGG16 (ResSquVGG16) trained on the large-scale MIT Places365-Standard scene dataset. In our tests, the model performed with accuracy similar to the pre-trained VGG16 model in Top-1 and Top-5 validation accuracy while also enjoying a 23.86% reduction in training time and an 88.4% reduction in size. In our tests, this model was trained from scratch.
Residual CNDS
Aug 07, 2016



Convolutional Neural networks nowadays are of tremendous importance for any image classification system. One of the most investigated methods to increase the accuracy of CNN is by increasing the depth of CNN. Increasing the depth by stacking more layers also increases the difficulty of training besides making it computationally expensive. Some research found that adding auxiliary forks after intermediate layers increases the accuracy. Specifying which intermediate layer shoud have the fork just addressed recently. Where a simple rule were used to detect the position of intermediate layers that needs the auxiliary supervision fork. This technique known as convolutional neural networks with deep supervision (CNDS). This technique enhanced the accuracy of classification over the straight forward CNN used on the MIT places dataset and ImageNet. In the other side, Residual Learning is another technique emerged recently to ease the training of very deep CNN. Residual Learning framwork changed the learning of layers from unreferenced functions to learning residual function with regard to the layer's input. Residual Learning achieved state of arts results on ImageNet 2015 and COCO competitions. In this paper, we study the effect of adding residual connections to CNDS network. Our experiments results show increasing of accuracy over using CNDS only.