 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Neural Network Predictions on Sentence Pairs via Learning Word-Group Masks
Apr 13, 2021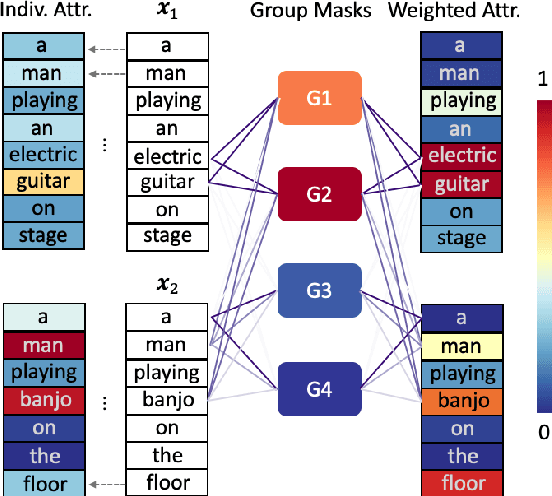
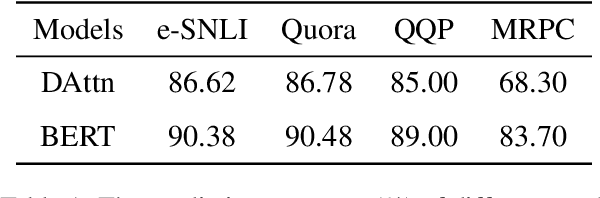
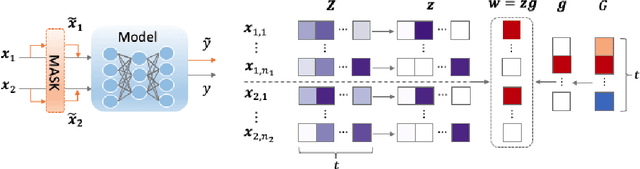
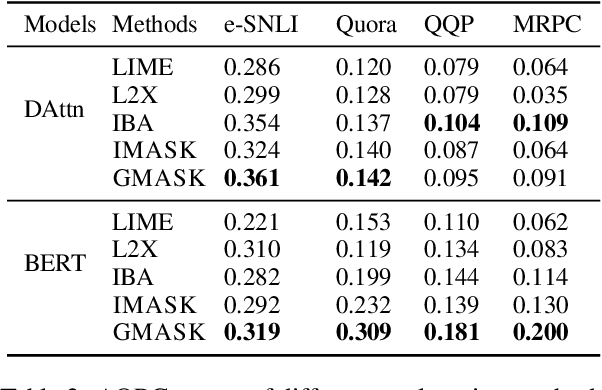
Explaining neural network models is important for increasing their trustworthiness in real-world applications. Most existing methods generate post-hoc explanations for neural network models by identifying individual feature attributions or detecting interactions between adjacent features. However, for models with text pairs as inputs (e.g., paraphrase identification), existing methods are not sufficient to capture feature interactions between two texts and their simple extension of computing all word-pair interactions between two texts is computationally inefficient. In this work, we propose the Group Mask (GMASK) method to implicitly detect word correlations by grouping correlated words from the input text pair together and measure their contribution to the corresponding NLP tasks as a whole. The proposed method is evaluated with two different model architectures (decomposable attention model and BERT) across four datasets, including natural language inference and paraphrase identification tasks. Experiments show the effectiveness of GMASK in providing faithful explanations to these models.
Does Dialog Length matter for Next Response Selection task? An Empirical Study
Jan 24, 2021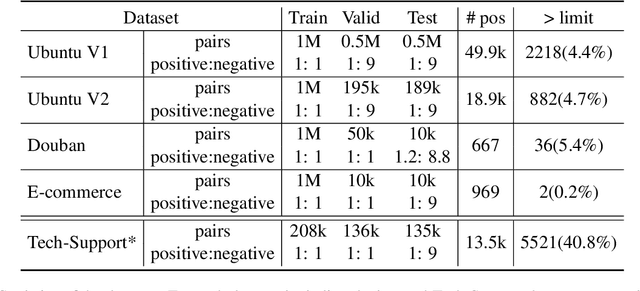
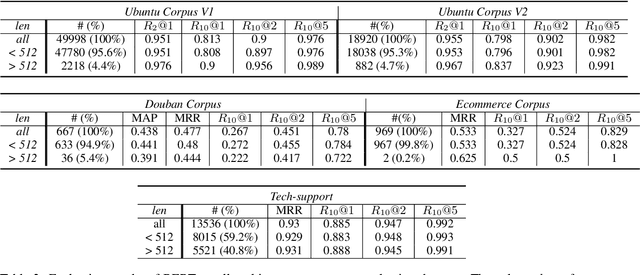
In the last few years, the release of BERT, a multilingual transformer based model, has taken the NLP community by storm. BERT-based models have achieved state-of-the-art results on various NLP tasks, including dialog tasks. One of the limitation of BERT is the lack of ability to handle long text sequence. By default, BERT has a maximum wordpiece token sequence length of 512. Recently, there has been renewed interest to tackle the BERT limitation to handle long text sequences with the addition of new self-attention based architectures. However, there has been little to no research on the impact of this limitation with respect to dialog tasks. Dialog tasks are inherently different from other NLP tasks due to: a) the presence of multiple utterances from multiple speakers, which may be interlinked to each other across different turns and b) longer length of dialogs. In this work, we empirically evaluate the impact of dialog length on the performance of BERT model for the Next Response Selection dialog task on four publicly available and one internal multi-turn dialog datasets. We observe that there is little impact on performance with long dialogs and even the simplest approach of truncating input works really well.
doc2dial: A Goal-Oriented Document-Grounded Dialogue Dataset
Nov 18, 2020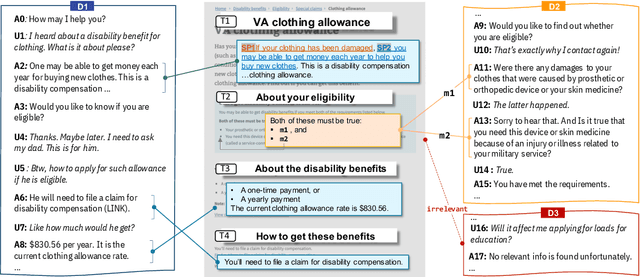
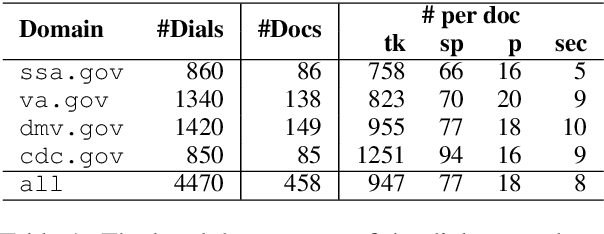
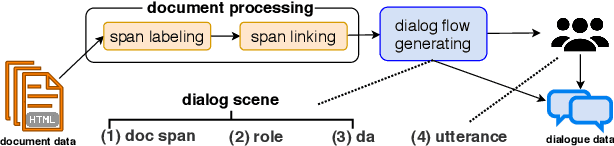
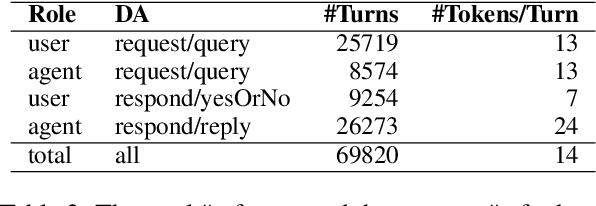
We introduce doc2dial, a new dataset of goal-oriented dialogues that are grounded in the associated documents. Inspired by how the authors compose documents for guiding end users, we first construct dialogue flows based on the content elements that corresponds to higher-level relations across text sections as well as lower-level relations between discourse units within a section. Then we present these dialogue flows to crowd contributors to create conversational utterances. The dataset includes about 4800 annotated conversations with an average of 14 turns that are grounded in over 480 documents from four domains. Compared to the prior document-grounded dialogue datasets, this dataset covers a variety of dialogue scenes in information-seeking conversations. For evaluating the versatility of the dataset, we introduce multiple dialogue modeling tasks and present baseline approaches.
Simulated Chats for Task-oriented Dialog: Learning to Generate Conversations from Instructions
Oct 20, 2020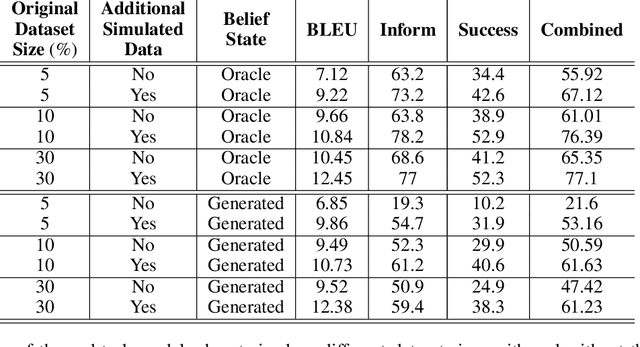
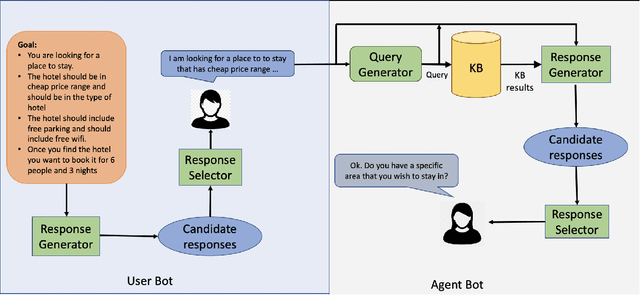
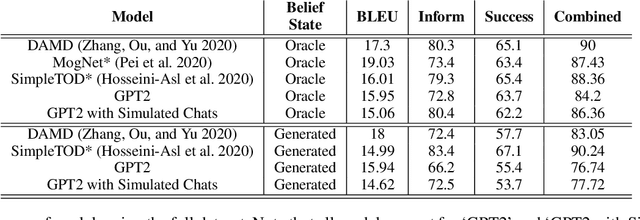

Popular task-oriented dialog data sets such as MultiWOZ (Budzianowski et al. 2018) are created by providing crowd-sourced workers a goal instruction, expressed in natural language, that describes the task to be accomplished. Crowd-sourced workers play the role of a user and an agent to generate dialogs to accomplish tasks involving booking restaurant tables, making train reservations, calling a taxi etc. However, creating large crowd-sourced datasets can be time consuming and expensive. To reduce the cost associated with generating such dialog datasets, recent work has explored methods to automatically create larger datasets from small samples.In this paper, we present a data creation strategy that uses the pre-trained language model, GPT2 (Radford et al. 2018), to simulate the interaction between crowd-sourced workers by creating a user bot and an agent bot. We train the simulators using a smaller percentage of actual crowd-generated conversations and their corresponding goal instructions. We demonstrate that by using the simulated data, we achieve significant improvements in both low-resource setting as well as in over-all task performance. To the best of our knowledge we are the first to present a model for generating entire conversations by simulating the crowd-sourced data collection process
Conversational Document Prediction to Assist Customer Care Agents
Oct 05, 2020
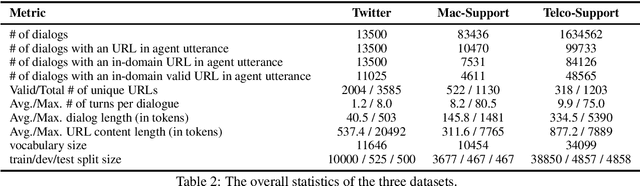

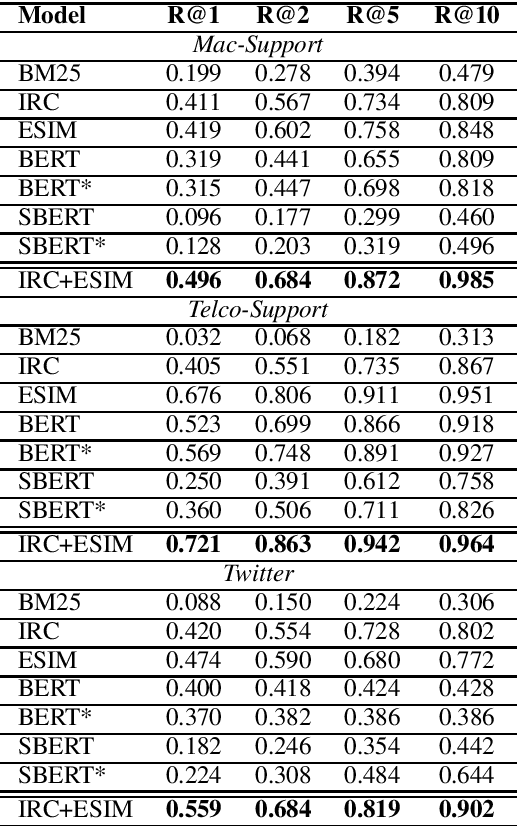
A frequent pattern in customer care conversations is the agents responding with appropriate webpage URLs that address users' needs. We study the task of predicting the documents that customer care agents can use to facilitate users' needs. We also introduce a new public dataset which supports the aforementioned problem. Using this dataset and two others, we investigate state-of-the art deep learning (DL) and information retrieval (IR) models for the task. Additionally, we analyze the practicality of such systems in terms of inference time complexity. Our show that an hybrid IR+DL approach provides the best of both worlds.
Effects of Naturalistic Variation in Goal-Oriented Dialog
Oct 05, 2020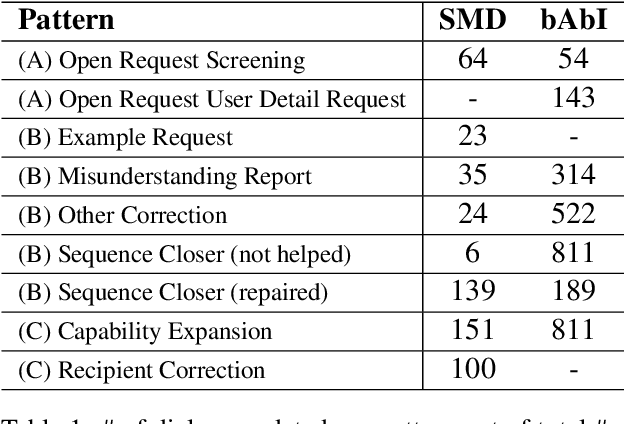
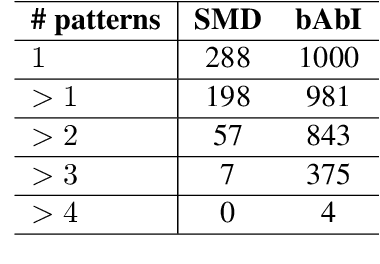
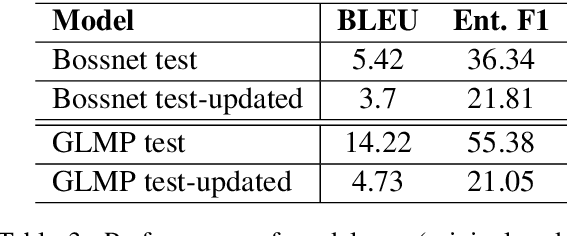
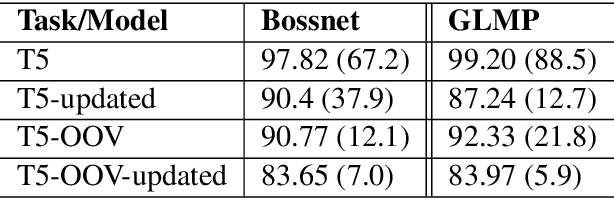
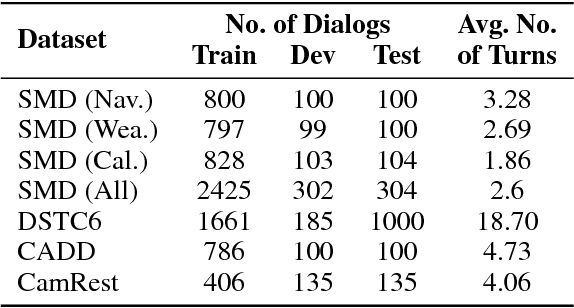
Existing benchmarks used to evaluate the performance of end-to-end neural dialog systems lack a key component: natural variation present in human conversations. Most datasets are constructed through crowdsourcing, where the crowd workers follow a fixed template of instructions while enacting the role of a user/agent. This results in straight-forward, somewhat routine, and mostly trouble-free conversations, as crowd workers do not think to represent the full range of actions that occur naturally with real users. In this work, we investigate the impact of naturalistic variation on two goal-oriented datasets: bAbI dialog task and Stanford Multi-Domain Dataset (SMD). We also propose new and more effective testbeds for both datasets, by introducing naturalistic variation by the user. We observe that there is a significant drop in performance (more than 60% in Ent. F1 on SMD and 85% in per-dialog accuracy on bAbI task) of recent state-of-the-art end-to-end neural methods such as BossNet and GLMP on both datasets.
Mask & Focus: Conversation Modelling by Learning Concepts
Feb 11, 2020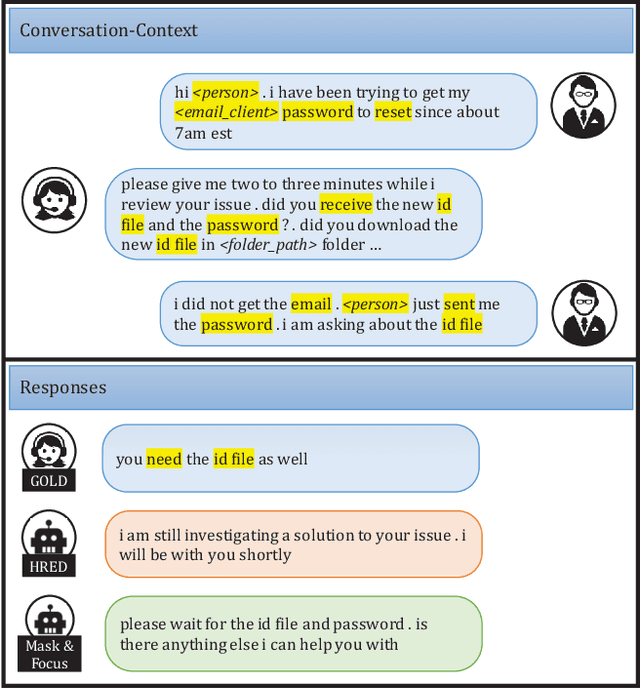
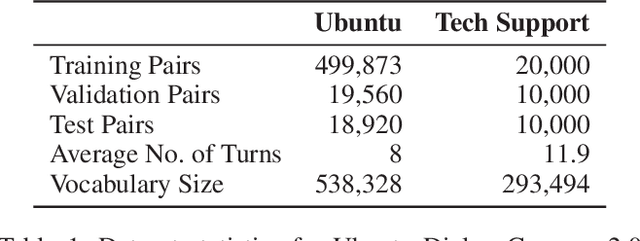
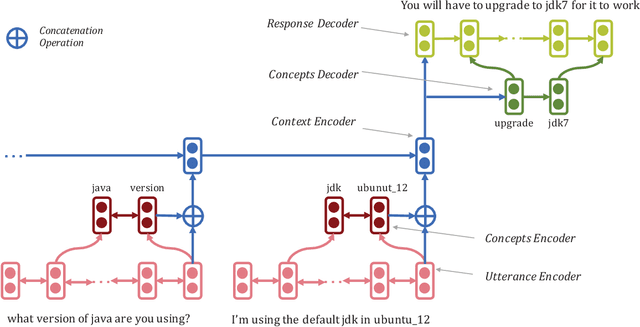
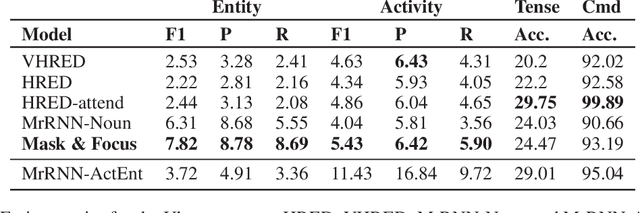
Sequence to sequence models attempt to capture the correlation between all the words in the input and output sequences. While this is quite useful for machine translation where the correlation among the words is indeed quite strong, it becomes problematic for conversation modelling where the correlation is often at a much abstract level. In contrast, humans tend to focus on the essential concepts discussed in the conversation context and generate responses accordingly. In this paper, we attempt to mimic this response generating mechanism by learning the essential concepts in the context and response in an unsupervised manner. The proposed model, referred to as Mask \& Focus maps the input context to a sequence of concepts which are then used to generate the response concepts. Together, the context and the response concepts generate the final response. In order to learn context concepts from the training data automatically, we \emph{mask} words in the input and observe the effect of masking on response generation. We train our model to learn those response concepts that have high mutual information with respect to the context concepts, thereby guiding the model to \emph{focus} on the context concepts. Mask \& Focus achieves significant improvement over the existing baselines in several established metrics for dialogues.
Neural Conversational QA: Learning to Reason v.s. Exploiting Patterns
Sep 09, 2019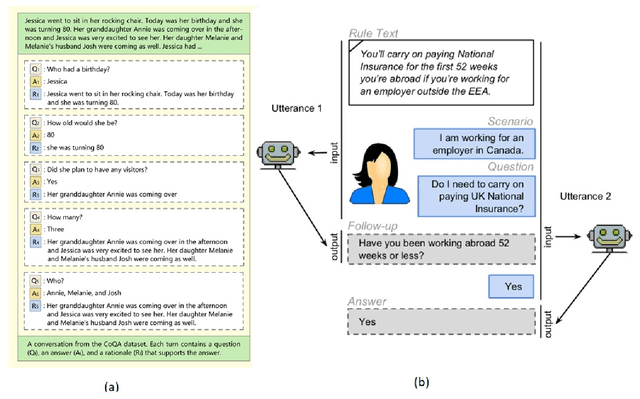

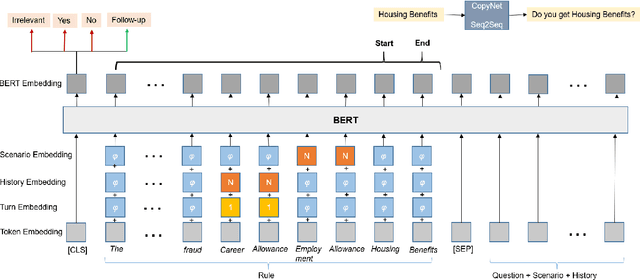
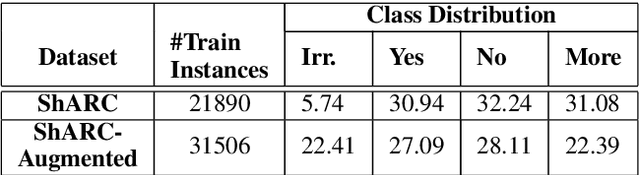
In this paper we work on the recently introduced ShARC task - a challenging form of conversational QA that requires reasoning over rules expressed in natural language. Attuned to the risk of superficial patterns in data being exploited by neural models to do well on benchmark tasks (Niven and Kao 2019), we conduct a series of probing experiments and demonstrate how current state-of-the-art models rely heavily on such patterns. To prevent models from learning based on the superficial clues, we modify the dataset by automatically generating new instances reducing the occurrences of those patterns. We also present a simple yet effective model that learns embedding representations to incorporate dialog history along with the previous answers to follow-up questions. We find that our model outperforms existing methods on all metrics, and the results show that the proposed model is more robust in dealing with spurious patterns and learns to reason meaningfully.
Unsupervised Learning of Interpretable Dialog Models
Nov 02, 2018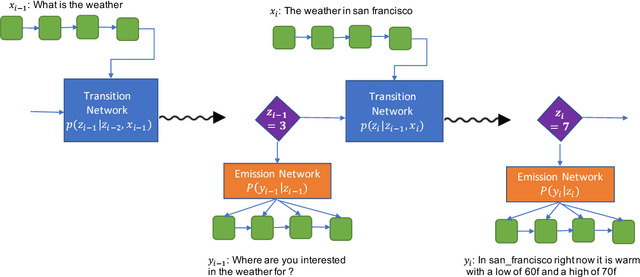
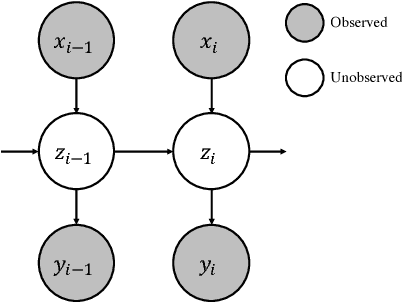
Recently several deep learning based models have been proposed for end-to-end learning of dialogs. While these models can be trained from data without the need for any additional annotations, it is hard to interpret them. On the other hand, there exist traditional state based dialog systems, where the states of the dialog are discrete and hence easy to interpret. However these states need to be handcrafted and annotated in the data. To achieve the best of both worlds, we propose Latent State Tracking Network (LSTN) using which we learn an interpretable model in unsupervised manner. The model defines a discrete latent variable at each turn of the conversation which can take a finite set of values. Since these discrete variables are not present in the training data, we use EM algorithm to train our model in unsupervised manner. In the experiments, we show that LSTN can help achieve interpretability in dialog models without much decrease in performance compared to end-to-end approaches.
Multi-level Memory for Task Oriented Dialogs
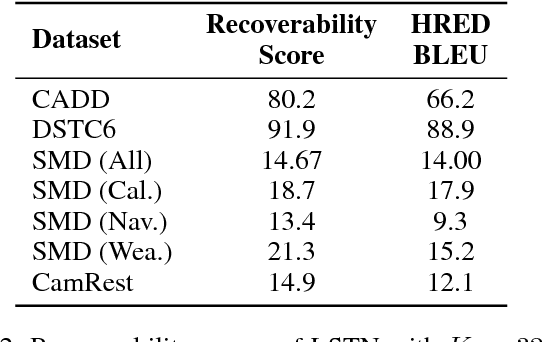
Oct 24, 2018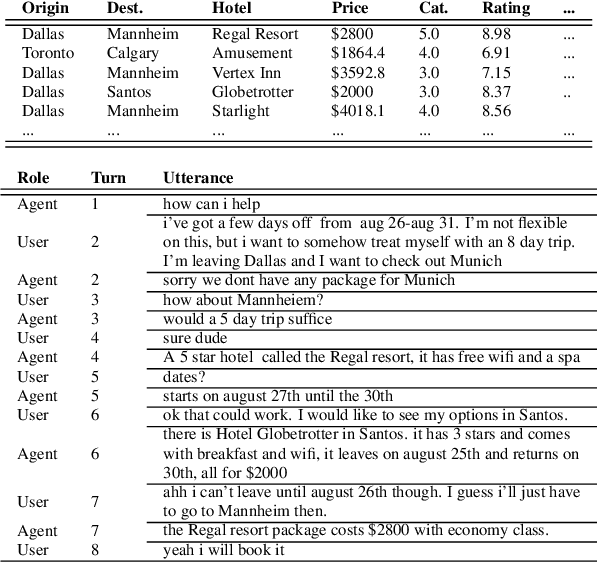
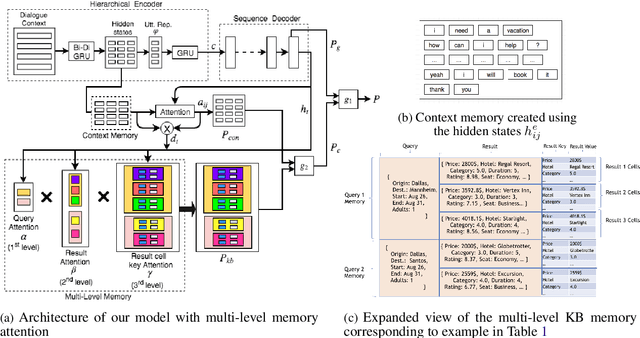

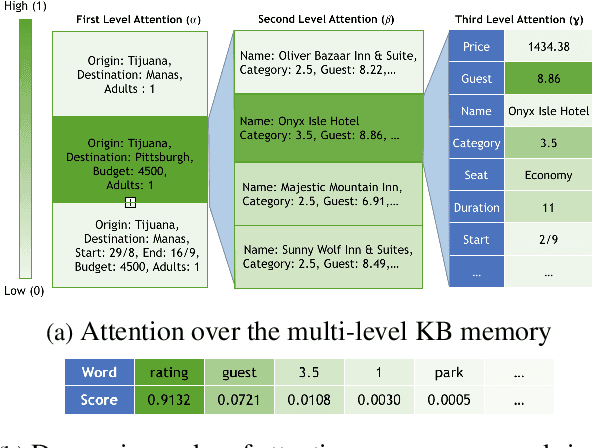
Recent end-to-end task oriented dialog systems use memory architectures to incorporate external knowledge in their dialogs. Current work makes simplifying assumptions about the structure of the knowledge base, such as the use of triples to represent knowledge, and combines dialog utterances (context) as well as knowledge base (KB) results as part of the same memory. This causes an explosion in the memory size, and makes the reasoning over memory harder. In addition, such a memory design forces hierarchical properties of the data to be fit into a triple structure of memory. This requires the memory reader to infer relationships across otherwise connected attributes. In this paper we relax the strong assumptions made by existing architectures and separate memories used for modeling dialog context and KB results. Instead of using triples to store KB results, we introduce a novel multi-level memory architecture consisting of cells for each query and their corresponding results. The multi-level memory first addresses queries, followed by results and finally each key-value pair within a result. We conduct detailed experiments on three publicly available task oriented dialog data sets and we find that our method conclusively outperforms current state-of-the-art models. We report a 15-25% increase in both entity F1 and BLEU scores.