 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtually Being: Customizing Camera-Controllable Video Diffusion Models with Multi-View Performance Captures
Oct 16, 2025We introduce a framework that enables both multi-view character consistency and 3D camera control in video diffusion models through a novel customization data pipeline. We train the character consistency component with recorded volumetric capture performances re-rendered with diverse camera trajectories via 4D Gaussian Splatting (4DGS), lighting variability obtained with a video relighting model. We fine-tune state-of-the-art open-source video diffusion models on this data to provide strong multi-view identity preservation, precise camera control, and lighting adaptability. Our framework also supports core capabilities for virtual production, including multi-subject generation using two approaches: joint training and noise blending, the latter enabling efficient composition of independently customized models at inference time; it also achieves scene and real-life video customization as well as control over motion and spatial layout during customization. Extensive experiments show improved video quality, higher personalization accuracy, and enhanced camera control and lighting adaptability, advancing the integration of video generation into virtual production. Our project page is available at: https://eyeline-labs.github.io/Virtually-Being.
Go-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise
Jan 16, 2025



Generative modeling aims to transform random noise into structured outputs. In this work, we enhance video diffusion models by allowing motion control via structured latent noise sampling. This is achieved by just a change in data: we pre-process training videos to yield structured noise. Consequently, our method is agnostic to diffusion model design, requiring no changes to model architectures or training pipelines. Specifically, we propose a novel noise warping algorithm, fast enough to run in real time, that replaces random temporal Gaussianity with correlated warped noise derived from optical flow fields, while preserving the spatial Gaussianity. The efficiency of our algorithm enables us to fine-tune modern video diffusion base models using warped noise with minimal overhead, and provide a one-stop solution for a wide range of user-friendly motion control: local object motion control, global camera movement control, and motion transfer. The harmonization between temporal coherence and spatial Gaussianity in our warped noise leads to effective motion control while maintaining per-frame pixel quality. Extensive experiments and user studies demonstrate the advantages of our method, making it a robust and scalable approach for controlling motion in video diffusion models. Video results are available on our webpage: https://vgenai-netflix-eyeline-research.github.io/Go-with-the-Flow. Source code and model checkpoints are available on GitHub: https://github.com/VGenAI-Netflix-Eyeline-Research/Go-with-the-Flow.
Infinite-Resolution Integral Noise Warping for Diffusion Models
Nov 02, 2024Adapting pretrained image-based diffusion models to generate temporally consistent videos has become an impactful generative modeling research direction. Training-free noise-space manipulation has proven to be an effective technique, where the challenge is to preserve the Gaussian white noise distribution while adding in temporal consistency. Recently, Chang et al. (2024) formulated this problem using an integral noise representation with distribution-preserving guarantees, and proposed an upsampling-based algorithm to compute it. However, while their mathematical formulation is advantageous, the algorithm incurs a high computational cost. Through analyzing the limiting-case behavior of their algorithm as the upsampling resolution goes to infinity, we develop an alternative algorithm that, by gathering increments of multiple Brownian bridges, achieves their infinite-resolution accuracy while simultaneously reducing the computational cost by orders of magnitude. We prove and experimentally validate our theoretical claims, and demonstrate our method's effectiveness in real-world applications. We further show that our method readily extends to the 3-dimensional space.
DifFRelight: Diffusion-Based Facial Performance Relighting
Oct 10, 2024



We present a novel framework for free-viewpoint facial performance relighting using diffusion-based image-to-image translation. Leveraging a subject-specific dataset containing diverse facial expressions captured under various lighting conditions, including flat-lit and one-light-at-a-time (OLAT) scenarios, we train a diffusion model for precise lighting control, enabling high-fidelity relit facial images from flat-lit inputs. Our framework includes spatially-aligned conditioning of flat-lit captures and random noise, along with integrated lighting information for global control, utilizing prior knowledge from the pre-trained Stable Diffusion model. This model is then applied to dynamic facial performances captured in a consistent flat-lit environment and reconstructed for novel-view synthesis using a scalable dynamic 3D Gaussian Splatting method to maintain quality and consistency in the relit results. In addition, we introduce unified lighting control by integrating a novel area lighting representation with directional lighting, allowing for joint adjustments in light size and direction. We also enable high dynamic range imaging (HDRI) composition using multiple directional lights to produce dynamic sequences under complex lighting conditions. Our evaluations demonstrate the models efficiency in achieving precise lighting control and generalizing across various facial expressions while preserving detailed features such as skintexture andhair. The model accurately reproduces complex lighting effects like eye reflections, subsurface scattering, self-shadowing, and translucency, advancing photorealism within our framework.
LLaRA: Supercharging Robot Learning Data for Vision-Language Policy
Jun 28, 2024



Large Language Models (LLMs) equipped with extensive world knowledge and strong reasoning skills can tackle diverse tasks across domains, often by posing them as conversation-style instruction-response pairs. In this paper, we propose LLaRA: Large Language and Robotics Assistant, a framework which formulates robot action policy as conversations, and provides improved responses when trained with auxiliary data that complements policy learning. LLMs with visual inputs, i.e., Vision Language Models (VLMs), have the capacity to process state information as visual-textual prompts and generate optimal policy decisions in text. To train such action policy VLMs, we first introduce an automated pipeline to generate diverse high-quality robotics instruction data from existing behavior cloning data. A VLM finetuned with the resulting collection of datasets based on a conversation-style formulation tailored for robotics tasks, can generate meaningful robot action policy decisions. Our experiments across multiple simulated and real-world environments demonstrate the state-of-the-art performance of the proposed LLaRA framework. The code, datasets, and pretrained models are available at https://github.com/LostXine/LLaRA.
Diffusion Illusions: Hiding Images in Plain Sight
Dec 06, 2023



We explore the problem of computationally generating special `prime' images that produce optical illusions when physically arranged and viewed in a certain way. First, we propose a formal definition for this problem. Next, we introduce Diffusion Illusions, the first comprehensive pipeline designed to automatically generate a wide range of these illusions. Specifically, we both adapt the existing `score distillation loss' and propose a new `dream target loss' to optimize a group of differentially parametrized prime images, using a frozen text-to-image diffusion model. We study three types of illusions, each where the prime images are arranged in different ways and optimized using the aforementioned losses such that images derived from them align with user-chosen text prompts or images. We conduct comprehensive experiments on these illusions and verify the effectiveness of our proposed method qualitatively and quantitatively. Additionally, we showcase the successful physical fabrication of our illusions -- as they are all designed to work in the real world. Our code and examples are publicly available at our interactive project website: https://diffusionillusions.com
Peekaboo: Text to Image Diffusion Models are Zero-Shot Segmentors
Nov 23, 2022



Recent diffusion-based generative models combined with vision-language models are capable of creating realistic images from natural language prompts. While these models are trained on large internet-scale datasets, such pre-trained models are not directly introduced to any semantic localization or grounding. Most current approaches for localization or grounding rely on human-annotated localization information in the form of bounding boxes or segmentation masks. The exceptions are a few unsupervised methods that utilize architectures or loss functions geared towards localization, but they need to be trained separately. In this work, we explore how off-the-shelf diffusion models, trained with no exposure to such localization information, are capable of grounding various semantic phrases with no segmentation-specific re-training. An inference time optimization process is introduced, that is capable of generating segmentation masks conditioned on natural language. We evaluate our proposal Peekaboo for unsupervised semantic segmentation on the Pascal VOC dataset. In addition, we evaluate for referring segmentation on the RefCOCO dataset. In summary, we present a first zero-shot, open-vocabulary, unsupervised (no localization information), semantic grounding technique leveraging diffusion-based generative models with no re-training. Our code will be released publicly.
Neural Neural Textures Make Sim2Real Consistent
Jun 27, 2022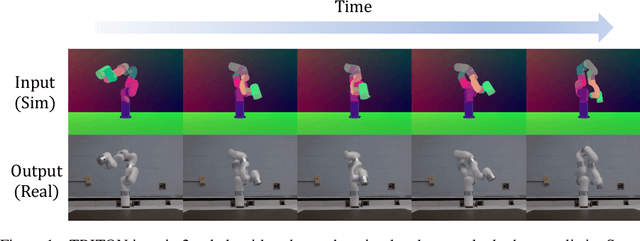
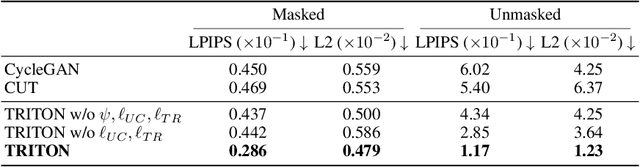


Unpaired image translation algorithms can be used for sim2real tasks, but many fail to generate temporally consistent results. We present a new approach that combines differentiable rendering with image translation to achieve temporal consistency over indefinite timescales, using surface consistency losses and \emph{neural neural textures}. We call this algorithm TRITON (Texture Recovering Image Translation Network): an unsupervised, end-to-end, stateless sim2real algorithm that leverages the underlying 3D geometry of input scenes by generating realistic-looking learnable neural textures. By settling on a particular texture for the objects in a scene, we ensure consistency between frames statelessly. Unlike previous algorithms, TRITON is not limited to camera movements -- it can handle the movement of objects as well, making it useful for downstream tasks such as robotic manipulation.