 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning on Graphs: A Model and Comprehensive Taxonomy
May 07, 2020
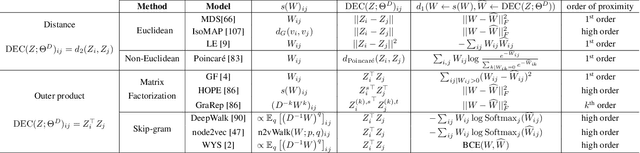
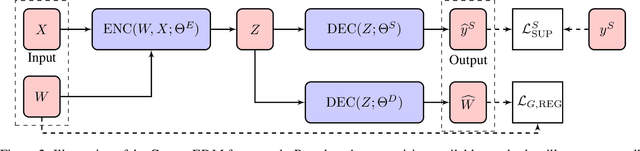

There has been a surge of recent interest in learning representations for graph-structured data. Graph representation learning methods have generally fallen into three main categories, based on the availability of labeled data. The first, network embedding (such as shallow graph embedding or graph auto-encoders), focuses on learning unsupervised representations of relational structure. The second, graph regularized neural networks, leverages graphs to augment neural network losses with a regularization objective for semi-supervised learning. The third, graph neural networks, aims to learn differentiable functions over discrete topologies with arbitrary structure. However, despite the popularity of these areas there has been surprisingly little work on unifying the three paradigms. Here, we aim to bridge the gap between graph neural networks, network embedding and graph regularization models. We propose a comprehensive taxonomy of representation learning methods for graph-structured data, aiming to unify several disparate bodies of work. Specifically, we propose a Graph Encoder Decoder Model (GRAPHEDM), which generalizes popular algorithms for semi-supervised learning on graphs (e.g. GraphSage, Graph Convolutional Networks, Graph Attention Networks), and unsupervised learning of graph representations (e.g. DeepWalk, node2vec, etc) into a single consistent approach. To illustrate the generality of this approach, we fit over thirty existing methods into this framework. We believe that this unifying view both provides a solid foundation for understanding the intuition behind these methods, and enables future research in the area.
Meta Adaptation using Importance Weighted Demonstrations
Nov 23, 2019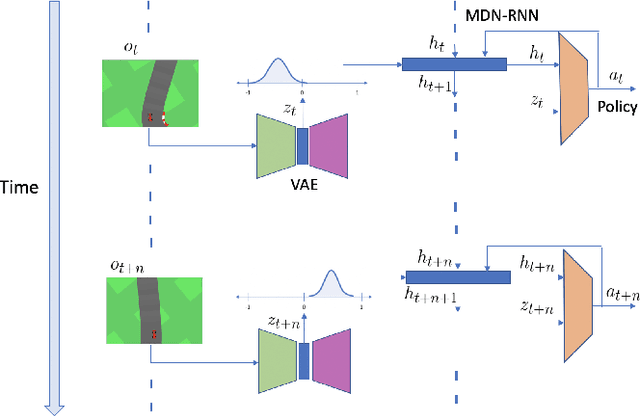


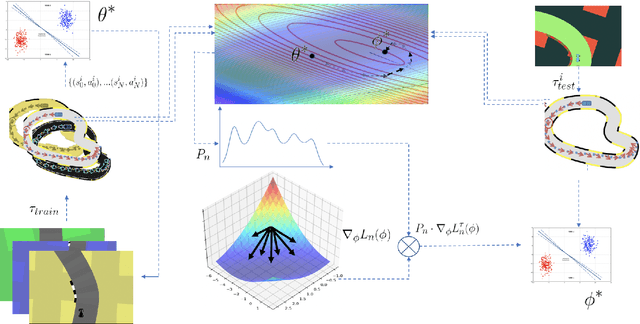
Imitation learning has gained immense popularity because of its high sample-efficiency. However, in real-world scenarios, where the trajectory distribution of most of the tasks dynamically shifts, model fitting on continuously aggregated data alone would be futile. In some cases, the distribution shifts, so much, that it is difficult for an agent to infer the new task. We propose a novel algorithm to generalize on any related task by leveraging prior knowledge on a set of specific tasks, which involves assigning importance weights to each past demonstration. We show experiments where the robot is trained from a diversity of environmental tasks and is also able to adapt to an unseen environment, using few-shot learning. We also developed a prototype robot system to test our approach on the task of visual navigation, and experimental results obtained were able to confirm these suppositions.
Human Languages in Source Code: Auto-Translation for Localized Instruction
Sep 10, 2019
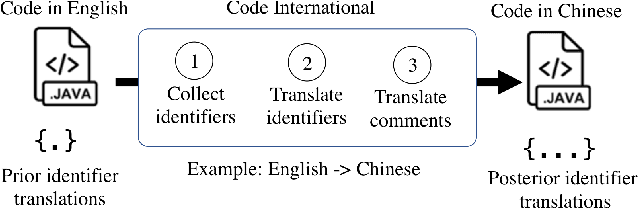


Computer science education has promised open access around the world, but access is largely determined by what human language you speak. As younger students learn computer science it is less appropriate to assume that they should learn English beforehand. To that end we present CodeInternational, the first tool to translate code between human languages. To develop a theory of non-English code, and inform our translation decisions, we conduct a study of public code repositories on GitHub. The study is to the best of our knowledge the first on human-language in code and covers 2.9 million Java repositories. To demonstrate CodeInternational's educational utility, we build an interactive version of the popular English-language Karel reader and translate it into 100 spoken languages. Our translations have already been used in classrooms around the world, and represent a first step in an important open CS-education problem.
MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing
May 28, 2019
Existing popular methods for semi-supervised learning with Graph Neural Networks (such as the Graph Convolutional Network) provably cannot learn a general class of neighborhood mixing relationships. To address this weakness, we propose a new model, MixHop, that can learn these relationships, including difference operators, by repeatedly mixing feature representations of neighbors at various distances. Mixhop requires no additional memory or computational complexity, and outperforms on challenging baselines. In addition, we propose sparsity regularization that allows us to visualize how the network prioritizes neighborhood information across different graph datasets. Our analysis of the learned architectures reveals that neighborhood mixing varies per datasets.
Identifying and Analyzing Cryptocurrency Manipulations in Social Media
Feb 04, 2019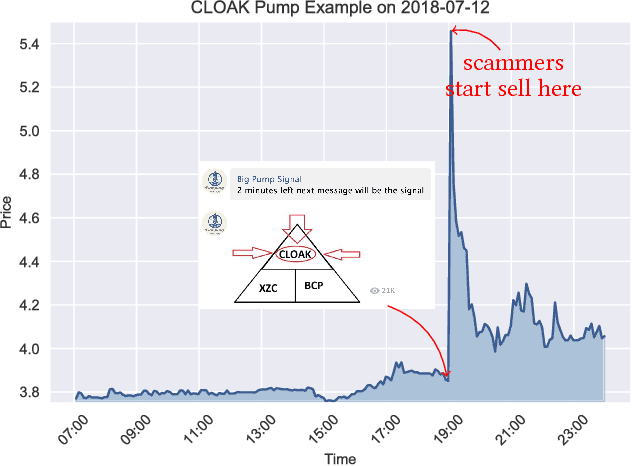
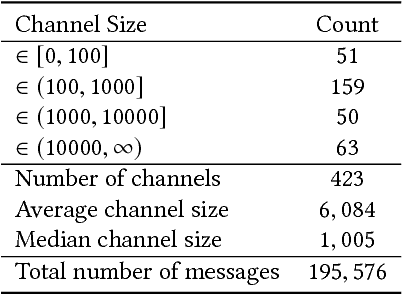
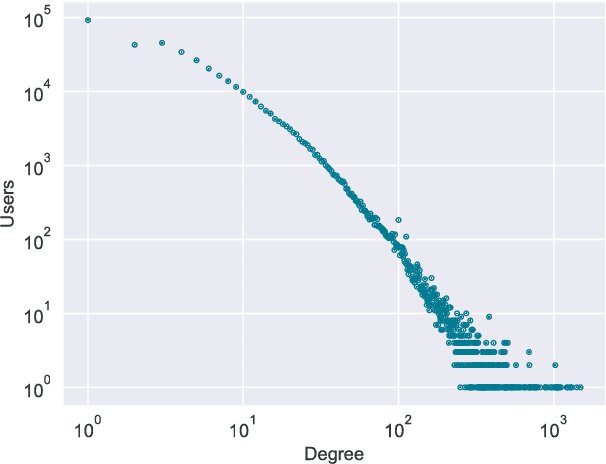
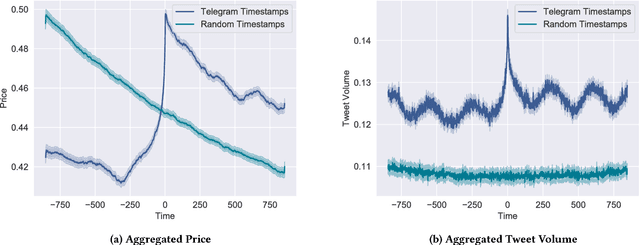
Interest surrounding cryptocurrencies, digital or virtual currencies that are used as a medium for financial transactions, has grown tremendously in recent years. The anonymity surrounding these currencies makes investors particularly susceptible to fraud---such as "pump and dump" scams---where the goal is to artificially inflate the perceived worth of a currency, luring victims into investing before the fraudsters can sell their holdings. Because of the speed and relative anonymity offered by social platforms such as Twitter and Telegram, social media has become a preferred platform for scammers who wish to spread false hype about the cryptocurrency they are trying to pump. In this work we propose and evaluate a computational approach that can automatically identify pump and dump scams as they unfold by combining information across social media platforms. We also develop a multi-modal approach for predicting whether a particular pump attempt will succeed or not. Finally, we analyze the prevalence of bots in cryptocurrency related tweets, and observe a significant increase in bot activity during the pump attempts.
Watch Your Step: Learning Node Embeddings via Graph Attention
Sep 12, 2018
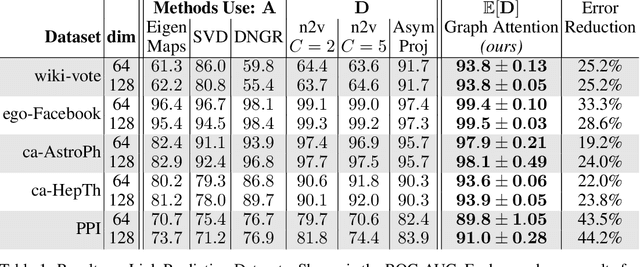
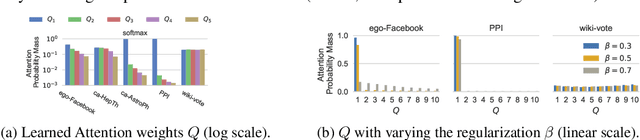

Graph embedding methods represent nodes in a continuous vector space, preserving information from the graph (e.g. by sampling random walks). There are many hyper-parameters to these methods (such as random walk length) which have to be manually tuned for every graph. In this paper, we replace random walk hyper-parameters with trainable parameters that we automatically learn via backpropagation. In particular, we learn a novel attention model on the power series of the transition matrix, which guides the random walk to optimize an upstream objective. Unlike previous approaches to attention models, the method that we propose utilizes attention parameters exclusively on the data (e.g. on the random walk), and not used by the model for inference. We experiment on link prediction tasks, as we aim to produce embeddings that best-preserve the graph structure, generalizing to unseen information. We improve state-of-the-art on a comprehensive suite of real world datasets including social, collaboration, and biological networks. Adding attention to random walks can reduce the error by 20% to 45% on datasets we attempted. Further, our learned attention parameters are different for every graph, and our automatically-found values agree with the optimal choice of hyper-parameter if we manually tune existing methods.
N-GCN: Multi-scale Graph Convolution for Semi-supervised Node Classification
Feb 24, 2018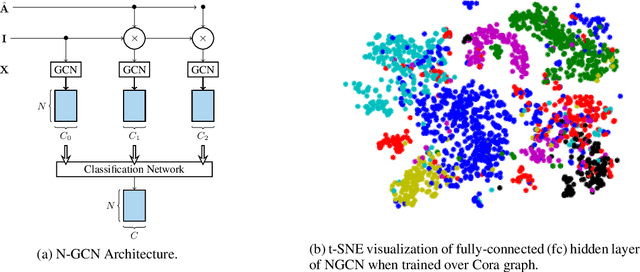

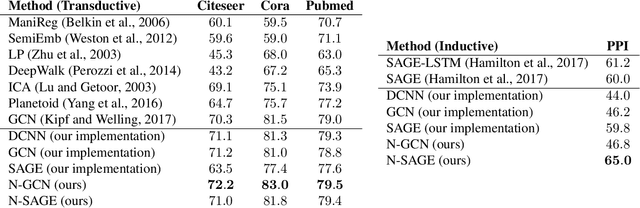
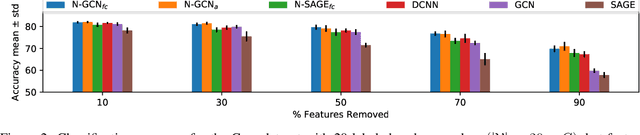
Graph Convolutional Networks (GCNs) have shown significant improvements in semi-supervised learning on graph-structured data. Concurrently, unsupervised learning of graph embeddings has benefited from the information contained in random walks. In this paper, we propose a model: Network of GCNs (N-GCN), which marries these two lines of work. At its core, N-GCN trains multiple instances of GCNs over node pairs discovered at different distances in random walks, and learns a combination of the instance outputs which optimizes the classification objective. Our experiments show that our proposed N-GCN model improves state-of-the-art baselines on all of the challenging node classification tasks we consider: Cora, Citeseer, Pubmed, and PPI. In addition, our proposed method has other desirable properties, including generalization to recently proposed semi-supervised learning methods such as GraphSAGE, allowing us to propose N-SAGE, and resilience to adversarial input perturbations.
Learning Edge Representations via Low-Rank Asymmetric Projections
Sep 13, 2017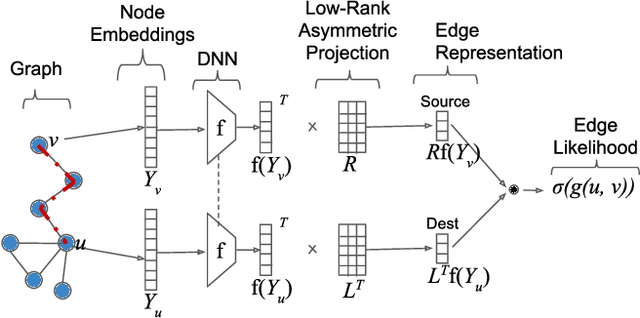
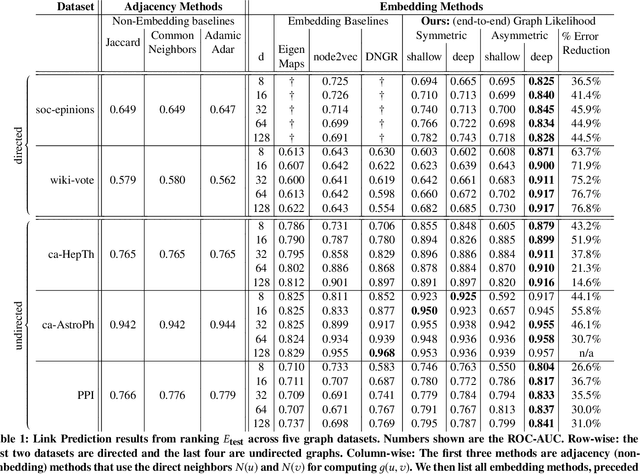
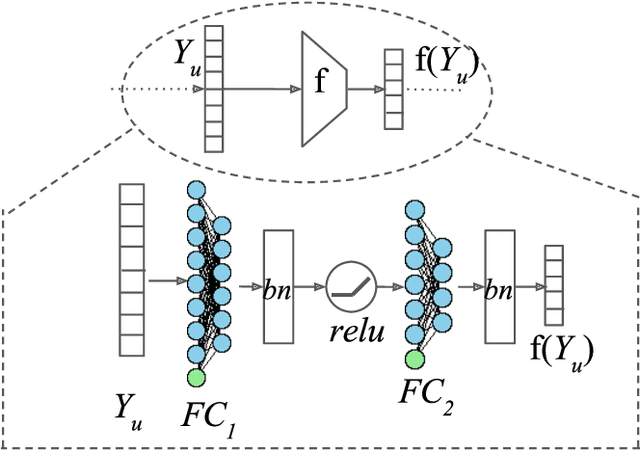
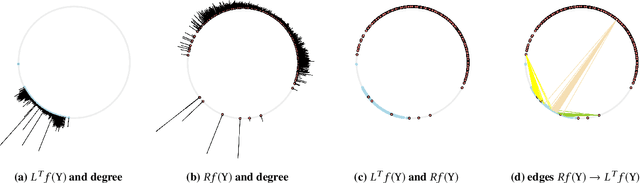
We propose a new method for embedding graphs while preserving directed edge information. Learning such continuous-space vector representations (or embeddings) of nodes in a graph is an important first step for using network information (from social networks, user-item graphs, knowledge bases, etc.) in many machine learning tasks. Unlike previous work, we (1) explicitly model an edge as a function of node embeddings, and we (2) propose a novel objective, the "graph likelihood", which contrasts information from sampled random walks with non-existent edges. Individually, both of these contributions improve the learned representations, especially when there are memory constraints on the total size of the embeddings. When combined, our contributions enable us to significantly improve the state-of-the-art by learning more concise representations that better preserve the graph structure. We evaluate our method on a variety of link-prediction task including social networks, collaboration networks, and protein interactions, showing that our proposed method learn representations with error reductions of up to 76% and 55%, on directed and undirected graphs. In addition, we show that the representations learned by our method are quite space efficient, producing embeddings which have higher structure-preserving accuracy but are 10 times smaller.
Proportionate gradient updates with PercentDelta
Aug 24, 2017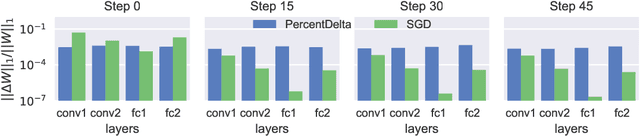
Deep Neural Networks are generally trained using iterative gradient updates. Magnitudes of gradients are affected by many factors, including choice of activation functions and initialization. More importantly, gradient magnitudes can greatly differ across layers, with some layers receiving much smaller gradients than others. causing some layers to train slower than others and therefore slowing down the overall convergence. We analytically explain this disproportionality. Then we propose to explicitly train all layers at the same speed, by scaling the gradient w.r.t. every trainable tensor to be proportional to its current value. In particular, at every batch, we want to update all trainable tensors, such that the relative change of the L1-norm of the tensors is the same, across all layers of the network, throughout training time. Experiments on MNIST show that our method appropriately scales gradients, such that the relative change in trainable tensors is approximately equal across layers. In addition, measuring the test accuracy with training time, shows that our method trains faster than other methods, giving higher test accuracy given same budget of training steps.
YouTube-8M: A Large-Scale Video Classification Benchmark
Sep 27, 2016
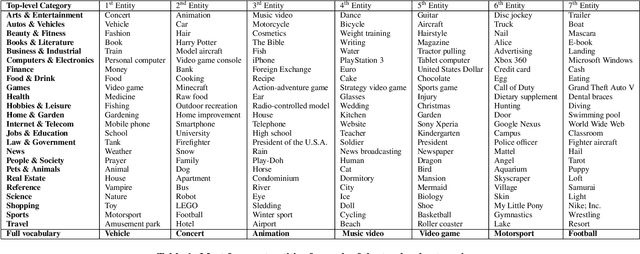
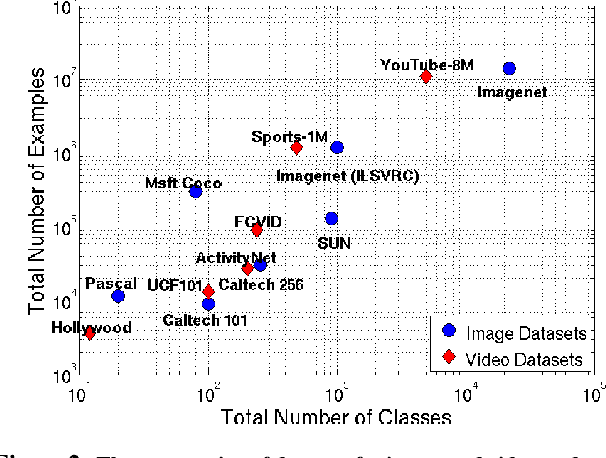

Many recent advancements in Computer Vision are attributed to large datasets. Open-source software packages for Machine Learning and inexpensive commodity hardware have reduced the barrier of entry for exploring novel approaches at scale. It is possible to train models over millions of examples within a few days. Although large-scale datasets exist for image understanding, such as ImageNet, there are no comparable size video classification datasets. In this paper, we introduce YouTube-8M, the largest multi-label video classification dataset, composed of ~8 million videos (500K hours of video), annotated with a vocabulary of 4800 visual entities. To get the videos and their labels, we used a YouTube video annotation system, which labels videos with their main topics. While the labels are machine-generated, they have high-precision and are derived from a variety of human-based signals including metadata and query click signals. We filtered the video labels (Knowledge Graph entities) using both automated and manual curation strategies, including asking human raters if the labels are visually recognizable. Then, we decoded each video at one-frame-per-second, and used a Deep CNN pre-trained on ImageNet to extract the hidden representation immediately prior to the classification layer. Finally, we compressed the frame features and make both the features and video-level labels available for download. We trained various (modest) classification models on the dataset, evaluated them using popular evaluation metrics, and report them as baselines. Despite the size of the dataset, some of our models train to convergence in less than a day on a single machine using TensorFlow. We plan to release code for training a TensorFlow model and for computing metrics.